
Se você busca flexibilidade e alguma versatilidade para escolher entre estratégias de deployment e distribuição de aplicações a qualquer momento do ciclo de vida do projeto. Desde o dia 1 até a véspera de uma implantação. Ou se você não está certo, mas quer poder trocar uma chamada HTTP por uma mensagem AMQP, ou gRPC facilmente, independente do momento. Esse post é pra você.
Muitas vezes me deparo com Controllers, Handlers e diversos Primary Adapters interagindo diretamente com DbContexts (EF), ISessions (NH), ou até mesmo acessando repositórios e pedindo entidades, além de manipulá-las.
Pela ótica do Ports and Adapters, será que isso está certo?
Será que não vamos produzir serviços burros com essa abordagem?
Será que isso tem algum valor?
A primeira vez que vi um serviço 100% agnóstico, eu já detalhei no post anterior sobre Agnostic Services. O primeiro foi o projeto Spring.Calculator, mas não levou muito tempo para surgir o Spring.WcfQuickStart, quando WCF chegou.
Isso era por volta de 2007.
O mais interessante do desenho é ver como, com apenas um serviço, que não tinha dependência absolutamente alguma de Web, de Enterprise Services, de Remoting, de RabbitMQ ainda assim ser exposto nesses protocolos.
WCF chegou mais tarde nessa brincadeira, mas trouxe consigo a necessidade de criar marcações em todo o contrato.
O caso do Spring não vem ao caso hoje, mas os conceitos continuam extremamente atuais.
O fato é que a escolha pelo transporte, por aquela perspectiva era apenas uma decisão de configuração! HTTP, AMQP ou diversos outros tipos de transporte, eram decididos pela infraestrutura. Nesse desenho você não precisa programar 2 serviços diferentes, um para cada protocolo.
Eu voltando nesse assunto porque hoje, 15 anos depois, isso ainda parece taboo.
Ports and Adapters
O pattern Ports and Adaptes vai te empurrar para a adoção de serviços agnósticos. Isso porque segundo essa visão, o design do domínio é influenciado de tal forma que temos como resultado um core puro.
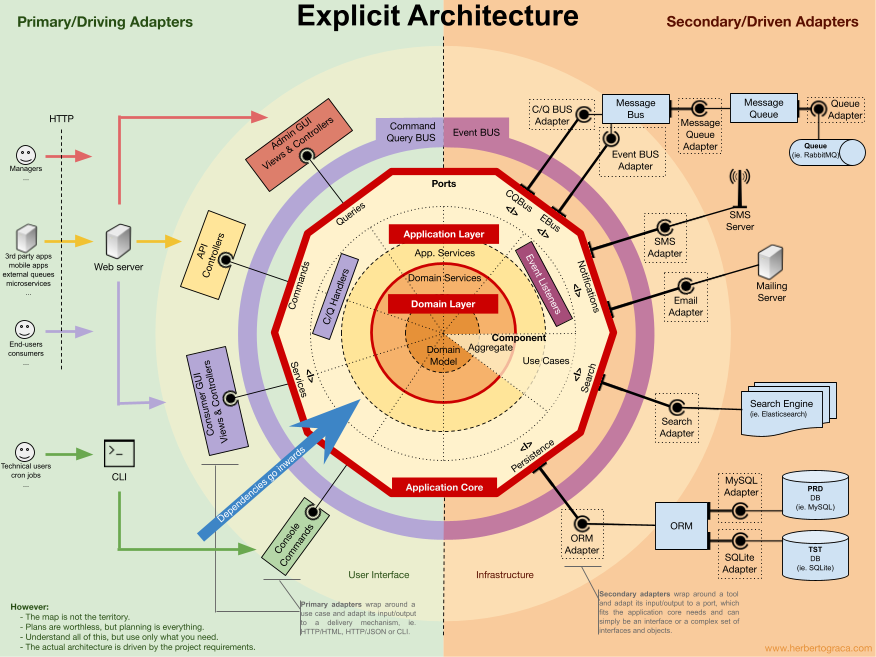
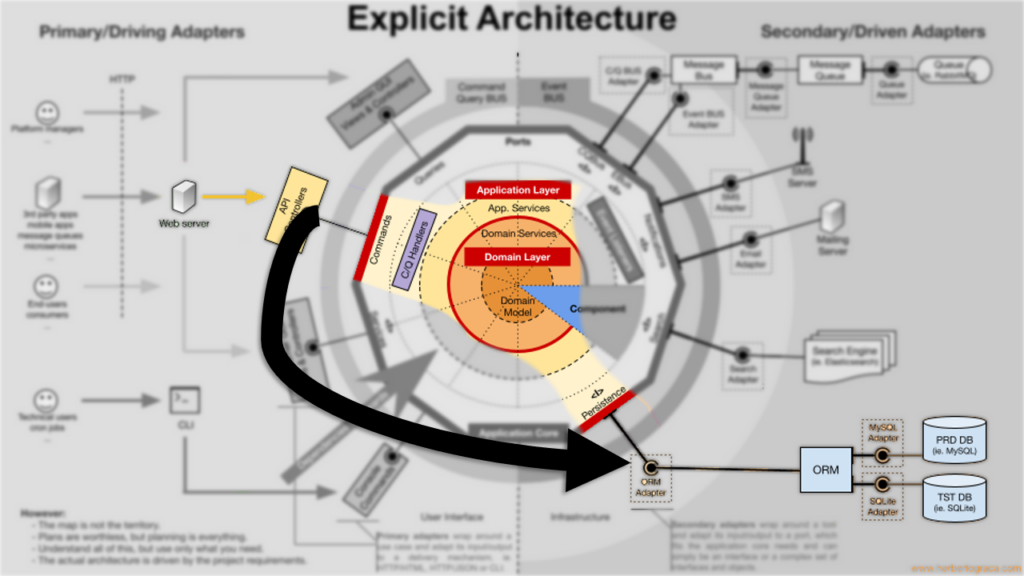
