
Testar aplicações é um desafio recorrente e complexo na engenharia de software. Porém, quando o cenário envolve restrições específicas de I/O — como latência de disco, throughput de leitura/escrita reduzido ou limitação de operações por segundo — o desafio ganha outra dimensão.
Nesse contexto, a capacidade de simular gargalos de I/O torna-se uma ferramenta poderosa para validar a resiliência, eficiência e tolerância a falhas da sua aplicação. Felizmente, o Docker oferece mecanismos para isso, permitindo configurar limites finos de I/O em containers.
Não é todo dia que você é exposto a esse tipo de necessidade, como fui recentemente. Entretanto, a capacidade de ter à mão, algo tão simples quanto poderoso, permite validar e experimentar problemas previsíveis, muito antes de sequer contratar uma infra em produção.
É mais do que validar um setup, é sobre entregar previsibilidade arquietural.
Vamos explorar como isso pode ser feito, por que é útil e quais problemas essa abordagem ajuda a evitar.
Por que simular limitações de I/O?
Sistemas modernos frequentemente dependem de bancos de dados, message brokers, object storage e sistemas de arquivos em rede. Em ambientes de produção, esses recursos estão sujeitos a:
- Sobrecarga de IOPS (Input/Output Operations per Second);
- Baixa largura de banda de leitura/escrita;
- Latência provocada por armazenamento remoto ou compartilhado;
- Comportamentos erráticos em períodos de alta concorrência.
Existe um fenômeno que não é isolado nem tão raro, em que certos tipos de ambiente/empresa onde os notebooks e/ou desktops dos desenvolvedores podem ter vezes mais capacidade de I/O, CPU e memória do que um servidor de produção.
Me recordo de uma compra de 2023 onde fiz compra de SSD para o meu desktop de desenvolvimento, focando quase que exclusivamente em throughput.



Por mais que o desktop possa estar sub um sistema operacional “pesado”, com várias instâncias de visual studio abertas, e vários npm installs dragando I/O preenchendo node_modules com toda a internet, ainda consigo ter uma máquina responsiva para fazer isso tudo enquanto gravo uma aula, um vídeo para o YouTube ou algo assim.
Esse é o meu caso de uso.
Outros compram hardware eficiente por puro prazer, satisfação, ou mesmo para jogar, já que alguns usam o mesmo equipamento para essa finalidade.
Há muitos motivos para existir essa discrepância entre o desktop/notebook do desenvolvedor e o ambiente de produção e, portanto, precisamos tomar algum cuidado se não estivermos atentos ao quanto de hardware estamos entregando para os nossos servidores produtivos.
Por isso, simular restrições é importante.
Ao simular essas restrições longe do ambiente produtivo conseguimos:
- Avaliar comportamento da aplicação sob stress realista;
- Validar estratégias de retry, timeout e fallback;
- Identificar gargalos arquiteturais ocultos;
- Prevenir falhas críticas antes que elas atinjam produção.
Mas como docker pode nos ajudar com isso?
Docker e controle de I/O: os parâmetros que importam
O Docker permite impor limites de I/O por container usando parâmetros específicos no momento de execução. São eles:
--device-read-bps="<dispositivo>:<limite>"
Limita a taxa de leitura (em bytes por segundo) de um determinado dispositivo.
Exemplo:
#!/bin/sh docker run --device-read-bps /dev/sda:10mb ubuntu
Este comando limita o container a ler no máximo 10 MB/s do dispositivo /dev/sda.
--device-write-bps="<dispositivo>:<limite>"
Controla o throughput de escrita no dispositivo.
Exemplo:
#!/bin/sh docker run --device-write-bps /dev/sda:5mb ubuntu
Limita a escrita a 5 MB/s, útil para simular discos lentos ou saturados.
--device-read-iops="<dispositivo>:<limite>"
Impõe limite ao número de operações de leitura por segundo (IOPS).
Exemplo:
#!/bin/sh docker run --device-read-iops /dev/sda:100 ubuntu
Aqui, o container poderá fazer no máximo 100 operações de leitura por segundo.
--device-write-iops="<dispositivo>:<limite>"
Faz o mesmo para escrita, restringindo a IOPS de gravação.
Exemplo:
#!/bin/sh docker run --device-write-iops /dev/sda:50 ubuntu
Casos de uso reais em ambientes .NET
1. Testes com EF Core sob disco lento
Simule um ambiente de banco de dados em disco mecânico para validar o comportamento de consultas N+1, migrações e cenários onde o DbContext.SaveChanges() leva segundos para concluir.
2. Simulação de message brokers com I/O degradado
Ao limitar o throughput do volume onde o RabbitMQ ou Kafka armazena os logs de mensagens, é possível validar o comportamento do seu sistema sob latência, inclusive testando dead-letter queues e redelivery policies.
2. Simulação de serviços de armazenamento baseados em Lucene
ElasticSearch ou Solr podem ser gravemente afetados pela falta de I/O do disco, podendo causar até, em última análise, perdas financeiras, quando mal provisionados. Já presenciei uma gravação consumir 1 segundo inteiro em uma chamada de API.
3. Serviços que realizam processamento em lote
Serviços de ETL ou processamento batch que dependem de grandes volumes de leitura e escrita podem ser testados quanto à degradação de performance — inclusive validando alertas de observabilidade com Prometheus e Grafana.
Benefícios: o que essa abordagem evita
- Falhas em produção causadas por ambientes otimizados de desenvolvimento (SSD local vs. disco remoto);
- Code paths não exercitados, como retry policies, circuit breakers e timeouts mal configurados;
- Impressão falsa de performance por testes realizados apenas em condições ideais;
- Problemas de throughput que só aparecem com carga real e concorrência.
O que é possível validar antes de chegar à produção
Ambientes controlados permitem medir:
- Tempo médio de resposta em cenários com I/O degradado;
- Eficiência do uso de cache (Redis, MemoryCache, etc);
- Resiliência do sistema a falhas intermitentes de armazenamento;
- Capacidade de fallback ou uso de circuit breakers (ex: Polly no .NET);
- Alertas reais de latência e disponibilidade (observabilidade realista).
Até que ponto vale a pena?
A tabela abaixo foi gerada pelo chatGPT (mas temos a doc aqui).

