.NET
Cloud Native e Cloud Agnostic
para rodar .NET em qualquer Cloud
ou sem Cloud sempre de forma profissional!
Últimas publicações
Aqui estão os últimos 12 posts de mais de 500…
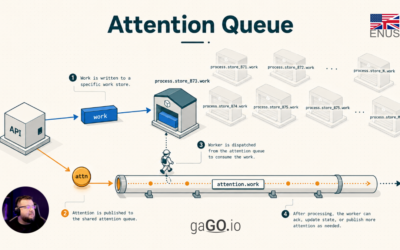
Attention Queue: on-demand processing for granular queues
Consume thousands of specific queues without keeping thousands of active consumers. The Problem Imagine an e-commerce platform called MarketHub. It integrates thousands of stores with marketplaces such as Amazon, eBay, Walmart Marketplace, and other sales channels. Each store needs to synchronize...
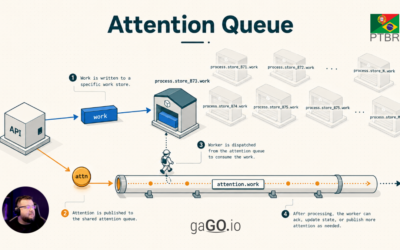
Attention Queue: processamento sob demanda para filas granulares
Um padrão para consumir milhares de filas específicas sem manter milhares de consumidores ativos. O problema Imagine uma plataforma de e-commerce chamada MarketHub. Ela integra milhares de lojas com marketplaces como Amazon, Mercado Livre, Shopee e outros canais de venda. Cada loja precisa...

Circular Buffer, Ring Buffer, ObjectPool e Objects Pools Elásticos
Segunda-feira, 14h. Pico de tráfego. Sua aplicação .NET começa a derreter conexões com o RabbitMQ. Você abre o Grafana, vê 800 conexões abertas contra um broker que aguenta confortavelmente 50, e a hipótese imediata é "vamos limitar o pool". Alguém sobe um SemaphoreSlim, faz deploy, e na...

Tokenmaxxing não é histeria
É arbitragem temporal sobre um ativo subprecificado. A imprensa generalista pegou o fenômeno do Vale do Silício e fez o que sabe fazer: transformou em pauta de saúde mental, produtividade tóxica e crítica ao culto da hiperperformance. É leitura confortável, vende cliques e tranquiliza quem não...

Agent Skill – O elo que faltava para entregar precisão aos code agents
Você já viu dezenas de vídeos sobre Agent Skills. Leu posts, explorou repositórios, talvez até tenha criado uma ou duas. E mesmo assim, na hora de usar num projeto real, o resultado continua genérico, impreciso, frustrante. O problema não é o conceito. O problema é que a maioria do conteúdo que...

Event-driven Architecture: você está reaproveitando eventos ou mentindo para o seu próprio sistema?
Quantos eventos no seu sistema são emitidos em situações onde o fato que eles representam simplesmente não aconteceu? Um PedidoCriado disparado por uma rotina de correção. Um PagamentoConfirmado emitido por um job de reprocessamento. Um UsuarioCadastrado lançado por uma migração de base legada. O...

A corrida dos humanos
Existe uma versão da corrida dos ratos que não vejo ninguém discutindo. Na versão original, a "corrida dos ratos" é um conceito popularizado por Robert Kiyosaki no livro Rich Dad Poor Dad. A metáfora descreve um ciclo em que a pessoa trabalha mais para ganhar mais, gasta mais porque ganha mais, e...

OA03 – Fazemos o que precisa ser feito e arcamos com as consequências das decisões que tomamos
Seu time quer publicar pacotes NuGet mas não quer manter um NuGet Server. Quer rodar containers mas não quer contratar um Container Registry. Quer processar mensagens assíncronas mas acha que uma tabela com coluna status no PostgreSQL resolve. A pergunta que ninguém faz é: por que você está...

OA02 – Governança Arquitetural e Open Architecture- Você não pode esperar proatividade, muito menos de quem não tem acesso
As 7 regras que uso para governar componentes arquiteturais em projetos .NET de grande porte — e filtrar quem realmente está pronto para evoluir a arquitetura. Existe uma expectativa velada em muitos times de desenvolvimento: a de que bons desenvolvedores simplesmente "se envolvem" com a...

OA01 – Por mais discriminadores de comportamento e menos enums
Existe um vício oculto em projetos .NET que poucos questionam: usar enums para representar status, tipos e categorias, e depois espalhar if e switch por toda a base de código com base em deduções de regras implícitas. if (grupo.Tipo == TipoGrupo.Administrador) { // pode acessar tudo } else if...

Oragon.RabbitMQ 1.6 – Welcome .NET 10
Desde a versão 1.1.0 (janeiro/2025), o Oragon.RabbitMQ passou por 6 releases com mais de 70 commits, resultando em +3.894 linhas adicionadas e -1.245 removidas ao longo de 112 arquivos. A seguir, um resumo das principais novidades. O que mudou de v1.1 para v1.6 Suporte a .NET 10 A partir da...

Agnostic Services, Hexagonal Architecture SEM DDD
Esta semana, me deparei com críticas à arquitetura Hexagonal (Ports and Adapters) fundamentadas na suposição equivocada de que seu uso está condicionado à aplicação de Domain-Driven Design (DDD). Como se fosse um privilégio reservado apenas a sistemas que alcançaram um suposto "grau de maturidade...
Projetos Open Source
projetos ativos e projetos antigos disponíveis para estudo

OpenIdConnect Mock Server – Identity Server fake
Você já fez uma prova de conceito ou uma demonstração em que seria bem interessante testar com vários perfís, mas pensou duas vezes sobre o esforço de subir um Identity Server? Já se questionou quais alternativas teria e tentou de tudo não ter esse esforço? Pois bem, aconteceu comigo algumas...
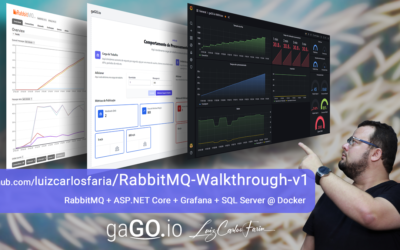
RabbitMQ Walkthrough v1
RabbitMQ - Demonstração de Comportamento padrão com Mensageria. Material complementar dos cursos: RabbitMQ para Aplicações .NETDocker Definitivo / O ROADMAP Objetivo 1) Demonstrar comportamento padrão quando: A) Temos uma carga de trabalho menor que nossa capacidade de processamentoB) Temos uma...

mssql-server-linux | SQL Server +Automações
A mesma imagem do SQL Server no Linux, mas tão configurável quanto as consagradas imagens do MariaDB, MySQL e PostgreSQL. Quem precisa subir um banco de dados junto com a aplicação precisa de uma imagem que possibilite a criação de usuários, databases, inicialização via scripts. Esses recursos já...

Oragon.AspNetCore.Hosting.AMQP
Se olharmos com cuidado para o HTTP e AMQP conseguimos encontrar semelhanças das mais diversas. Headers, Body. Se olharmos sobre as implementações sob o HTTP que conhecemos, vemos também outras características comuns como Routing, parsing. Fato que usar a infraestrutura base do ASP.NET Core, com...
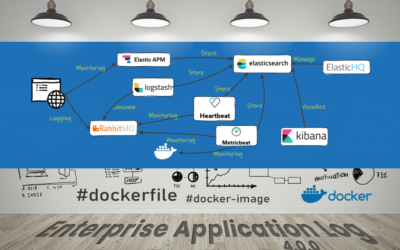
EnterpriseApplicationLog
Enterprise Application Log consiste é um stack pré-configurado que contém RabbitMQ e ELK Stack colaborando para entregar uma robusta plataforma de monitoramento, centralização e consolidação de logs. Nesse stack de log utilizo RabbitMQ, LogStash, ElasticSearch e Kibana com Docker Compose. São...


Entender | Analisar | Projetar | Desenvolver | Implantar | Manter
A segurança que você busca não está em um tutorialPara entender uma tecnologia é importante entender o que influenciou sua criação, o que ela faz de fato, como ela faz. Para que então se sinta seguro e confiante a respeito das decisões que está prestes a tomar.
De um lado precisamos compreender o que está sendo feito por baixo dos panos para descobrir como extrair o máximo de uma tecnologia ou, ao menos, não atrapalhar o bom funcionamento dela.
O Cloud Native .NET é uma jornada de descoberta sobre tecnologias e patterns que fazem parte da maioria dos softwares que usamos, que somos usuários e que suportam e toleram altas cargas de trabalho, de forma eficaz, eficiente e sustentável.
É primeiro entendendo o que eles fazem, que podemos descobrir oportunidades e evoluir no que fazemos…

Conteúdo
A corrida dos humanos
Existe uma versão da corrida dos ratos que não vejo ninguém discutindo. Na versão original, a "corrida dos ratos" é um conceito popularizado por Robert Kiyosaki no livro Rich Dad Poor Dad. A metáfora descreve um ciclo em que a pessoa trabalha mais para ganhar mais, gasta mais porque ganha mais, e...
OA03 – Fazemos o que precisa ser feito e arcamos com as consequências das decisões que tomamos
Seu time quer publicar pacotes NuGet mas não quer manter um NuGet Server. Quer rodar containers mas não quer contratar um Container Registry. Quer processar mensagens assíncronas mas acha que uma tabela com coluna status no PostgreSQL resolve. A pergunta que ninguém faz é: por que você está...
OA02 – Governança Arquitetural e Open Architecture- Você não pode esperar proatividade, muito menos de quem não tem acesso
As 7 regras que uso para governar componentes arquiteturais em projetos .NET de grande porte — e filtrar quem realmente está pronto para evoluir a arquitetura. Existe uma expectativa velada em muitos times de desenvolvimento: a de que bons desenvolvedores simplesmente "se envolvem" com a...
OA01 – Por mais discriminadores de comportamento e menos enums
Existe um vício oculto em projetos .NET que poucos questionam: usar enums para representar status, tipos e categorias, e depois espalhar if e switch por toda a base de código com base em deduções de regras implícitas. if (grupo.Tipo == TipoGrupo.Administrador) { // pode acessar tudo } else if...
Oragon.RabbitMQ 1.6 – Welcome .NET 10
Desde a versão 1.1.0 (janeiro/2025), o Oragon.RabbitMQ passou por 6 releases com mais de 70 commits, resultando em +3.894 linhas adicionadas e -1.245 removidas ao longo de 112 arquivos. A seguir, um resumo das principais novidades. O que mudou de v1.1 para v1.6 Suporte a .NET 10 A partir da...
Agnostic Services, Hexagonal Architecture SEM DDD
Esta semana, me deparei com críticas à arquitetura Hexagonal (Ports and Adapters) fundamentadas na suposição equivocada de que seu uso está condicionado à aplicação de Domain-Driven Design (DDD). Como se fosse um privilégio reservado apenas a sistemas que alcançaram um suposto "grau de maturidade...

RabbitMQ: Filas efêmeras
Ao pensar em filas, é comum pensarmos em filas com um ciclo de vida muito longo, filas que existem enquanto a aplicação existir. É comum pensarmos em filas como recursos estáticos que fazem parte dos requisitos de funcionamento da aplicação, nascendo quando a aplicação é implantada em produção...

Respondendo: Até que ponto isolamento de Bases de Dados em Microsserviços faz sentido?
Recentemente, um aluno questionou no nosso fórum interno sobre abordagens como Database-server-per-service, Database-per-service, Schema-per-service e Private-tables-per-service no contexto de microsserviços. Esse é um tema recorrente quando o assunto é microsserviços e não há resposta...