O desenho acima, do Herberto Graça, amplamente difundido na internet, está de certa forma contaminado com as influências do DDD. Então para entendermos melhor Ports and Adapters temos de voltar a desenhos não tão sofisticados, no entanto mais precisos e sem ruído, do autor original.
A fonte é o Alistair Cockburn e a imagem é essa abaixo:
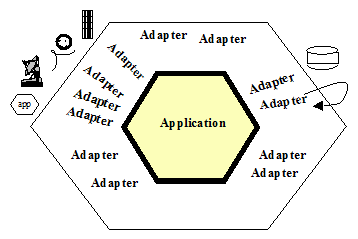
Embora mais rudimentar, ele nos dá uma visão mais clara dos interesses do Ports and Adapters.
Se pudéssemos simplificar, seria algo como ter um core agnóstico, puro, independente de tecnologias específicas para problemas específicos. Esse core não tem dependência de nenhuma tecnologia (HTTP, AMQP, Banco, ORM, Email… nada). Esse core só orquestra as atividades de negócio. Ele provê interfaces puras que serão implementadas por adapters. De forma com que toda comunicação que precise orquestrar adapters passe por esse core, sem que o core se suje com detalhes de implementação das tecnologias, sem que esse core toque nenhuma tecnologia diretamente, fazendo isso por meio dos adapters. Servindo exatamente de hub, de broker, de mediador, e orquestrador que costura as necessidades do sistema.
Isso se traduz em um core puro, que tenha somente negócio, distante de todo o lixo produzido pela mescla entre código de negócio e código tecnológico.
Segundo Alistair:
[original en-us] Both the user-side and the server-side problems actually are caused by the same error in design and programming — the entanglement between the business logic and the interaction with external entities. The asymmetry to exploit is not that between ‘’left’’ and ‘’right’’ sides of the application but between ‘’inside’’ and ‘’outside’’ of the application. The rule to obey is that code pertaining to the ‘’inside’’ part should not leak into the ‘’outside’’ part.
[tradução livre] Tanto os problemas do lado do usuário quanto do lado do servidor são causados pelo mesmo erro de design e programação — o emaranhamento entre a lógica de negócios e a interação com entidades externas. A assimetria a explorar não é aquela entre os lados ”esquerdo” e ”direito” da aplicação, mas entre ”dentro” e ”fora” da aplicação. A regra a obedecer é que o código referente à parte “interna” não deve vazar para a parte “externa”.