Esses números podem servir de base para testes alinhados a ambientes produtivos. Caso eles não digam muita coisa, entenda o custo de cada um, estamos falando de uma variação muito significativa.
Se compararmos a um bom SSD, não tão incomum em um desktop de desenvolvimento, vemos o valor absurdo pago a depender do cloud provider.
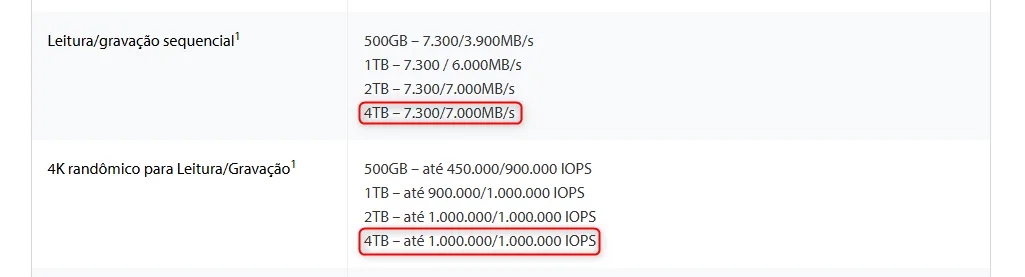
Entregar na cloud, números comparáveis com esses custa muito caro, portanto, testar seus recursos e aplicações com base nesses números permite entender o que funciona, o que não funciona e qual o risco.
Conclusão: simular é prevenir
Testar sob limitações de I/O é uma prática essencial para aplicações críticas, especialmente em sistemas distribuídos. Com Docker, é possível incorporar essa etapa à sua esteira de qualidade sem depender de hardware específico.
Essa abordagem vai além do “testa que funciona”: ela antecipa o imprevisível e prepara o sistema para o pior cenário possível.
Use os parâmetros de limitação de I/O do Docker como parte do seu arsenal de testes — porque em produção, o inesperado não perdoa.

PS: Não dá para simular algo que seu hardware sequer entrega.
O óbvio precisa ser dito.
Se seu desktop não tem hardware suficiente para esse teste, se não tem um hardware mais eficiente que o servidor na cloud. Então não há muito a ser feito.
Ainda não validei, mas um teste futuro que quero fazer é sob o tmpfs, criando um volume que em vez de usar disco, utiliza memória RAM.
Dessa forma seria possível entregar um file system mais rápido do que qualquer um dos seus discos ou ssd’s.





0 comentários