Simulando I/O limitado com Docker: como testar aplicações sob restrições realistas
Testar aplicações é um desafio recorrente e complexo na engenharia de software. Porém, quando o cenário envolve restrições específicas de I/O — como latência de disco, throughput de leitura/escrita reduzido ou limitação de operações por segundo — o desafio ganha outra dimensão. Nesse contexto, a...

O perigo silencioso das conexões stateful: por que respeitar o ciclo de vida importa?
APIs HTTP dominam por décadas o paradigma de comunicação entre aplicações, é fácil cair na armadilha de tratar qualquer conexão como se fosse apenas mais uma requisição stateless, principalmente conexões stateful "sob HTTP". Mas nem toda conexão é igual. E conexões de longa duração merecem muito...

O marketing dos benchmarks
Já faz algum tempo que os benchmarks deixaram de ser apenas uma ferramenta técnica e passaram a ocupar espaço central no marketing de produtos e tecnologias. De linguagens de programação a frameworks web, de modelos de LLM a placas de vídeo, benchmarks são utilizados como argumentos de venda — e...

Mitigando os custos de Reflection
Reflection oferece um mecanismo sofisticado para inspeção e manipulação de metadados de tipos, métodos e propriedades em tempo de execução. No entanto, essa flexibilidade vem acompanhada de custos elevados, que penalizam desempenho e eficiência de qualquer aplicação. Sempre que podemos evitar,...
Conheça nosso Podcast
DevShow PodcastEm 2019 resolvemos criar um podcast, o DevShow Podcast, desde lá são mais de 40 episódios com muito assunto legal, sempre com essa pegada pessoal, falando coisas sérias, mas sem o menor compromisso com a formalidade.
.NET
Attention Queue: on-demand processing for granular queues
Consume thousands of specific queues without keeping thousands of active consumers.
The Problem
Imagine an e-commerce platform called MarketHub.
It integrates thousands of stores with marketplaces such as Amazon, eBay, Walmart Marketplace, and other sales channels. Each store needs to synchronize orders, inventory, prices, catalog data, shipping updates, and post-sale events. Most of the time, a small store generates little work. But when a large store performs a massive catalog update or receives a burst of orders during a campaign, it can generate thousands of tasks within minutes.
In MarketHub, each store has its own work queue. In simple terms, a queue is a persistent list of messages waiting to be processed. A producer puts messages into the queue; a consumer reads those messages and performs some action. In this scenario, the producer is MarketHub’s own API, not the external integrator.
This decision is not about aesthetic preference for granularity. It exists because different stores have different behaviors, priorities, and risks. A small store should not sit behind thousands of catalog updates from a very large store. A store with an unstable integration should not congest processing for the others. Also, a dedicated queue allows store-specific policies: consumption limits, operational pauses, maintenance, controlled discard, isolated reprocessing, respect for marketplace API limits, and direct observability into that store’s backlog.
In other words, a queue per store buys isolation, predictability, and operational control.
But it also creates a new architectural tension: if every store has its own queue, who consumes those queues?
The first solution seems obvious: create permanent consumers for every store queue. A permanent consumer would be a worker registered on that queue all the time, waiting for new messages.
But that creates another problem.
If there are 50,000 stores, it does not make sense to keep 50,000 active consumers, open connections, configured prefetch, and reserved resources for queues that are empty most of the time. The system starts spending compute capacity waiting for work that may not exist.
The real problem is not just processing messages.
The problem is finding an intermediate model between two bad extremes: too many permanent consumers or an overly centralized queue. The system needs to start consumers on demand for specific queues, but only when there is some indication that work is pending in that queue. It also needs to decide how long each temporary consumer should work, how many messages it should try to consume, and how to prevent multiple workers from processing the same queue in an uncontrolled way.
Considered Alternatives
Several solutions appear quickly.
The first is to use permanent consumers per queue. It is simple to understand, but it scales poorly when there are many granular queues and low average volume per queue.
The second is to use a single central queue for all stores. This reduces the number of consumers, but loses isolation. A noisy store can delay smaller stores, and store-specific policies become harder.
The third is to create grouped centralized queues. Instead of one queue for all stores, the system could create smaller groups, for example process.marketplace.group_01.work, process.marketplace.group_02.work, and so on. Each group would receive tasks from some stores. This approach looks like a middle ground: it reduces the number of queues and avoids making all stores compete in one global queue.
The problem is that isolation remains partial and accidental. Imagine group_01 has 100 stores. If one large store inside that group generates 1 million jobs during a campaign, the other 99 stores are stuck behind it or forced to compete with it inside the same queue. The problem is no longer global, but it became local: instead of one store affecting the whole platform, it affects every store in the group.
If group distribution becomes poor, teams need to rebalance stores across queues, which adds operations, migration, and risk. Also, store-specific policies remain difficult: API limits, pausing one integration, commercial priority, and isolated reprocessing need to be rebuilt inside the consumer, because the queue no longer represents a single store. Grouping improves the single-queue approach, but does not provide real isolation per store.
The fourth is to periodically poll all queues. A scheduler scans queues and processes the ones that have messages. It works, but it introduces artificial latency, increases empty calls to the broker, and wastes cycles when many queues are inactive. Here, broker means the messaging server, such as RabbitMQ, responsible for storing and delivering messages.
The fifth is to make the API publish messages directly to specific queues and, along with them, publish a small internal signal saying: this queue needs attention.
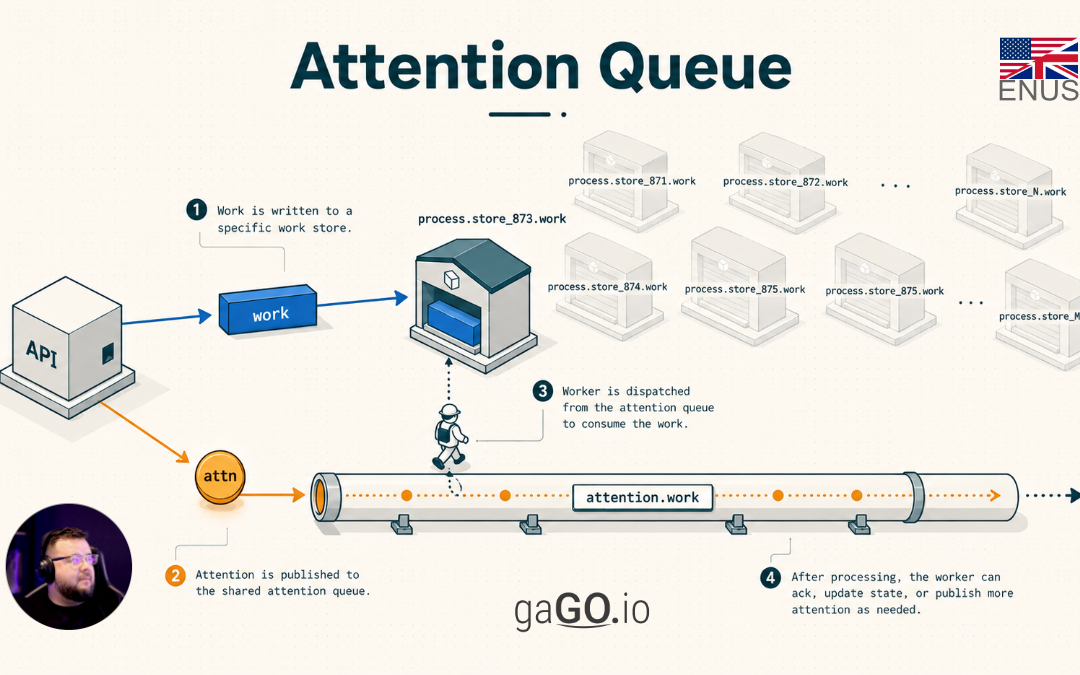
That is the solution we will call Attention Queue.
The core idea is to produce two types of messages inside the system. For the external integrator, there is still a single operation: an HTTP call to the API, for example to send an inventory update or synchronization task. After the API receives and validates that request, it internally publishes two messages. The first is the work message: it contains the real data that needs to be processed. The second is the attention message: it is smaller and only serves to tell the system itself that a specific queue has pending demand and needs to be consumed.
| Type | Where it lives | What it contains | What it is for |
|---|---|---|---|
| Work message | Store-specific queue | Real task payload, such as inventory update, order, or catalog data | To be processed by business logic |
| Attention request | Shared attention queue | Minimal pointers, such as tenant, store, marketplace, and priority | To trigger consumption of the correct work queue |
The real message enters the resource-specific queue. That queue is where the data that actually needs to be processed waits. For example:
process.marketplace.store_873.work
This queue name is only a didactic convention. An implementation can choose another format. The essential point is that the attention request has enough data to locate, derive, or query which work queue needs to be consumed.
The signal enters a shared attention queue. This queue does not store the complete work; it only stores notices that some specific queue needs to be inspected. For example:
attention.marketplace.work
That signal does not contain the full payload. It contains only what is needed to locate the queue that needs attention, meaning the queue that needs to be consumed: tenant, resource type, resource id, and some routing keys. For a .NET developer, this signal can be seen as a small DTO, serialized as JSON and published internally by the system itself.
With this, the system does not need to keep permanent consumers for every work queue. It keeps consumers on the attention queue. When an attention message arrives, a worker uses that notice to locate the specific queue, starts a temporary consumption cycle, consumes for a limited time or up to a maximum number of messages, and then decides whether the work is done or whether it needs to republish another attention request.
This decision to stop before consuming everything is intentional. The inspiration comes from process scheduling in operating systems, especially the concept of time sharing. The CPU keeps processes ready to run and does not allow a single process to monopolize the processor indefinitely. It gives one process a time slice, interrupts it, and then gives other processes a chance to advance. In Attention Queue, the attention queue plays a similar role to a ready queue: each attention message represents a work queue asking for a processing slice. If there are still messages after that slice, the queue enters the processing competition again through a new attention message.
The pattern is not only trying to be efficient; it is trying to be fair. Each store receives processing slices, preventing a large store from capturing most workers and turning volume into unintended operational privilege.
How It Works