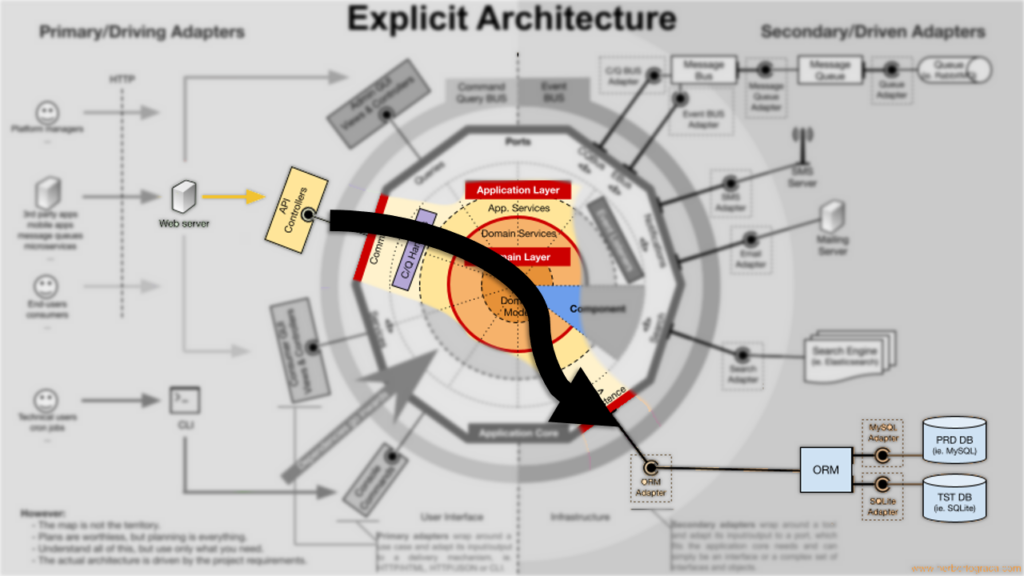
Ainda podemos entender isso melhor com a imagem abaixo:
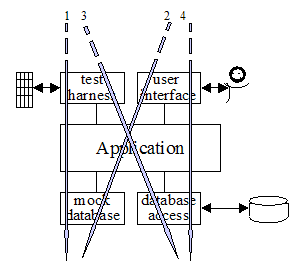
Eu aqui sinto vergonha alheia a respeito da discrepância entre o preciosismo na criação das imagens/artes pelo Herberto em comparação com a simplicidade das imagens do Cockburn, mesmo assim Cockburn é a fonte dessa ideia.
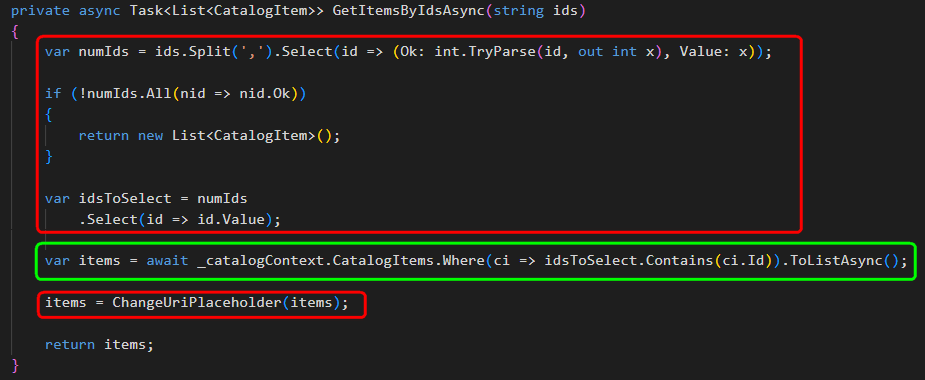
O principal ponto que quero trazer é que coisas como essa aqui abaixo, onde um handler (específico de uma implementação baseada em mediator), pela perspectiva de Ports and Adapters, não deveria tocar no repositório, não deveria tocar na Order.
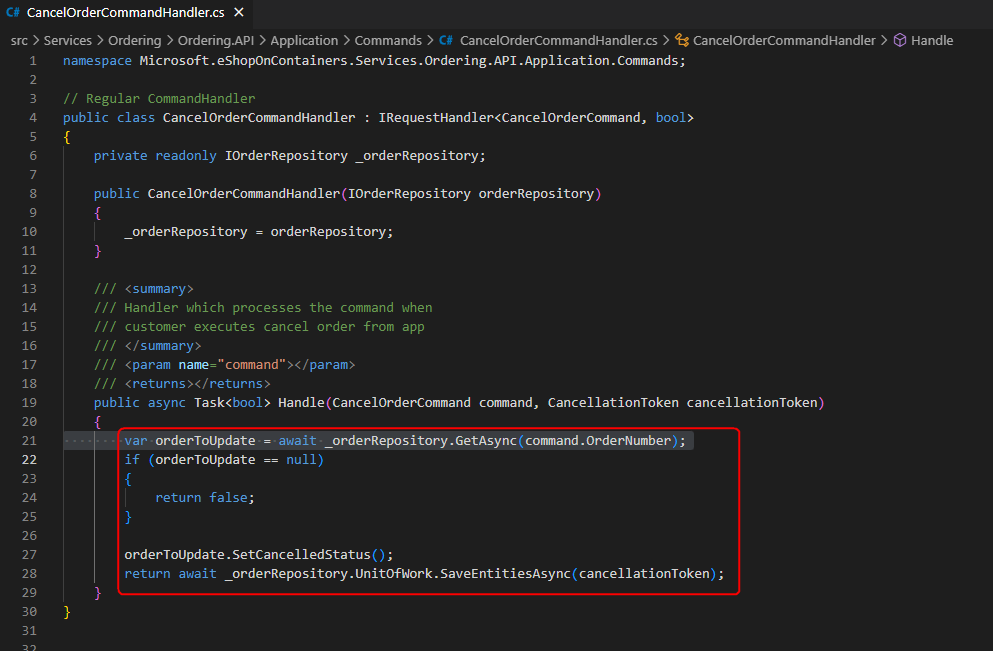
Pela perspectiva do Ports and Adapters, o Command handler é um adapter, e deveria repassar a mensagem para um Application Service. Chamadas ao repositório, ao método SetCancelledStatus() e SaveEntitiesAsync() deveriam estar nesse Application Service e não no adapter.
Ports And Adapter também mudam a forma como a comunidade está habituada a escrever Web API Controllers e MVC Controllers:
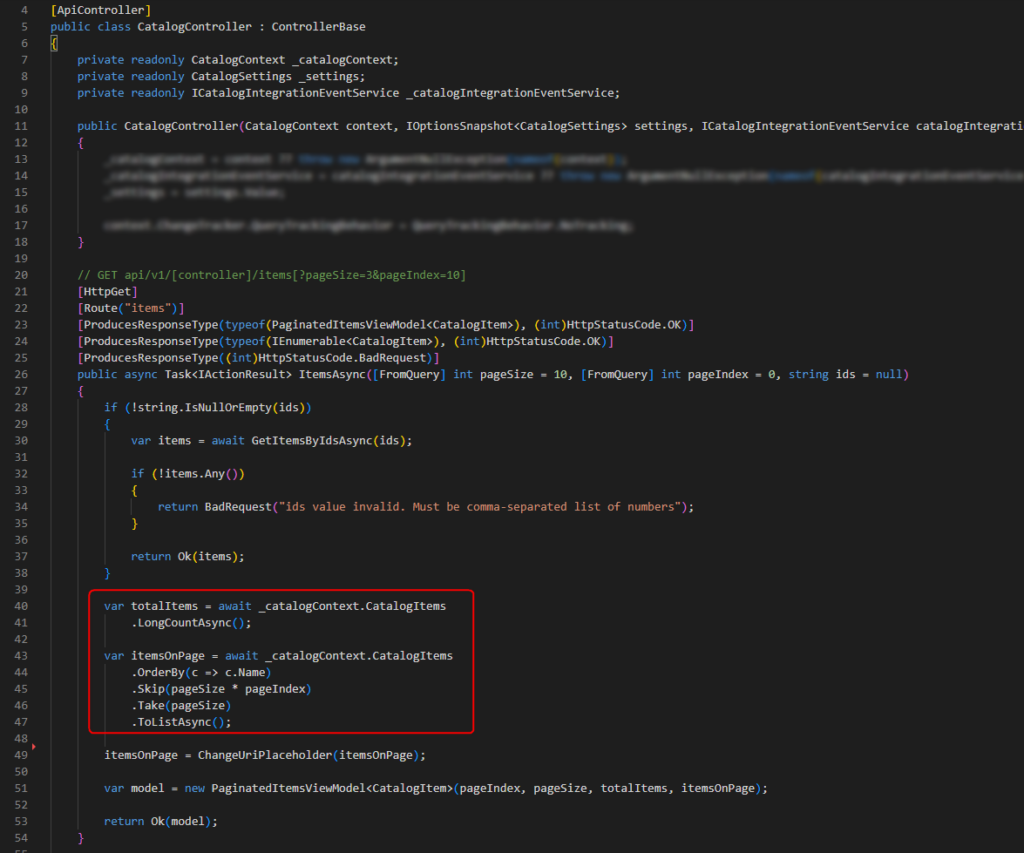
A mudança é que por essa perspectiva, a Controller não deveria tocar no DBContext, nem realizar essas declarações de filtro com Take, Skip, Order, pois essa não seria a responsabilidade da Controller.