The pattern works like an internal dispatcher.
It does not process the work directly. It points to where work exists. In a .NET application, think of it as a BackgroundService or worker that receives a small command and, from that command, decides which work queue should be consumed.
Instead of constantly asking whether each queue has messages, the system receives a signal when something new arrives. Instead of leaving an eternal consumer sitting on an empty queue, it starts a temporary consumer only when there is a reason to do so.
A typical flow would be:
- An integrator makes an HTTP call to the MarketHub API requesting a synchronization or sending an update.
- The API validates the request and internally publishes the task to
process.marketplace.store_873.work. - In the same internal operation, the API publishes a signal to
attention.marketplace.work. - A worker consumes that attention signal.
- The worker checks the state of the related store or integration.
- If the store is disabled, under maintenance, blocked due to credential errors, or removed, the attention is discarded.
- If the store is valid, the worker calculates the consumption limits: maximum time, maximum number of messages, and allowed concurrency.
- The worker tries to acquire rate-limit permission to avoid too many simultaneous consumers on the same queue. In this context, rate limit is just a capacity gate: how many consumers can work on that queue at the same time. This limit can be 1 when the queue must be consumed serially, or it can be higher, such as 5 or 10, when the domain allows safe parallelism.
- If allowed, it starts a temporary consumer on the store-specific queue.
- It processes messages until one of the stop conditions is reached: maximum time, maximum message count, operational error, or empty queue.
- At the end, it checks whether there is still backlog. If there is, it republishes a new attention request to the attention queue. If not, it stops.
- The new attention returns to the same shared attention queue and will be consumed in the next cycle by some available worker. It may be the same worker or another one. The point is that one large store’s queue does not monopolize processing indefinitely.
Finding the work queue empty is not an error. An attention request can arrive late: when the worker checks the work queue, it may already have been consumed by another cycle. In that case, the worker simply acknowledges the attention and stops.
The important point is that the attention signal is cheap, small, and repeatable.
It does not need to represent exactly one work message. It represents an intention: this queue deserves to be observed and probably needs to be consumed.
For that reason, the attention request must be idempotent. The system must tolerate receiving two or more attention requests for the same store without causing improper duplicate processing. In the worst case, an extra attention starts an attempt that finds the queue empty, is blocked by the concurrency limit, or notices that the backlog was already processed by another cycle.
This changes how we think about the design. The attention queue is not the work queue. It is the coordination queue. It works like a scheduling queue: it decides which work queue receives the next processing slice.
Complete Example
In MarketHub, each store has its own queue:
process.marketplace.store_{storeId}.work
The marketplace integration set has an attention queue:
attention.marketplace.work
When store store-873 needs to synchronize orders or update inventory in a marketplace, the integrator makes a single HTTP call to the API. For the integrator, the operation ends there: it sent the request to MarketHub. The API itself knows that it also needs to generate an attention request.
After receiving the HTTP call, the API performs two internal publications to the broker. This double publication must be treated as one operational unit: it is not enough to publish the work message and hope the attention request is also published. If the first publication succeeds and the second one fails, the store queue may contain pending work with no signal to trigger consumption.
There are several ways to protect this point, depending on the level of guarantee required by the application: use broker publish confirmations, apply the outbox pattern, perform idempotent retry of the attention publication, or keep a periodic reconciliation process that finds queues with backlog and no recent attention. The specific technique may vary, but the architectural decision is the same: the work message and the attention request are part of the same operational intent.
The examples below use three common RabbitMQ terms. The exchange is the point where the application publishes the message. The routingKey is the key used to decide the message path. The queue is where the message stays stored until some consumer processes it.
The first publication carries the real work:
exchange: process.marketplace routingKey: store.store-873 body: complete synchronization task
The second publication carries only the attention request:
{
"tenantId": "seller-group-a",
"storeId": "store-873",
"marketplace": "amazon",
"priority": "normal"
}
The attention worker receives this second event and builds the real queue:
process.marketplace.store_873.work
Before consuming, it applies a policy:
maxConsumptionTimeSeconds = 20 maxMessages = 100 maxConcurrentConsumers = 2
In this example, maxConcurrentConsumers = 2 means at most two consumers can process that store queue at the same time. In another scenario, this value could be 1, guaranteeing a single active consumer per work queue. That is useful when event order matters, when there is risk of conflict in inventory updates, or when the marketplace API requires more controlled calls. If the store has a higher plan, stable integration, and independent operations, the limit could be 10.
Then it tries to acquire a concurrency token for that store. If enough consumers are already processing that queue, the attention is republished for a future attempt.
If allowed, the worker consumes up to 100 messages or up to 20 seconds. It does not continue until the queue is empty because that would allow one noisy store to occupy the worker for too long. If messages remain, it republishes a new attention request. That new attention returns to attention.marketplace.work and will be competed for by the consumers of that attention queue. If the queue is empty, the worker stops.
Implementation

The pattern can be implemented with five components.
It does not require a generic messaging abstraction. The examples below use common .NET and RabbitMQ vocabulary, but the most important part is the explicit domain contract: a work message, an attention message, a worker that understands that contract, and a clear consumption policy.
The first is the granular work queue. It stores real messages per entity, customer, store, account, or any unit that needs isolation. This is where the payload that business logic will process lives.
The second is the aggregated attention queue. It receives small signals grouped by type. This queue is consumed by a small number of permanent workers.
The third is the attention envelope. It contains the minimum identifiers needed to locate the work queue that needs attention. This envelope must be safe to repeat: publishing or consuming the same request more than once must not corrupt system state. In C#, it could be a simple class, for example:
public sealed class AttentionRequest
{
public required string TenantId { get; init; }
public required string StoreId { get; init; }
public required string Marketplace { get; init; }
}
The fourth is the attention worker. It validates entity state, starts a temporary consumer, processes a controlled batch, and decides whether more attention is needed. This worker does not need to hide RabbitMQ behind a generic abstraction; it can call explicit broker APIs or internal services.
The fifth is concurrency control. It is usually backed by Redis, a database, or a distributed lock, to prevent multiple workers from processing the same queue beyond the allowed limit. This limit does not need to be greater than 1. In many cases, the correct value is exactly 1 active consumer per work queue. In others, the limit can be 10 or more, as long as processing is independent, idempotent, and safe for parallelism.
In a .NET codebase, these components could appear as domain-specific contracts:
public interface IAttentionPublisher
{
Task PublishAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public interface IAttentionWorker
{
Task<AttentionResult> ProcessAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public enum AttentionResult
{
Done,
NeedMoreAttention
}
These interfaces do not need to promise that they work for any broker or every messaging use case. They exist to represent a specific architectural decision: publish attention requests and consume work queues on demand.
One possible pseudocode:
In the pseudocode, ack attention means confirming to the broker that the attention message was handled and can leave the queue. If the worker fails before the ack, the broker may try to deliver the same attention again, depending on configuration. This is another reason why the attention request must be idempotent. The opposite of ack is usually called nack, used when the message was not successfully processed and should follow the error or retry policy.
on attention_received(attention):
resource = load_resource(attention.resource_id)
if resource cannot receive processing:
ack attention
return
queue_name = build_work_queue_name(resource)
if rate_limit_blocked(queue_name):
republish attention
ack attention
return
if queue_does_not_exist(queue_name):
ack attention
return
if queue_is_empty(queue_name):
ack attention
return
consume_until(
queue = queue_name,
max_messages = resource.max_messages,
max_time = resource.max_time
)
if queue_has_remaining_messages(queue_name):
republish attention
ack attention
The republish attention step is not recursion and not an immediate call to the same worker. It places a new request at the end of the attention queue. After that, the current worker finishes the cycle and becomes free to pick up the next available request. The broker delivers the new attention when its turn comes, respecting concurrency and the operational order of the queue.
In RabbitMQ, a concrete implementation can use a topology like this. The binding is the rule that connects an exchange to a queue.
exchange: attention.marketplace queue: attention.marketplace.work binding: store.* exchange: process.marketplace queue: process.marketplace.store_873.work binding: store.store-873
The API publishes the full payload to the work queue and publishes a small envelope to the attention queue:
HTTP request from integrator API validates request API publishes process event API publishes attention event
In a real implementation, these last two steps must have an explicit consistency strategy. If there is no single transaction covering everything, the application needs confirmations, retry, outbox, or reconciliation to avoid leaving work without attention.
The attention worker, in turn, does not need to know every store ahead of time. It only needs to know how to transform the attention envelope into a queue name, consumption policy, and concurrency-control key.
Observability
Attention Queue is comfortable to operate only when the system clearly shows where work is stuck, where there is too much attention, and where policy is blocking consumption.
Useful metrics include:
| Metric | What it reveals |
|---|---|
| Message count per store queue | Which stores are accumulating backlog |
| Age of the oldest message per queue | How long the most delayed store has been waiting for processing |
| Number of republished attentions | Which queues need many cycles to empty |
| Attentions discarded because the store is disabled or invalid | How much work is being ignored due to operational state |
| Rate-limit blocks | Which stores are hitting concurrency or SLA limits |
| Average time to clear backlog | How long the system takes to recover a queue with pending work |
These metrics help separate different problems. A store may be slow because it has real backlog, because it is limited by plan, because the integration is blocked, because there are too many repeated attentions, or because available workers are not enough. Without these measurements, the pattern still works, but explaining its behavior in production becomes difficult.
When Not To Use It
Attention Queue should not be treated as the default solution for every asynchronous processing problem.
If the system has few queues, predictable volume, and permanent consumers that are cheap to maintain, the pattern may add unnecessary complexity. If a single queue already works well, with acceptable latency and no isolation problems, there may not be enough pain to justify granular queues and attention requests.
It is also not a good choice when processing must obey a strictly global order across all messages. The pattern favors isolation and fairness across queues, not one single ordering for the whole system.
Another point is operational cost. Dynamic queues require naming conventions, creation, removal, monitoring, and diagnostic capability. If the broker or the team cannot yet operate many queues safely, it is better to mature that foundation before adopting the pattern.
Benefits
The main benefit of the pattern is aligning consumption with real demand.
It allows the system to maintain thousands or millions of logical queues without requiring thousands or millions of active consumers. The system becomes more elastic because consumers appear when there is backlog and disappear when work is done.
It also improves isolation. A noisy entity does not need to contaminate the flow of others, because each entity can have its own queue, limits, and consumption policy.
Another benefit is operational fairness between stores. The pattern distributes processing in slices and prevents a large store from capturing most workers simply because it has more volume. It can receive more attention if policy allows it, but that becomes an explicit system decision, not a side effect of backlog.
Another benefit is operational governance. Because the attention worker goes through an enrichment step before consuming, it can check state, permissions, locks, maintenance, priority, and limits before spending effort processing messages.
The pattern also opens space for different commercial agreements. Because attention goes through an internal policy before becoming real consumption, the system can treat stores in different plans differently: more simultaneous consumers, larger consumption windows, more messages per cycle, higher priority when republishing attention, or specific rules for campaigns and seasonal dates.
A simple example:
| Plan | Simultaneous consumers per store | Messages per cycle |
|---|---|---|
| Basic | 1 | 50 |
| Pro | 3 | 200 |
| Enterprise | 10 | 1000 |
This allows processing capacity to become a commercial SLA without exposing queue complexity to the integrator.
There is also a resilience gain: if processing does not finish in one cycle, attention itself can be republished. Work progresses in slices, as in CPU time sharing. The system does not need to clear the entire backlog at once, and a very full queue does not hold a worker indefinitely.
In summary, the Attention Queue pattern is useful when there are many specific queues, irregular volume, a need for isolation, and a high cost to keep permanent consumers.
It transforms continuous processing into on-demand processing.
The attention queue does not carry the weight of the work. It carries the awareness that work exists.

Attention Queue: processamento sob demanda para filas granulares
Um padrão para consumir milhares de filas específicas sem manter milhares de consumidores ativos.
O problema
Imagine uma plataforma de e-commerce chamada MarketHub.
Ela integra milhares de lojas com marketplaces como Amazon, Mercado Livre, Shopee e outros canais de venda. Cada loja precisa sincronizar pedidos, estoque, preço, catálogo, notas de envio e eventos de pós-venda. Na maior parte do tempo, uma loja pequena gera pouco trabalho. Mas, quando uma loja grande faz uma atualização massiva de catálogo ou recebe uma rajada de pedidos em uma campanha, ela pode gerar milhares de tarefas em poucos minutos.
No MarketHub, cada loja tem sua própria fila de trabalho. Em termos simples, uma fila é uma lista persistente de mensagens esperando processamento. Um produtor coloca mensagens na fila; um consumidor lê essas mensagens e executa alguma ação. No nosso cenário, o produtor é a própria API do MarketHub, não o integrador externo.
Essa decisão não nasce de preferência estética pela granularidade. Ela existe porque lojas diferentes têm comportamentos, prioridades e riscos diferentes. Uma loja pequena não pode ficar atrás de milhares de atualizações de catálogo de uma loja muito grande. Uma loja com integração instável também não pode congestionar o processamento das demais. Além disso, a fila própria permite aplicar políticas específicas por loja: limite de consumo, pausa operacional, manutenção, descarte controlado, reprocessamento isolado, respeito a limites de API do marketplace e observabilidade direta do backlog daquela loja.
Em outras palavras, a fila por loja compra isolamento, previsibilidade e controle operacional.
Mas ela também cria uma nova tensão arquitetural: se cada loja tem sua fila, quem consome essas filas?
A primeira solução parece óbvia: criar consumidores permanentes para todas as filas de lojas. Um consumidor permanente seria um worker registrado o tempo todo naquela fila, aguardando novas mensagens.
Mas isso cria outro problema.
Se existem 50 mil lojas, não faz sentido manter 50 mil consumidores ativos, conexões abertas, prefetch configurado e recursos reservados para filas que, na maior parte do tempo, estão vazias. O sistema passa a gastar capacidade computacional esperando por trabalho que talvez nem exista.
O problema real não é apenas processar mensagens.
O problema é encontrar um modelo intermediário entre dois extremos ruins:
- consumidores permanentes demais
- ou uma fila centralizada demais.
A solução demanda que:
- O sistema precisa iniciar consumidores sob demanda para filas específicas,
- mas apenas quando houver algum indício de que existe trabalho pendente naquela fila.
- Também precisa decidir
- por quanto tempo cada consumidor temporário deve trabalhar,
- quantas mensagens ele deve tentar consumir,
- e como evitar que múltiplos workers processem a mesma fila de forma descontrolada.
Alternativas consideradas
Algumas soluções aparecem rapidamente.
A primeira é usar consumidores permanentes por fila. É simples de entender, mas escala mal quando há muitas filas granulares e baixo volume médio por fila.
A segunda é usar uma fila central única para todas as lojas. Isso reduz a quantidade de consumidores, mas perde isolamento. Uma loja ruidosa pode atrasar lojas menores, e políticas por loja ficam mais difíceis.
A terceira é criar agrupadores de filas centralizadas. Em vez de uma fila única para todas as lojas, o sistema poderia criar grupos menores, por exemplo process.marketplace.group_01.work, process.marketplace.group_02.work e assim por diante. Cada grupo receberia tarefas de algumas lojas. Essa abordagem parece um meio-termo: reduz a quantidade de filas e evita que todas as lojas disputem uma única fila global.
O problema é que o isolamento continua sendo parcial e acidental. Imagine que group_01 tenha 100 lojas. Se uma loja grande dentro desse grupo gera 1 milhão de jobs durante uma campanha, as outras 99 lojas ficam presas atrás dela ou passam a competir com ela dentro da mesma fila. O problema deixou de ser global, mas virou local: em vez de uma loja afetar a plataforma inteira, ela afeta todas as lojas do grupo.
Se a distribuição por grupo fica ruim, surge a necessidade de rebalancear lojas entre filas, o que adiciona operação, migração e risco. Além disso, políticas por loja continuam difíceis: limite de API, pausa de uma integração, prioridade comercial e reprocessamento isolado precisam ser reconstruídos dentro do consumidor, porque a fila já não representa uma única loja. O grupo melhora a fila única, mas não entrega isolamento real por loja.
A quarta é fazer polling periódico em todas as filas. Um scheduler varre as filas e processa as que têm mensagens. Funciona, mas introduz latência artificial, aumenta chamadas vazias ao broker e desperdiça ciclos quando há muitas filas inativas. Aqui, broker é o servidor de mensageria, como RabbitMQ, responsável por armazenar e entregar mensagens.
A quinta é fazer a API publicar mensagens diretamente em filas específicas e, junto com elas, publicar um pequeno sinal interno dizendo: esta fila precisa de atenção.
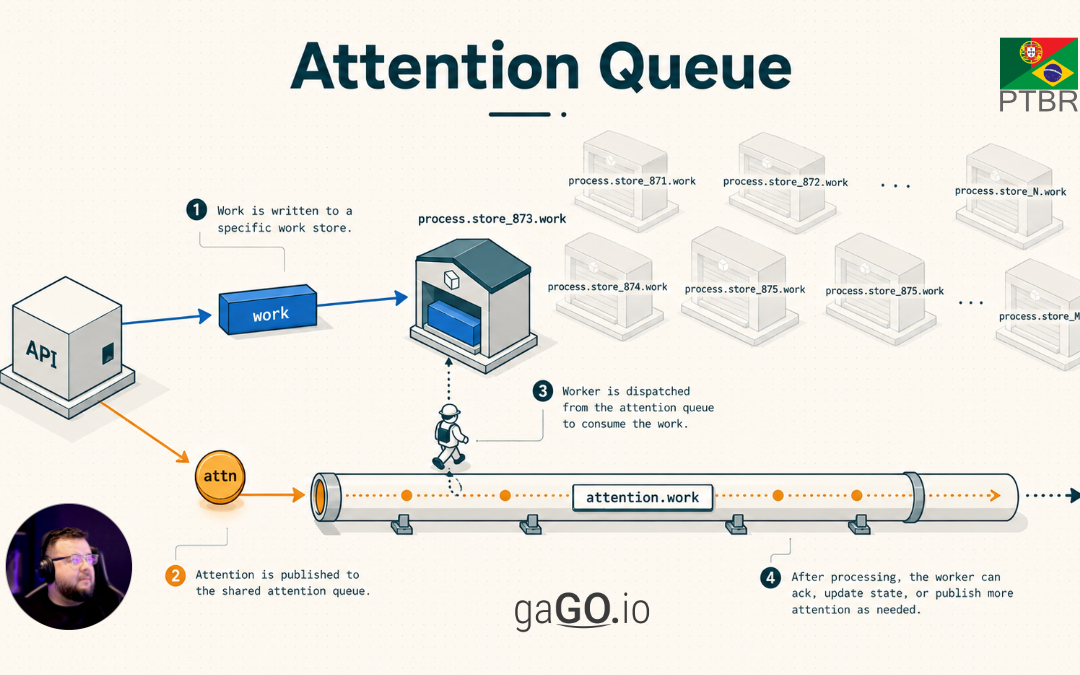
Essa é a solução que chamaremos de Attention Queue.
A ideia central é produzir dois tipos de mensagem dentro do sistema. Para o integrador externo, continua existindo uma única operação: uma chamada HTTP para a API, por exemplo para enviar uma atualização de estoque ou uma tarefa de sincronização. Depois que a API recebe e valida essa requisição, ela publica internamente duas mensagens. A primeira é a mensagem de trabalho: ela contém o dado real que precisa ser processado. A segunda é a mensagem de atenção: ela é menor e serve apenas para avisar ao próprio sistema que uma fila específica tem demanda pendente e precisa ser consumida.
| Tipo | Onde fica | O que contém | Para que serve |
|---|---|---|---|
| Mensagem de trabalho | Fila específica da loja | Payload real da tarefa, como atualização de estoque, pedido ou catálogo | Ser processada pela regra de negócio |
| Pedido de atenção | Fila compartilhada de atenção | Ponteiros mínimos, como tenant, loja, marketplace e prioridade | Acionar o consumo da fila de trabalho correta |
A mensagem real entra na fila específica do recurso. Essa fila é onde ficam os dados que efetivamente precisam ser processados. Por exemplo:
process.marketplace.store_873.work
Esse nome de fila é apenas uma convenção didática. A implementação pode escolher outro formato. O ponto essencial é que o pedido de atenção tenha dados suficientes para localizar, derivar ou consultar qual fila de trabalho precisa ser consumida.
O sinal entra em uma fila compartilhada de atenção. Essa fila não guarda o trabalho completo; ela guarda apenas avisos de que alguma fila específica precisa ser olhada. Por exemplo:
attention.marketplace.work
Esse sinal não contém o payload completo. Ele contém apenas o necessário para localizar a fila que precisa de atenção, ou seja, a fila que precisa ser consumida: tenant, tipo do recurso, id do recurso e algumas chaves de roteamento. Para um desenvolvedor .NET, esse sinal pode ser visto como um DTO pequeno, serializado em JSON e publicado internamente pelo próprio sistema.
Com isso, o sistema não precisa manter consumidores permanentes para todas as filas de trabalho. Ele mantém consumidores na fila de atenção. Quando uma mensagem de atenção chega, um worker usa esse aviso para localizar a fila específica, inicia um consumo temporário, consome por um tempo limitado ou até uma quantidade máxima de mensagens, e depois decide se o trabalho acabou ou se precisa republicar outra atenção.
Essa decisão de parar antes de consumir tudo é intencional. A inspiração vem do escalonamento de processos em sistemas operacionais, especialmente do conceito de time sharing. A CPU mantém processos prontos para executar e não deixa um único processo monopolizar o processador indefinidamente. Ela entrega uma fatia de tempo para um processo, interrompe, e depois dá oportunidade para outros processos avançarem. No Attention Queue, a fila de atenção faz um papel parecido com uma fila de processos prontos: cada mensagem de atenção representa uma fila de trabalho que quer uma fatia de processamento. Se ainda houver mensagens depois dessa fatia, a fila entra novamente na disputa por processamento por meio de uma nova mensagem de atenção.
O padrão não tenta ser apenas eficiente; ele tenta ser justo. Cada loja recebe fatias de processamento, evitando que uma loja grande capture a maior parte dos workers e transforme volume em privilégio operacional involuntário.
Como funciona
O padrão funciona como um despachante interno.
Ele não processa o trabalho diretamente. Ele aponta onde existe trabalho. Em uma aplicação .NET, pense nele como um BackgroundService ou worker que recebe um comando pequeno e, a partir dele, decide qual fila de trabalho deve ser consumida.
Em vez de perguntar o tempo todo se há mensagens em cada fila, o sistema recebe um sinal quando algo novo chega. Em vez de deixar um consumidor eterno parado em uma fila vazia, ele inicia um consumidor temporário apenas quando há motivo para isso.
Um fluxo típico seria:
- Um integrador faz uma chamada HTTP para a API do MarketHub solicitando uma sincronização ou enviando uma atualização.
- A API valida a requisição e publica internamente a tarefa na fila
process.marketplace.store_873.work. - Na mesma operação interna, a API publica um sinal em
attention.marketplace.work. - Um worker consome esse sinal de atenção.
- O worker consulta o estado da loja ou integração relacionada.
- Se a loja está desativada, em manutenção, bloqueada por erro de credencial ou removida, a atenção é descartada.
- Se a loja está válida, o worker calcula os limites de consumo: tempo máximo, quantidade máxima de mensagens e concorrência permitida.
- O worker tenta adquirir permissão de rate limit para evitar excesso de consumidores simultâneos na mesma fila. Nesse contexto, rate limit é apenas uma trava de capacidade: quantos consumidores podem trabalhar naquela fila ao mesmo tempo. Esse limite pode ser 1, quando a fila precisa ser consumida de forma serial, ou pode ser maior, como 5 ou 10, quando o domínio permite paralelismo seguro.
- Se permitido, ele inicia um consumidor temporário na fila específica da loja.
- Ele processa mensagens até atingir uma das condições de parada: tempo máximo, quantidade máxima, erro operacional ou fila vazia.
- Ao final, ele verifica se ainda há backlog. Se houver, republica uma nova atenção na fila de atenção. Se não houver, encerra.
- A nova atenção volta para a mesma fila compartilhada de atenção e será consumida no próximo ciclo por algum worker disponível. Pode ser o mesmo worker ou outro. O ponto é que a fila de uma loja grande não monopoliza o processamento indefinidamente.
Encontrar a fila vazia não é erro. Uma atenção pode chegar atrasada: quando o worker olha a fila de trabalho, ela já pode ter sido consumida por outro ciclo. Nesse caso, ele apenas confirma a atenção e encerra.
O ponto importante é que o sinal de atenção é barato, pequeno e repetível.
Ele não precisa representar exatamente uma mensagem de trabalho. Ele representa uma intenção: essa fila merece ser observada e provavelmente precisa ser consumida.
Por isso, o pedido de atenção deve ser idempotente. O sistema precisa aceitar a possibilidade de receber duas ou mais atenções para a mesma loja sem duplicar processamento indevido. No pior caso, uma atenção extra inicia uma tentativa que encontra a fila vazia, é bloqueada pelo limite de concorrência, ou percebe que o backlog já foi processado por outro ciclo.
Isso muda a forma de pensar. A fila de atenção não é a fila de trabalho. Ela é a fila de coordenação. Ela funciona como uma fila de escalonamento: decide qual fila de trabalho recebe a próxima fatia de processamento.
Exemplo completo
No MarketHub, cada loja possui uma fila própria:
process.marketplace.store_{storeId}.work
O conjunto de integrações com marketplaces possui uma fila de atenção:
attention.marketplace.work
Quando a loja store-873 precisa sincronizar pedidos ou atualizar estoque em um marketplace, o integrador faz uma única chamada HTTP para a API. Para quem integra, a operação termina aí: ele enviou a solicitação para o MarketHub. Quem sabe que também precisa gerar um pedido de atenção é a própria API.