Mas uma coisa tem de ficar clara:
Claro que estou dizendo que “não deveria”, sobre a perspectiva do Ports and Adapters (Hexagonal Architecture). Uma arquitetura não adotada nesse projeto. Portanto, beira o injusto conduzir essa comparação, no entanto, utilizei esse projeto porque é um bom ponto de partida, já que esse estilo de desenvolvimento é extremamente comum.
O que eu quero trazer à tona é que quando sua controller acessa direto um DbContext do Entity Framework ou um ISession do NHibernate, ou um repositório diretamente ela está produzido um bypass na camada de aplicação.
Ao escolher uma arquitetura, é abraçar restrições, limitações e até imposições.
Ferir essas exigências reduz ou até, em muitos casos, impede seu projeto de obter o sucesso pretendido. Esse é o preço que se paga para “fazer parte do clubinho”.
Olhar pela perspectiva do Ports and Adapters nos levará ao entendimento de que é um claro vazamento de responsabilidade:
- No primeiro exemplo:
- Uma segunda implementação que precisasse setar o estado da Order como cancelada, deveria reimplementar toda essa lógica (obter a entidade do repositório, chamar o método, salvar).
- A versão Hexagonal, poderia ter o handler com 1 linha, adaptando a chamada ao service. E no service esse exato código que vimos acima executaria a operação.
- No segundo exemplo:
- a Controller tem acesso ao DbContext.
- a Controller realiza as expressões lambda que são passadas ao DbContext.
E não estamos questionando a existência do código, mas sim questionando onde esse código está! Em qual artefato esse código foi ou será escrito.
O que deveria ser feito?
Vou me ater aqui à visão Hexagonal da coisa, portanto tendenciosa, portanto diferente da arquitetura proposta pelo eShopOnContainers, mas ainda assim um bom ponto de contraste.
Primeiro devemos pensar que o core da aplicação existe de forma agnóstica. Ou seja, o core não tem conhecimento sobre nenhum aspecto não funcional como contexto HTTP, como filas AMQP, Acesso a dados. Isso quer dizer que não pode, nem deve ter sequer a dependência de Web, Frameworks de acesso a dados, AMQP ou nada disso.
Do ponto de vista de OO, esse core cria interfaces, que descrevem Bus, Repositórios e outros adapters. Essas interfaces possuem a semântica do negócio.
A implementação dos adapters está fora do core, enquanto o core tem o papel de costurar PORTS e ADAPTERS de para os entregar os casos de uso ou seja as funcionalidades da aplicação.
Isso quer dizer que não há PORT falando direto com outro adapter, assim há obrigatoriamente o intermédio do core.
Ou seja, a controller não fala com o repositório diretamente, a controller fala com a camada de aplicação que por sua vez fala com o repositório.
Isso acontece porque a responsabilidade de conectar os pontos é exclusivamente do core. É ela quem costura as regras de negócio, e principalmente de forma agnóstica, não dependendo das implementações de cada camada consumida, mas apenas das interfaces que ela mesma define.
Em vez de termos Controllers e Handers falando diretamente com entidades, deveríamos ter, sob a ótica do Hexagonal, Controllers e Handers falando serviços do domínio, em geral Use Case Services, e esses sim falam com as entidades do domínio.
A imagem abaixo exemplifica isso.
Porque isso é importante?
O primeiro benefício é ligado diretamente ao reaproveitamento. Em um cenário onde você tem operações sendo reaproveitadas, copiar e colar código é receita para o caos no longo prazo. Seja pelo aumento de complexidade ou pelo vazamento de responsabilidade, dificultando inclusive a gestão do código.
A capacidade de trazer tratamentos do mais diversos para um lugar centralizado dentro do Application Layer oferece a possibilidade de assegurar que o mesmo tratamento é usado em qualquer tecnologia. gRPC, HTTP, AMQP, não importa. Sem necessidade de duplicar código, sem necessidade de rearquitetura de acordo o meio de transporte, sem necessidade de reimplementação.
Ainda do ponto de vista de responsabilidade, simplificamos controllers e handlers ao ponto se serem absolutamente burros, meros repassadores de mensagem para uma camada que essa sim, representa a aplicação e representa de fato o tratamento para o fluxo de negócio.