Depois de receber a chamada HTTP, a API faz duas publicações internas no broker. Essa dupla publicação precisa ser tratada como uma unidade operacional: não basta publicar a mensagem de trabalho e torcer para que o pedido de atenção também seja publicado. Se a primeira publicação funcionar e a segunda falhar, a fila da loja pode ficar com trabalho pendente sem nenhum sinal para acionar o consumo.
Existem várias formas de proteger esse ponto, dependendo do nível de garantia exigido pela aplicação: usar confirmação de publicação do broker, aplicar outbox pattern, fazer retry idempotente da publicação de atenção ou manter uma reconciliação periódica que encontre filas com backlog sem atenção recente. O detalhe da técnica pode variar, mas a decisão arquitetural é a mesma: mensagem de trabalho e pedido de atenção fazem parte da mesma intenção operacional.
Nos exemplos abaixo, aparecem três termos comuns em RabbitMQ. O exchange é o ponto onde a aplicação publica a mensagem. A routingKey é a chave usada para decidir o caminho da mensagem. A queue é a fila onde a mensagem fica armazenada até algum consumidor processá-la.
A primeira publicação carrega o trabalho real:
exchange: process.marketplace routingKey: store.store-873 body: tarefa completa de sincronização
A segunda publicação carrega apenas o pedido de atenção:
{
"tenantId": "seller-group-a",
"storeId": "store-873",
"marketplace": "mercado-livre",
"priority": "normal"
}
O worker de atenção recebe esse segundo evento e monta a fila real:
process.marketplace.store_873.work
Antes de consumir, aplica uma política:
maxConsumptionTimeSeconds = 20 maxMessages = 100 maxConcurrentConsumers = 2
Nesse exemplo, maxConcurrentConsumers = 2 significa que no máximo dois consumidores podem processar a fila dessa loja ao mesmo tempo. Em outro cenário, esse valor poderia ser 1, garantindo um único consumidor ativo por fila de trabalho. Isso é útil quando a ordem dos eventos importa, quando há risco de conflito em atualizações de estoque, ou quando a API do marketplace exige chamadas mais controladas. Se a loja tiver um plano maior, integração estável e operações independentes, o limite poderia ser 10.
Então ele tenta adquirir um token de concorrência para essa loja. Se já existem consumidores suficientes processando essa fila, a atenção é republicada para uma tentativa futura.
Se houver permissão, o worker consome até 100 mensagens ou até 20 segundos. Ele não continua até o fim da fila porque isso permitiria que uma única loja ruidosa ocupasse o worker por tempo demais. Se ainda restarem mensagens, ele republica uma nova atenção. Essa nova atenção volta para attention.marketplace.work e será disputada pelos consumidores dessa fila de atenção. Se a fila estiver vazia, ele encerra.
Implementação
O padrão pode ser implementado com cinco componentes.
Ele não exige uma abstração genérica de mensageria. Os exemplos a seguir usam vocabulário comum em aplicações .NET e RabbitMQ, mas a parte mais importante é o contrato explícito do domínio: uma mensagem de trabalho, uma mensagem de atenção, um worker que entende esse contrato e uma política clara de consumo.
O primeiro é a fila de trabalho granular. Ela guarda mensagens reais por entidade, cliente, loja, conta ou qualquer unidade que precise de isolamento. É nela que está o payload que a regra de negócio vai processar.
O segundo é a fila de atenção agregada. Ela recebe sinais pequenos agrupados por tipo. Essa fila é consumida por poucos workers permanentes.
O terceiro é o envelope de atenção. Ele contém os identificadores mínimos para localizar a fila de trabalho que precisa de atenção. Esse envelope deve ser seguro para repetição: publicar ou consumir o mesmo pedido mais de uma vez não pode corromper o estado do sistema. Em C#, ele seria uma classe simples, por exemplo:
public sealed class AttentionRequest
{
public required string TenantId { get; init; }
public required string StoreId { get; init; }
public required string Marketplace { get; init; }
}
O quarto é o worker de atenção. Ele valida o estado da entidade, inicia um consumidor temporário, processa em lote controlado e decide se precisa de nova atenção. Esse worker não precisa esconder RabbitMQ atrás de uma abstração genérica; ele pode chamar APIs explícitas do broker ou serviços internos próprios.
O quinto é o controle de concorrência. Ele normalmente é apoiado por Redis, banco de dados ou lock distribuído, para impedir que múltiplos workers processem a mesma fila além do limite permitido. Esse limite não precisa ser maior que 1. Em muitos casos, o valor correto é exatamente 1 consumidor ativo por fila de trabalho. Em outros, o limite pode ser 10 ou mais, desde que o processamento seja independente, idempotente e seguro para paralelismo.
Em uma base .NET, esses componentes poderiam aparecer como contratos próprios do sistema:
public interface IAttentionPublisher
{
Task PublishAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public interface IAttentionWorker
{
Task<AttentionResult> ProcessAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public enum AttentionResult
{
Done,
NeedMoreAttention
}
Essas interfaces não precisam prometer que servem para qualquer broker ou qualquer caso de mensageria. Elas existem para representar uma decisão arquitetural específica: publicar pedidos de atenção e consumir filas de trabalho sob demanda.
Um pseudocódigo possível:
No pseudocódigo, ack attention significa confirmar ao broker que aquela mensagem de atenção foi tratada e pode sair da fila. Se o worker falhar antes do ack, o broker pode tentar entregar a mesma atenção de novo, dependendo da configuração. Esse é mais um motivo para o pedido de atenção ser idempotente. O oposto do ack costuma ser chamado de nack, usado quando a mensagem não foi processada com sucesso e deve seguir a política de erro ou retentativa.
on attention_received(attention):
resource = load_resource(attention.resource_id)
if resource cannot receive processing:
ack attention
return
queue_name = build_work_queue_name(resource)
if rate_limit_blocked(queue_name):
republish attention
ack attention
return
if queue_does_not_exist(queue_name):
ack attention
return
if queue_is_empty(queue_name):
ack attention
return
consume_until(
queue = queue_name,
max_messages = resource.max_messages,
max_time = resource.max_time
)
if queue_has_remaining_messages(queue_name):
republish attention
ack attention
O republish attention não é uma recursão nem uma chamada imediata ao mesmo worker. Ele coloca um novo pedido no fim da fila de atenção. Depois disso, o worker atual finaliza o ciclo e fica livre para pegar o próximo pedido disponível. O broker entrega a nova atenção quando ela chegar à vez dela, respeitando a concorrência e a ordem operacional da fila.
Em RabbitMQ, uma implementação concreta pode usar uma topologia semelhante. O binding é a regra que liga um exchange a uma queue.
exchange: attention.marketplace queue: attention.marketplace.work binding: store.* exchange: process.marketplace queue: process.marketplace.store_873.work binding: store.store-873
A API publica o payload completo na fila de trabalho e publica um envelope pequeno na fila de atenção:
HTTP request from integrator API validates request API publishes process event API publishes attention event
Na implementação real, esses dois últimos passos devem ter uma estratégia explícita de consistência. Se não houver uma transação única envolvendo tudo, a aplicação precisa de confirmação, retry, outbox ou reconciliação para não deixar trabalho sem atenção.
O worker de atenção, por sua vez, não precisa conhecer todas as lojas antecipadamente. Ele só precisa saber transformar o envelope de atenção em nome de fila, política de consumo e chave de controle de concorrência.
Observabilidade
Attention Queue só é confortável de operar quando o sistema mostra claramente onde há trabalho parado, onde há excesso de atenção e onde há bloqueio por política.
Algumas métricas úteis:
| Métrica | O que revela |
|---|---|
| Quantidade de mensagens por fila de loja | Quais lojas estão acumulando backlog |
| Idade da mensagem mais antiga por fila | Há quanto tempo a loja mais atrasada espera processamento |
| Número de atenções republicadas | Quais filas precisam de muitos ciclos para esvaziar |
| Atenções descartadas por loja desativada ou inválida | Quanto trabalho está sendo ignorado por estado operacional |
| Bloqueios por rate limit | Quais lojas estão batendo no limite de concorrência ou SLA |
| Tempo médio para zerar backlog | Quanto tempo o sistema leva para recuperar uma fila com trabalho pendente |
Essas métricas ajudam a separar problemas diferentes. Uma loja pode estar lenta porque tem backlog real, porque está limitada por plano, porque a integração está bloqueada, porque há muitas atenções repetidas, ou porque os workers disponíveis não são suficientes. Sem essas medidas, o padrão continua funcionando, mas fica difícil explicar seu comportamento em produção.
Quando não usar
Attention Queue não deve ser tratado como solução padrão para qualquer processamento assíncrono.
Se o sistema tem poucas filas, volume previsível e consumidores permanentes baratos de manter, o padrão pode adicionar complexidade desnecessária. Se uma fila única já atende bem, com latência aceitável e sem problemas de isolamento, talvez não exista dor suficiente para justificar filas granulares e pedidos de atenção.
Também não é uma boa escolha quando o processamento precisa obedecer uma ordem estritamente global entre todas as mensagens. O padrão favorece isolamento e justiça entre filas, não uma ordenação única do sistema inteiro.
Outro ponto é custo operacional. Filas dinâmicas exigem convenção de nomes, criação, remoção, monitoramento e capacidade de diagnóstico. Se o broker ou o time ainda não consegue operar muitas filas com segurança, é melhor amadurecer essa base antes de adotar o padrão.
Benefícios
O benefício principal do padrão é alinhar consumo com necessidade real.
Ele permite manter milhares ou milhões de filas lógicas sem exigir milhares ou milhões de consumidores ativos. O sistema fica mais elástico porque consumidores aparecem quando há backlog e desaparecem quando o trabalho acaba.
Também melhora o isolamento. Uma entidade ruidosa não precisa contaminar o fluxo das demais, porque cada entidade pode ter sua fila, seus limites e sua política de consumo.
Outro benefício é justiça operacional, ou fairness, entre lojas. O padrão distribui o processamento em fatias e evita que uma loja grande capture a maior parte dos workers apenas por ter mais volume. Ela pode receber mais atenção se a política permitir, mas isso passa a ser uma decisão explícita do sistema, não um efeito colateral do backlog.
Outro benefício é a governança operacional. Como o worker de atenção passa por uma etapa de enriquecimento antes de consumir, ele pode verificar estado, permissões, locks, manutenção, prioridade e limites antes de gastar esforço processando mensagens.
O padrão também abre espaço para acordos comerciais diferentes. Como a atenção passa por uma política interna antes de virar consumo real, o sistema pode dar tratamento diferente para lojas em planos diferentes: mais consumidores simultâneos, janelas de consumo maiores, mais mensagens por ciclo, prioridade maior na republicação da atenção ou regras específicas para campanhas e datas sazonais.
Um exemplo simples:
| Plano | Consumidores simultâneos por loja | Mensagens por ciclo |
|---|---|---|
| Basic | 1 | 50 |
| Pro | 3 | 200 |
| Enterprise | 10 | 1000 |
Isso permite transformar capacidade de processamento em SLA comercial sem expor a complexidade de filas para o integrador.
Há também um ganho de resiliência: se o processamento não terminar em um ciclo, a própria atenção pode ser republicada. O trabalho progride em fatias, como no time sharing da CPU. O sistema não precisa resolver todo o backlog de uma vez, e uma fila muito cheia não prende o worker indefinidamente.
Em resumo, o padrão Attention Queue é útil quando há muitas filas específicas, volume irregular, necessidade de isolamento e custo alto para manter consumidores permanentes.
Ele transforma processamento contínuo em processamento sob demanda.
A fila de atenção não carrega o peso do trabalho. Ela carrega a consciência de que existe trabalho.