Quando as controllers e handlers implementam chamadas diretas a repositórios, operam entidades de domínio, ou até enviam emails sozinhas, você está na verdade pulverizando regras de negócio, regras de acesso a dados, por diversas camadas, por diversos componentes, tornando a manutenção mais complexa.
Evoluir, substituir, e refatorar se torna mais difícil e custoso, ma medida que o vazamento de responsabilidade causa inevitavelmente um maior acoplamento em todo o projeto. Parece um nó.
A responsabilidade de um Application Service é ser a porta de entrada para suas regras de negócio, para o coração de sua aplicação.
- Tudo deveria passar por eles antes de alcançar uma ou mais entidades.
- Acessos a outros adapters deveriam passar por ele, para que o requisitante apenas demande algo que o core da aplicação transformará em uma chamada ao outro adapter. O envio de email é um exemplo clássico desse fluxo.
Em contrapartida ao olhar inadvertido, camadas de serviço que só repassam mensagens podem parecer irrelevantes e código inútil. Sim é verdade, parece.
Mesmo quando há uma demanda por um repasse de mensagem, garantir que somente o core da aplicação se comunica com um determinado adapter te dá poderes para assegurar todas as regras que envolvem pré-condições, pós condições, processamento prévio e posterior à operação.
Análise
Quase todos os dias eu vejo desenvolvedores com alguma queixa sobre suas limitações para implementar alguma mudança em seu projeto. Coisas como adicionar caching, adicionar mensageria. Coisas que resolveriam problemas sérios, mas que por causa do acoplamento e da dependência com a web, e pela ausência de serviços puros, ou melhor serviços agnósticos, simplesmente não conseguem realizar.
Aqui eu tenho um exemplo real, do nosso projeto lá do Cloud Native .NET, o eShopCloudNative.
using eShopCloudNative.Catalog.Dto;
using eShopCloudNative.Catalog.Services;
using Microsoft.AspNetCore.Mvc;
namespace eShopCloudNative.Catalog.Controllers;
[ApiController]
[Route("Public/Catalog")]
public class PublicCatalogController : ControllerBase, IPublicCatalogService
{
private readonly IPublicCatalogService categoryService;
public PublicCatalogController(IPublicCatalogService categoryService)
{
this.categoryService = categoryService;
}
[HttpGet("CategoriesForMenu", Name = "CategoriesForMenu")]
public Task<IEnumerable<CategoryDto>> GetCategoriesForMenu()
=> this.categoryService.GetCategoriesForMenu();
[HttpGet("HomeCatalog", Name = "HomeCatalog")]
public Task<IEnumerable<CategoryDto>> GetHomeCatalog()
=> this.categoryService.GetHomeCatalog();
}
using AutoMapper;
using eShopCloudNative.Catalog.Dto;
using eShopCloudNative.Catalog.Entities;
namespace eShopCloudNative.Catalog.Services;
public class PublicCatalogService : BaseService, IPublicCatalogService
{
private readonly CategoryQueryRepository categoryQuery;
public PublicCatalogService(IMapper mapper, CategoryQueryRepository categoryQuery)
: base(mapper)
{
this.categoryQuery = categoryQuery;
}
public Task<IEnumerable<CategoryDto>> GetCategoriesForMenu()
=> this.ExecuteAndAdapt<CategoryDto, Category>(()
=> this.categoryQuery.GetCategoriesForMenu());
public Task<IEnumerable<CategoryDto>> GetHomeCatalog()
=> this.ExecuteAndAdapt<CategoryDto, Category>(()
=> this.categoryQuery.GetHomeCatalog());
}
using eShopCloudNative.Catalog.Dto;
using Refit;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace eShopCloudNative.Catalog.Services;
public interface IPublicCatalogService
{
[Get("/Public/Catalog/HomeCatalog")]
Task<IEnumerable<CategoryDto>> GetHomeCatalog();
[Get("/Public/Catalog/CategoriesForMenu")]
Task<IEnumerable<CategoryDto>> GetCategoriesForMenu();
}
using NHibernate;
using NHibernate.Criterion;
using NHibernate.Criterion.Lambda;
using NHibernate.Hql;
using NHibernate.Hql.Ast;
using NHibernate.Hql.Util;
using NHibernate.Linq;
using NHibernate.Action;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using NHibernate.Transform;