Circular Buffer, Ring Buffer, ObjectPool e Objects Pools Elásticos
Segunda-feira, 14h. Pico de tráfego. Sua aplicação .NET começa a derreter conexões com o RabbitMQ. Você abre o Grafana, vê 800 conexões abertas contra um broker que aguenta confortavelmente 50, e a hipótese imediata é “vamos limitar o pool”. Alguém sobe um SemaphoreSlim, faz deploy, e na quarta-feira o problema inverte: as conexões caem para duas, ficam ociosas, e quando o próximo burst chega, a latência explode porque cada nova publicação está pagando 200ms de handshake TLS + AMQP.
Esse vai-e-volta é o sintoma.
A causa é mais profunda: recursos caros e voláteis estão sendo tratados como recursos baratos e estáveis.
E quase nenhuma abstração padrão do .NET lida bem com isso.
… até hoje!
ler mais…
OA03 – Fazemos o que precisa ser feito e arcamos com as consequências das decisões que tomamos
Seu time quer publicar pacotes NuGet mas não quer manter um NuGet Server. Quer rodar containers mas não quer contratar um Container Registry. Quer processar mensagens assíncronas mas acha que uma tabela com coluna status no PostgreSQL resolve.
A pergunta que ninguém faz é: por que você está adotando uma solução cujo custo operacional mínimo você se recusa a pagar?
ler mais…
OA02 – Governança Arquitetural e Open Architecture- Você não pode esperar proatividade, muito menos de quem não tem acesso
As 7 regras que uso para governar componentes arquiteturais em projetos .NET de grande porte — e filtrar quem realmente está pronto para evoluir a arquitetura.
Existe uma expectativa velada em muitos times de desenvolvimento: a de que bons desenvolvedores simplesmente “se envolvem” com a arquitetura. Que eles naturalmente vão questionar decisões, propor melhorias e contribuir para a evolução técnica do projeto.
Mas aqui está o problema que quase ninguém está disposto a falar: como alguém pode ser proativo em relação a algo que não conhece, não enxerga e não tem acesso?
ler mais…Arquitetura
Attention Queue: on-demand processing for granular queues
Consume thousands of specific queues without keeping thousands of active consumers.
The Problem
Imagine an e-commerce platform called MarketHub.
It integrates thousands of stores with marketplaces such as Amazon, eBay, Walmart Marketplace, and other sales channels. Each store needs to synchronize orders, inventory, prices, catalog data, shipping updates, and post-sale events. Most of the time, a small store generates little work. But when a large store performs a massive catalog update or receives a burst of orders during a campaign, it can generate thousands of tasks within minutes.
In MarketHub, each store has its own work queue. In simple terms, a queue is a persistent list of messages waiting to be processed. A producer puts messages into the queue; a consumer reads those messages and performs some action. In this scenario, the producer is MarketHub’s own API, not the external integrator.
This decision is not about aesthetic preference for granularity. It exists because different stores have different behaviors, priorities, and risks. A small store should not sit behind thousands of catalog updates from a very large store. A store with an unstable integration should not congest processing for the others. Also, a dedicated queue allows store-specific policies: consumption limits, operational pauses, maintenance, controlled discard, isolated reprocessing, respect for marketplace API limits, and direct observability into that store’s backlog.
In other words, a queue per store buys isolation, predictability, and operational control.
But it also creates a new architectural tension: if every store has its own queue, who consumes those queues?
The first solution seems obvious: create permanent consumers for every store queue. A permanent consumer would be a worker registered on that queue all the time, waiting for new messages.
But that creates another problem.
If there are 50,000 stores, it does not make sense to keep 50,000 active consumers, open connections, configured prefetch, and reserved resources for queues that are empty most of the time. The system starts spending compute capacity waiting for work that may not exist.
The real problem is not just processing messages.
The problem is finding an intermediate model between two bad extremes: too many permanent consumers or an overly centralized queue. The system needs to start consumers on demand for specific queues, but only when there is some indication that work is pending in that queue. It also needs to decide how long each temporary consumer should work, how many messages it should try to consume, and how to prevent multiple workers from processing the same queue in an uncontrolled way.
Considered Alternatives
Several solutions appear quickly.
The first is to use permanent consumers per queue. It is simple to understand, but it scales poorly when there are many granular queues and low average volume per queue.
The second is to use a single central queue for all stores. This reduces the number of consumers, but loses isolation. A noisy store can delay smaller stores, and store-specific policies become harder.
The third is to create grouped centralized queues. Instead of one queue for all stores, the system could create smaller groups, for example process.marketplace.group_01.work, process.marketplace.group_02.work, and so on. Each group would receive tasks from some stores. This approach looks like a middle ground: it reduces the number of queues and avoids making all stores compete in one global queue.
The problem is that isolation remains partial and accidental. Imagine group_01 has 100 stores. If one large store inside that group generates 1 million jobs during a campaign, the other 99 stores are stuck behind it or forced to compete with it inside the same queue. The problem is no longer global, but it became local: instead of one store affecting the whole platform, it affects every store in the group.
If group distribution becomes poor, teams need to rebalance stores across queues, which adds operations, migration, and risk. Also, store-specific policies remain difficult: API limits, pausing one integration, commercial priority, and isolated reprocessing need to be rebuilt inside the consumer, because the queue no longer represents a single store. Grouping improves the single-queue approach, but does not provide real isolation per store.
The fourth is to periodically poll all queues. A scheduler scans queues and processes the ones that have messages. It works, but it introduces artificial latency, increases empty calls to the broker, and wastes cycles when many queues are inactive. Here, broker means the messaging server, such as RabbitMQ, responsible for storing and delivering messages.
The fifth is to make the API publish messages directly to specific queues and, along with them, publish a small internal signal saying: this queue needs attention.
That is the solution we will call Attention Queue.
The core idea is to produce two types of messages inside the system. For the external integrator, there is still a single operation: an HTTP call to the API, for example to send an inventory update or synchronization task. After the API receives and validates that request, it internally publishes two messages. The first is the work message: it contains the real data that needs to be processed. The second is the attention message: it is smaller and only serves to tell the system itself that a specific queue has pending demand and needs to be consumed.
| Type | Where it lives | What it contains | What it is for |
|---|---|---|---|
| Work message | Store-specific queue | Real task payload, such as inventory update, order, or catalog data | To be processed by business logic |
| Attention request | Shared attention queue | Minimal pointers, such as tenant, store, marketplace, and priority | To trigger consumption of the correct work queue |
The real message enters the resource-specific queue. That queue is where the data that actually needs to be processed waits. For example:
process.marketplace.store_873.work
This queue name is only a didactic convention. An implementation can choose another format. The essential point is that the attention request has enough data to locate, derive, or query which work queue needs to be consumed.
The signal enters a shared attention queue. This queue does not store the complete work; it only stores notices that some specific queue needs to be inspected. For example:
attention.marketplace.work
That signal does not contain the full payload. It contains only what is needed to locate the queue that needs attention, meaning the queue that needs to be consumed: tenant, resource type, resource id, and some routing keys. For a .NET developer, this signal can be seen as a small DTO, serialized as JSON and published internally by the system itself.
With this, the system does not need to keep permanent consumers for every work queue. It keeps consumers on the attention queue. When an attention message arrives, a worker uses that notice to locate the specific queue, starts a temporary consumption cycle, consumes for a limited time or up to a maximum number of messages, and then decides whether the work is done or whether it needs to republish another attention request.
This decision to stop before consuming everything is intentional. The inspiration comes from process scheduling in operating systems, especially the concept of time sharing. The CPU keeps processes ready to run and does not allow a single process to monopolize the processor indefinitely. It gives one process a time slice, interrupts it, and then gives other processes a chance to advance. In Attention Queue, the attention queue plays a similar role to a ready queue: each attention message represents a work queue asking for a processing slice. If there are still messages after that slice, the queue enters the processing competition again through a new attention message.
The pattern is not only trying to be efficient; it is trying to be fair. Each store receives processing slices, preventing a large store from capturing most workers and turning volume into unintended operational privilege.
How It Works
The pattern works like an internal dispatcher.
It does not process the work directly. It points to where work exists. In a .NET application, think of it as a BackgroundService or worker that receives a small command and, from that command, decides which work queue should be consumed.
Instead of constantly asking whether each queue has messages, the system receives a signal when something new arrives. Instead of leaving an eternal consumer sitting on an empty queue, it starts a temporary consumer only when there is a reason to do so.
A typical flow would be:
- An integrator makes an HTTP call to the MarketHub API requesting a synchronization or sending an update.
- The API validates the request and internally publishes the task to
process.marketplace.store_873.work. - In the same internal operation, the API publishes a signal to
attention.marketplace.work. - A worker consumes that attention signal.
- The worker checks the state of the related store or integration.
- If the store is disabled, under maintenance, blocked due to credential errors, or removed, the attention is discarded.
- If the store is valid, the worker calculates the consumption limits: maximum time, maximum number of messages, and allowed concurrency.
- The worker tries to acquire rate-limit permission to avoid too many simultaneous consumers on the same queue. In this context, rate limit is just a capacity gate: how many consumers can work on that queue at the same time. This limit can be 1 when the queue must be consumed serially, or it can be higher, such as 5 or 10, when the domain allows safe parallelism.
- If allowed, it starts a temporary consumer on the store-specific queue.
- It processes messages until one of the stop conditions is reached: maximum time, maximum message count, operational error, or empty queue.
- At the end, it checks whether there is still backlog. If there is, it republishes a new attention request to the attention queue. If not, it stops.
- The new attention returns to the same shared attention queue and will be consumed in the next cycle by some available worker. It may be the same worker or another one. The point is that one large store’s queue does not monopolize processing indefinitely.
Finding the work queue empty is not an error. An attention request can arrive late: when the worker checks the work queue, it may already have been consumed by another cycle. In that case, the worker simply acknowledges the attention and stops.
The important point is that the attention signal is cheap, small, and repeatable.
It does not need to represent exactly one work message. It represents an intention: this queue deserves to be observed and probably needs to be consumed.