using eShopCloudNative.Architecture.Data.Repositories;
using eShopCloudNative.Catalog.Architecture.Data;
namespace eShopCloudNative.Catalog.Entities;
public class CategoryQueryRepository : CatalogQueryRepository<Category>
{
public CategoryQueryRepository(ISession session) : base(session)
{
}
public async Task<IList<Category>> GetHomeCatalog()
{
string hql = $@"
select category
from {nameof(Category)} as category
inner join fetch category.{nameof(Category.CategoryType)} as categoryType
inner join fetch category.{nameof(Category.Products)} as product
inner join fetch product.{nameof(Product.Images)} as image
where categoryType.{nameof(CategoryType.IsHomeShowCase)} = true
and image.{nameof(Image.Index)} = 0
";
var returnValue = await this.Session.CreateQuery(hql)
.SetResultTransformer(new DistinctRootEntityResultTransformer())
.ListAsync<Category>();
return returnValue;
}
public async Task<IList<Category>> GetCategoriesForMenu()
{
string hql = $@"
select category
from {nameof(Category)} as category
inner join fetch category.{nameof(Category.CategoryType)} as categoryType
left join fetch category.{nameof(Category.Parent)} as parent
";
var categories = await this.Session.CreateQuery(hql)
.SetResultTransformer(new DistinctRootEntityResultTransformer())
.ListAsync<Category>();
foreach (var category in categories)
{
category.Children = categories
.Where(it =>
it.Parent != null
&& it.Parent.CategoryId == category.CategoryId
&& it.CategoryType.ShowOnMenu
).ToList();
}
return categories.Where(it =>
it.CategoryType.ShowOnMenu
&& it.Parent == null)
.ToList();
}
}
Eu gosto desse exemplo porque ele é claro e objetivo.
A Web API sequer sabe quem são as entidades de fato. Ela entrega DTO’s para meu serviço. O business da Web API é falar com consumidores HTTP, é lidar com a web, é parametrizar o model binder dizendo qual o tipo de entidade queremos receber. Só.
Já os serviços, tem a responsabilidade, como camada, de ser a porta de entrada para tudo que acontece com a aplicação.
Nesse caso como é um serviço de consulta, sem parâmetros, o service não tem muita responsabilidade. No entanto é responsabilidade dele a conversão entre Entidade e Dto para que o mundo lá fora, fale com ele através dessas DTO’s.
O método ExecuteAndAdapt é quem faz essa conversão de tipos usando automapper.
Note que o resultado final fica extremamente simples ao ponto de parecer burro. Cada um fazendo seu papel.
O que eu acredito é que é assim que deve ser. Um bom código parece burro, parece simples. Não está cheio de try/catchs desnecessários.
A propósito as duas consultas foram customizadas porque essa é uma área em que performance é exigência, portanto é fundamental ter esse tipo de preocupação para que o resultado não tenha absolutamente nada a mais, nada a menos.
Da mesma forma que com RabbitMQ não é diferente
using AmqpAdapters;
using AmqpAdapters.Consumer;
using AmqpAdapters.Serialization;
using AppCore.Services;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
using System.Diagnostics;
using System.Linq;
using System;
namespace ConsumerWorkerService;
public static class Program
{
...
private static void Configure(HostBuilderContext hostContext, IServiceCollection services)
{
services.AddTransient<CustomerService>();
services.AddTransient<CalcService>();
services.AddRabbitMQ(cfg =>
cfg.WithConfiguration(hostContext.Configuration)
.WithSerializer<NewtonsoftAmqpSerializer>()
);
...
services.AddSingleton<IAmqpSerializer, NewtonsoftAmqpSerializer>();
if (hostContext.CanRun("customer"))
{
services.MapQueue<CustomerService, ExecuteAnythingRequest>(
"customer_ExecuteAnything_queue",
prefetchCount,
(svc, data) => svc.ExecuteAnything(data)
);
}
if (hostContext.CanRun("sum"))
{
services.AddAsyncRpcQueueConsumer<CalcService, CalcRequest, CalcResponse>(
"calc_sum_queue",
prefetchCount,
(svc, request) => svc.Sum(request)
);
}
...
}
...
}
using System;
using System.Threading.Tasks;
namespace AppCore.Services;
public class CustomerService
{
public Task ExecuteAnything(ExecuteAnythingRequest model)
{
if (model.Nome == "luiz")
throw new Exception();
return Task.CompletedTask;
}
}
using System;
using System.Diagnostics;
using System.Threading.Tasks;
namespace AppCore.Services;
public class CalcService : ICalcService
{
private readonly ActivitySource activitySource;
public CalcService(ActivitySource activitySource)
{
this.activitySource = activitySource;
}
public Task<CalcResponse> Sum(CalcRequest request)
{
return this.WithLog(request, nameof(Sum), (request) =>
{
if (request.Num1 == 77)
{
System.Threading.Thread.Sleep(TimeSpan.FromSeconds(5));
}
if (request.Num1 == 88)
{
throw new ArgumentOutOfRangeException("Lascou");
}
return request.Num1 + request.Num2;
});
}
...
}
Já aqui no caso do RabbitMQ as abstrações que criei, tanto para o Mensageria .NET, quanto para o Cloud Native .NET, fazem com que só seja necessário passar uma lambda que realize a operação com a mensagem.
O projeto e as abstrações são projetadas para assumir para si responsabilidades tecnológicas e específicas.
Web API
Assim a Web API Controller só se responsabiliza por lidar com HTTP, mas não realiza tarefas de negócio.
AMQP
Os adapters para AMQP (RabbitMQ) também abstraem os 2 fluxos de consumo de mensagens:
Fire and Forget onde estamos falando do consumo sem reposta.
RPC: Onde estamos falando do consumo com resposta.
O papel dessa abstração é assumir para si a responsabilidade de, em um só código, em uma só implementação, entregar uma abstração que permita somente no startup configurar o bind de uma fila do RabbitMQ para um método de serviço.
No consumo com Kafka, deveria ser a mesma coisa!
Service
O service adapta Dtos para Entidades e lida com as operações, hora realizando, hora interagindo com as entidades, hora delegando para os repositórios.
Os detalhes que vão sujar o código e ao mesmo tempo produzir vazamento de responsabilidade, para que o resultado final seja brutalmente simples, sem redundância, sem duplicidade, cada qual fazendo seu papel sem precisar tocar no trabalho da outra camada ou outro componente.
Conclusão
Em todos os casos acima, a responsabilidade das abstrações é conectar uma tecnologia à seu application service, de forma com que esse application service sequer tome ciência de onde veio a mensagem. Esses são os adapters primários, segundo Herberto Graça.
O core define contratos que são implementados por adapters secundários, também segundo Herberto Graça.
Assim nossos Application Service pode dependente fracamente de repositórios de outros serviços e outros adapters secundários.
Até porque é parte do fluxo de negócio, e não estou questionando a não realização de alguma tarefa de negócio.
Afinal, se você precisa enviar um email, você tem de enviar um email.
- A questão que fica é onde deve estar esse código?
- Quais princípios regem a decisão que você vai tomar?
- Basta criar um método enviar email no seu serviço, interagindo com Mimetype, Email Client, SMTP etc e foda-se?
O que questiono é onde o código que realizada cada operação deve estar e o impacto de misturar os assuntos.
As reclamações que eu escuto são reflexo da falta de discernimento e de pensar por 2 segundos, onde cada código deveria estar.
A gente gasta tempo demais olhando para coisas pouco importantes, e deixa de dar importância para o que realmente importa no final das contas.
Seu código tem de ser simples, simples, legível, burro ao olhar desatento!
Viva ao código burro!









O command handler não pode ser considerado um application service nesse caso?
O command handler não é puro.
Do ponto de vista de acoplamento, ele é igual a um Web API Controller, um MVC Controller, um Consumer AMQP.
Se assemelha mais a um adapter.
e pela natureza não pura, ele nunca estaria do lado de dentro da “aplicação”. Claro que pela perspectiva de Ports and Adapters.
Também vejo da mesma forma, uso mediatr justamente para ficar agnóstico a forma de input, seja uma http request ou processamento de uma mensagem do rabbitmq
A resposta, se é válida essa ideia ou não, é respondida pela resposta à uma outra pergunta.
Se você tivesse de reaproveitar essa operação, realizada pelo Handler, em uma Web API, em uma UI desktop, ou um Console, você ainda assim usaria esse handler?
Se a resposta for: para todo e qualquer cenário, esse handler seria usado, ele é a única forma de atores externos realizarem essa operação.
Então não vejo problema algum, faz sentido pensar nele como parte da aplicação.
Se a resposta contiver um “depende” ou um “veja bem…”, aí já vejo problemas.
No meu comentário eu já respondi a isso, quando falei que ele é agnóstico.
Sendo assim, ele não tem ideia de onde veio o comando, nem para onde vai.