For that reason, the attention request must be idempotent. The system must tolerate receiving two or more attention requests for the same store without causing improper duplicate processing. In the worst case, an extra attention starts an attempt that finds the queue empty, is blocked by the concurrency limit, or notices that the backlog was already processed by another cycle.
This changes how we think about the design. The attention queue is not the work queue. It is the coordination queue. It works like a scheduling queue: it decides which work queue receives the next processing slice.
Complete Example
In MarketHub, each store has its own queue:
process.marketplace.store_{storeId}.work
The marketplace integration set has an attention queue:
attention.marketplace.work
When store store-873 needs to synchronize orders or update inventory in a marketplace, the integrator makes a single HTTP call to the API. For the integrator, the operation ends there: it sent the request to MarketHub. The API itself knows that it also needs to generate an attention request.
After receiving the HTTP call, the API performs two internal publications to the broker. This double publication must be treated as one operational unit: it is not enough to publish the work message and hope the attention request is also published. If the first publication succeeds and the second one fails, the store queue may contain pending work with no signal to trigger consumption.
There are several ways to protect this point, depending on the level of guarantee required by the application: use broker publish confirmations, apply the outbox pattern, perform idempotent retry of the attention publication, or keep a periodic reconciliation process that finds queues with backlog and no recent attention. The specific technique may vary, but the architectural decision is the same: the work message and the attention request are part of the same operational intent.
The examples below use three common RabbitMQ terms. The exchange is the point where the application publishes the message. The routingKey is the key used to decide the message path. The queue is where the message stays stored until some consumer processes it.
The first publication carries the real work:
exchange: process.marketplace routingKey: store.store-873 body: complete synchronization task
The second publication carries only the attention request:
{
"tenantId": "seller-group-a",
"storeId": "store-873",
"marketplace": "amazon",
"priority": "normal"
}
The attention worker receives this second event and builds the real queue:
process.marketplace.store_873.work
Before consuming, it applies a policy:
maxConsumptionTimeSeconds = 20 maxMessages = 100 maxConcurrentConsumers = 2
In this example, maxConcurrentConsumers = 2 means at most two consumers can process that store queue at the same time. In another scenario, this value could be 1, guaranteeing a single active consumer per work queue. That is useful when event order matters, when there is risk of conflict in inventory updates, or when the marketplace API requires more controlled calls. If the store has a higher plan, stable integration, and independent operations, the limit could be 10.
Then it tries to acquire a concurrency token for that store. If enough consumers are already processing that queue, the attention is republished for a future attempt.
If allowed, the worker consumes up to 100 messages or up to 20 seconds. It does not continue until the queue is empty because that would allow one noisy store to occupy the worker for too long. If messages remain, it republishes a new attention request. That new attention returns to attention.marketplace.work and will be competed for by the consumers of that attention queue. If the queue is empty, the worker stops.
Implementation
The pattern can be implemented with five components.
It does not require a generic messaging abstraction. The examples below use common .NET and RabbitMQ vocabulary, but the most important part is the explicit domain contract: a work message, an attention message, a worker that understands that contract, and a clear consumption policy.
The first is the granular work queue. It stores real messages per entity, customer, store, account, or any unit that needs isolation. This is where the payload that business logic will process lives.
The second is the aggregated attention queue. It receives small signals grouped by type. This queue is consumed by a small number of permanent workers.
The third is the attention envelope. It contains the minimum identifiers needed to locate the work queue that needs attention. This envelope must be safe to repeat: publishing or consuming the same request more than once must not corrupt system state. In C#, it could be a simple class, for example:
public sealed class AttentionRequest
{
public required string TenantId { get; init; }
public required string StoreId { get; init; }
public required string Marketplace { get; init; }
}
The fourth is the attention worker. It validates entity state, starts a temporary consumer, processes a controlled batch, and decides whether more attention is needed. This worker does not need to hide RabbitMQ behind a generic abstraction; it can call explicit broker APIs or internal services.
The fifth is concurrency control. It is usually backed by Redis, a database, or a distributed lock, to prevent multiple workers from processing the same queue beyond the allowed limit. This limit does not need to be greater than 1. In many cases, the correct value is exactly 1 active consumer per work queue. In others, the limit can be 10 or more, as long as processing is independent, idempotent, and safe for parallelism.
In a .NET codebase, these components could appear as domain-specific contracts:
public interface IAttentionPublisher
{
Task PublishAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public interface IAttentionWorker
{
Task<AttentionResult> ProcessAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public enum AttentionResult
{
Done,
NeedMoreAttention
}
These interfaces do not need to promise that they work for any broker or every messaging use case. They exist to represent a specific architectural decision: publish attention requests and consume work queues on demand.
One possible pseudocode:
In the pseudocode, ack attention means confirming to the broker that the attention message was handled and can leave the queue. If the worker fails before the ack, the broker may try to deliver the same attention again, depending on configuration. This is another reason why the attention request must be idempotent. The opposite of ack is usually called nack, used when the message was not successfully processed and should follow the error or retry policy.
on attention_received(attention):
resource = load_resource(attention.resource_id)
if resource cannot receive processing:
ack attention
return
queue_name = build_work_queue_name(resource)
if rate_limit_blocked(queue_name):
republish attention
ack attention
return
if queue_does_not_exist(queue_name):
ack attention
return
if queue_is_empty(queue_name):
ack attention
return
consume_until(
queue = queue_name,
max_messages = resource.max_messages,
max_time = resource.max_time
)
if queue_has_remaining_messages(queue_name):
republish attention
ack attention
The republish attention step is not recursion and not an immediate call to the same worker. It places a new request at the end of the attention queue. After that, the current worker finishes the cycle and becomes free to pick up the next available request. The broker delivers the new attention when its turn comes, respecting concurrency and the operational order of the queue.
In RabbitMQ, a concrete implementation can use a topology like this. The binding is the rule that connects an exchange to a queue.
exchange: attention.marketplace queue: attention.marketplace.work binding: store.* exchange: process.marketplace queue: process.marketplace.store_873.work binding: store.store-873
The API publishes the full payload to the work queue and publishes a small envelope to the attention queue:
HTTP request from integrator API validates request API publishes process event API publishes attention event
In a real implementation, these last two steps must have an explicit consistency strategy. If there is no single transaction covering everything, the application needs confirmations, retry, outbox, or reconciliation to avoid leaving work without attention.
The attention worker, in turn, does not need to know every store ahead of time. It only needs to know how to transform the attention envelope into a queue name, consumption policy, and concurrency-control key.
Observability
Attention Queue is comfortable to operate only when the system clearly shows where work is stuck, where there is too much attention, and where policy is blocking consumption.
Useful metrics include:
| Metric | What it reveals |
|---|---|
| Message count per store queue | Which stores are accumulating backlog |
| Age of the oldest message per queue | How long the most delayed store has been waiting for processing |
| Number of republished attentions | Which queues need many cycles to empty |
| Attentions discarded because the store is disabled or invalid | How much work is being ignored due to operational state |
| Rate-limit blocks | Which stores are hitting concurrency or SLA limits |
| Average time to clear backlog | How long the system takes to recover a queue with pending work |
These metrics help separate different problems. A store may be slow because it has real backlog, because it is limited by plan, because the integration is blocked, because there are too many repeated attentions, or because available workers are not enough. Without these measurements, the pattern still works, but explaining its behavior in production becomes difficult.
When Not To Use It
Attention Queue should not be treated as the default solution for every asynchronous processing problem.
If the system has few queues, predictable volume, and permanent consumers that are cheap to maintain, the pattern may add unnecessary complexity. If a single queue already works well, with acceptable latency and no isolation problems, there may not be enough pain to justify granular queues and attention requests.
It is also not a good choice when processing must obey a strictly global order across all messages. The pattern favors isolation and fairness across queues, not one single ordering for the whole system.
Another point is operational cost. Dynamic queues require naming conventions, creation, removal, monitoring, and diagnostic capability. If the broker or the team cannot yet operate many queues safely, it is better to mature that foundation before adopting the pattern.
Benefits
The main benefit of the pattern is aligning consumption with real demand.
It allows the system to maintain thousands or millions of logical queues without requiring thousands or millions of active consumers. The system becomes more elastic because consumers appear when there is backlog and disappear when work is done.
It also improves isolation. A noisy entity does not need to contaminate the flow of others, because each entity can have its own queue, limits, and consumption policy.
Another benefit is operational fairness between stores. The pattern distributes processing in slices and prevents a large store from capturing most workers simply because it has more volume. It can receive more attention if policy allows it, but that becomes an explicit system decision, not a side effect of backlog.
Another benefit is operational governance. Because the attention worker goes through an enrichment step before consuming, it can check state, permissions, locks, maintenance, priority, and limits before spending effort processing messages.
The pattern also opens space for different commercial agreements. Because attention goes through an internal policy before becoming real consumption, the system can treat stores in different plans differently: more simultaneous consumers, larger consumption windows, more messages per cycle, higher priority when republishing attention, or specific rules for campaigns and seasonal dates.
A simple example:
| Plan | Simultaneous consumers per store | Messages per cycle |
|---|---|---|
| Basic | 1 | 50 |
| Pro | 3 | 200 |
| Enterprise | 10 | 1000 |
This allows processing capacity to become a commercial SLA without exposing queue complexity to the integrator.
There is also a resilience gain: if processing does not finish in one cycle, attention itself can be republished. Work progresses in slices, as in CPU time sharing. The system does not need to clear the entire backlog at once, and a very full queue does not hold a worker indefinitely.
In summary, the Attention Queue pattern is useful when there are many specific queues, irregular volume, a need for isolation, and a high cost to keep permanent consumers.
It transforms continuous processing into on-demand processing.
The attention queue does not carry the weight of the work. It carries the awareness that work exists.
Attention Queue: processamento sob demanda para filas granulares
Um padrão para consumir milhares de filas específicas sem manter milhares de consumidores ativos.
O problema
Imagine uma plataforma de e-commerce chamada MarketHub.
Ela integra milhares de lojas com marketplaces como Amazon, Mercado Livre, Shopee e outros canais de venda. Cada loja precisa sincronizar pedidos, estoque, preço, catálogo, notas de envio e eventos de pós-venda. Na maior parte do tempo, uma loja pequena gera pouco trabalho. Mas, quando uma loja grande faz uma atualização massiva de catálogo ou recebe uma rajada de pedidos em uma campanha, ela pode gerar milhares de tarefas em poucos minutos.
No MarketHub, cada loja tem sua própria fila de trabalho. Em termos simples, uma fila é uma lista persistente de mensagens esperando processamento. Um produtor coloca mensagens na fila; um consumidor lê essas mensagens e executa alguma ação. No nosso cenário, o produtor é a própria API do MarketHub, não o integrador externo.
Essa decisão não nasce de preferência estética pela granularidade. Ela existe porque lojas diferentes têm comportamentos, prioridades e riscos diferentes. Uma loja pequena não pode ficar atrás de milhares de atualizações de catálogo de uma loja muito grande. Uma loja com integração instável também não pode congestionar o processamento das demais. Além disso, a fila própria permite aplicar políticas específicas por loja: limite de consumo, pausa operacional, manutenção, descarte controlado, reprocessamento isolado, respeito a limites de API do marketplace e observabilidade direta do backlog daquela loja.
Em outras palavras, a fila por loja compra isolamento, previsibilidade e controle operacional.
Mas ela também cria uma nova tensão arquitetural: se cada loja tem sua fila, quem consome essas filas?
A primeira solução parece óbvia: criar consumidores permanentes para todas as filas de lojas. Um consumidor permanente seria um worker registrado o tempo todo naquela fila, aguardando novas mensagens.
Mas isso cria outro problema.
Se existem 50 mil lojas, não faz sentido manter 50 mil consumidores ativos, conexões abertas, prefetch configurado e recursos reservados para filas que, na maior parte do tempo, estão vazias. O sistema passa a gastar capacidade computacional esperando por trabalho que talvez nem exista.
O problema real não é apenas processar mensagens.
O problema é encontrar um modelo intermediário entre dois extremos ruins:
- consumidores permanentes demais
- ou uma fila centralizada demais.
A solução demanda que:
- O sistema precisa iniciar consumidores sob demanda para filas específicas,
- mas apenas quando houver algum indício de que existe trabalho pendente naquela fila.
- Também precisa decidir
- por quanto tempo cada consumidor temporário deve trabalhar,
- quantas mensagens ele deve tentar consumir,
- e como evitar que múltiplos workers processem a mesma fila de forma descontrolada.
Alternativas consideradas
Algumas soluções aparecem rapidamente.
A primeira é usar consumidores permanentes por fila. É simples de entender, mas escala mal quando há muitas filas granulares e baixo volume médio por fila.
A segunda é usar uma fila central única para todas as lojas. Isso reduz a quantidade de consumidores, mas perde isolamento. Uma loja ruidosa pode atrasar lojas menores, e políticas por loja ficam mais difíceis.
A terceira é criar agrupadores de filas centralizadas. Em vez de uma fila única para todas as lojas, o sistema poderia criar grupos menores, por exemplo process.marketplace.group_01.work, process.marketplace.group_02.work e assim por diante. Cada grupo receberia tarefas de algumas lojas. Essa abordagem parece um meio-termo: reduz a quantidade de filas e evita que todas as lojas disputem uma única fila global.
O problema é que o isolamento continua sendo parcial e acidental. Imagine que group_01 tenha 100 lojas. Se uma loja grande dentro desse grupo gera 1 milhão de jobs durante uma campanha, as outras 99 lojas ficam presas atrás dela ou passam a competir com ela dentro da mesma fila. O problema deixou de ser global, mas virou local: em vez de uma loja afetar a plataforma inteira, ela afeta todas as lojas do grupo.
Se a distribuição por grupo fica ruim, surge a necessidade de rebalancear lojas entre filas, o que adiciona operação, migração e risco. Além disso, políticas por loja continuam difíceis: limite de API, pausa de uma integração, prioridade comercial e reprocessamento isolado precisam ser reconstruídos dentro do consumidor, porque a fila já não representa uma única loja. O grupo melhora a fila única, mas não entrega isolamento real por loja.
A quarta é fazer polling periódico em todas as filas. Um scheduler varre as filas e processa as que têm mensagens. Funciona, mas introduz latência artificial, aumenta chamadas vazias ao broker e desperdiça ciclos quando há muitas filas inativas. Aqui, broker é o servidor de mensageria, como RabbitMQ, responsável por armazenar e entregar mensagens.
A quinta é fazer a API publicar mensagens diretamente em filas específicas e, junto com elas, publicar um pequeno sinal interno dizendo: esta fila precisa de atenção.
Essa é a solução que chamaremos de Attention Queue.
A ideia central é produzir dois tipos de mensagem dentro do sistema. Para o integrador externo, continua existindo uma única operação: uma chamada HTTP para a API, por exemplo para enviar uma atualização de estoque ou uma tarefa de sincronização. Depois que a API recebe e valida essa requisição, ela publica internamente duas mensagens. A primeira é a mensagem de trabalho: ela contém o dado real que precisa ser processado. A segunda é a mensagem de atenção: ela é menor e serve apenas para avisar ao próprio sistema que uma fila específica tem demanda pendente e precisa ser consumida.
| Tipo | Onde fica | O que contém | Para que serve |
|---|---|---|---|
| Mensagem de trabalho | Fila específica da loja | Payload real da tarefa, como atualização de estoque, pedido ou catálogo | Ser processada pela regra de negócio |
| Pedido de atenção | Fila compartilhada de atenção | Ponteiros mínimos, como tenant, loja, marketplace e prioridade | Acionar o consumo da fila de trabalho correta |
A mensagem real entra na fila específica do recurso. Essa fila é onde ficam os dados que efetivamente precisam ser processados. Por exemplo:
process.marketplace.store_873.work
Esse nome de fila é apenas uma convenção didática. A implementação pode escolher outro formato. O ponto essencial é que o pedido de atenção tenha dados suficientes para localizar, derivar ou consultar qual fila de trabalho precisa ser consumida.
O sinal entra em uma fila compartilhada de atenção. Essa fila não guarda o trabalho completo; ela guarda apenas avisos de que alguma fila específica precisa ser olhada. Por exemplo:
attention.marketplace.work
Esse sinal não contém o payload completo. Ele contém apenas o necessário para localizar a fila que precisa de atenção, ou seja, a fila que precisa ser consumida: tenant, tipo do recurso, id do recurso e algumas chaves de roteamento. Para um desenvolvedor .NET, esse sinal pode ser visto como um DTO pequeno, serializado em JSON e publicado internamente pelo próprio sistema.
Com isso, o sistema não precisa manter consumidores permanentes para todas as filas de trabalho. Ele mantém consumidores na fila de atenção. Quando uma mensagem de atenção chega, um worker usa esse aviso para localizar a fila específica, inicia um consumo temporário, consome por um tempo limitado ou até uma quantidade máxima de mensagens, e depois decide se o trabalho acabou ou se precisa republicar outra atenção.
Essa decisão de parar antes de consumir tudo é intencional. A inspiração vem do escalonamento de processos em sistemas operacionais, especialmente do conceito de time sharing. A CPU mantém processos prontos para executar e não deixa um único processo monopolizar o processador indefinidamente. Ela entrega uma fatia de tempo para um processo, interrompe, e depois dá oportunidade para outros processos avançarem. No Attention Queue, a fila de atenção faz um papel parecido com uma fila de processos prontos: cada mensagem de atenção representa uma fila de trabalho que quer uma fatia de processamento. Se ainda houver mensagens depois dessa fatia, a fila entra novamente na disputa por processamento por meio de uma nova mensagem de atenção.
O padrão não tenta ser apenas eficiente; ele tenta ser justo. Cada loja recebe fatias de processamento, evitando que uma loja grande capture a maior parte dos workers e transforme volume em privilégio operacional involuntário.
Como funciona
O padrão funciona como um despachante interno.
Ele não processa o trabalho diretamente. Ele aponta onde existe trabalho. Em uma aplicação .NET, pense nele como um BackgroundService ou worker que recebe um comando pequeno e, a partir dele, decide qual fila de trabalho deve ser consumida.
Em vez de perguntar o tempo todo se há mensagens em cada fila, o sistema recebe um sinal quando algo novo chega. Em vez de deixar um consumidor eterno parado em uma fila vazia, ele inicia um consumidor temporário apenas quando há motivo para isso.
Um fluxo típico seria:
- Um integrador faz uma chamada HTTP para a API do MarketHub solicitando uma sincronização ou enviando uma atualização.
- A API valida a requisição e publica internamente a tarefa na fila
process.marketplace.store_873.work. - Na mesma operação interna, a API publica um sinal em
attention.marketplace.work. - Um worker consome esse sinal de atenção.
- O worker consulta o estado da loja ou integração relacionada.
- Se a loja está desativada, em manutenção, bloqueada por erro de credencial ou removida, a atenção é descartada.
- Se a loja está válida, o worker calcula os limites de consumo: tempo máximo, quantidade máxima de mensagens e concorrência permitida.
- O worker tenta adquirir permissão de rate limit para evitar excesso de consumidores simultâneos na mesma fila. Nesse contexto, rate limit é apenas uma trava de capacidade: quantos consumidores podem trabalhar naquela fila ao mesmo tempo. Esse limite pode ser 1, quando a fila precisa ser consumida de forma serial, ou pode ser maior, como 5 ou 10, quando o domínio permite paralelismo seguro.
- Se permitido, ele inicia um consumidor temporário na fila específica da loja.
- Ele processa mensagens até atingir uma das condições de parada: tempo máximo, quantidade máxima, erro operacional ou fila vazia.
- Ao final, ele verifica se ainda há backlog. Se houver, republica uma nova atenção na fila de atenção. Se não houver, encerra.
- A nova atenção volta para a mesma fila compartilhada de atenção e será consumida no próximo ciclo por algum worker disponível. Pode ser o mesmo worker ou outro. O ponto é que a fila de uma loja grande não monopoliza o processamento indefinidamente.
Encontrar a fila vazia não é erro. Uma atenção pode chegar atrasada: quando o worker olha a fila de trabalho, ela já pode ter sido consumida por outro ciclo. Nesse caso, ele apenas confirma a atenção e encerra.
O ponto importante é que o sinal de atenção é barato, pequeno e repetível.
Ele não precisa representar exatamente uma mensagem de trabalho. Ele representa uma intenção: essa fila merece ser observada e provavelmente precisa ser consumida.
Por isso, o pedido de atenção deve ser idempotente. O sistema precisa aceitar a possibilidade de receber duas ou mais atenções para a mesma loja sem duplicar processamento indevido. No pior caso, uma atenção extra inicia uma tentativa que encontra a fila vazia, é bloqueada pelo limite de concorrência, ou percebe que o backlog já foi processado por outro ciclo.
Isso muda a forma de pensar. A fila de atenção não é a fila de trabalho. Ela é a fila de coordenação. Ela funciona como uma fila de escalonamento: decide qual fila de trabalho recebe a próxima fatia de processamento.
Exemplo completo
No MarketHub, cada loja possui uma fila própria:
process.marketplace.store_{storeId}.work
O conjunto de integrações com marketplaces possui uma fila de atenção:
attention.marketplace.work
Quando a loja store-873 precisa sincronizar pedidos ou atualizar estoque em um marketplace, o integrador faz uma única chamada HTTP para a API. Para quem integra, a operação termina aí: ele enviou a solicitação para o MarketHub. Quem sabe que também precisa gerar um pedido de atenção é a própria API.
Depois de receber a chamada HTTP, a API faz duas publicações internas no broker. Essa dupla publicação precisa ser tratada como uma unidade operacional: não basta publicar a mensagem de trabalho e torcer para que o pedido de atenção também seja publicado. Se a primeira publicação funcionar e a segunda falhar, a fila da loja pode ficar com trabalho pendente sem nenhum sinal para acionar o consumo.
Existem várias formas de proteger esse ponto, dependendo do nível de garantia exigido pela aplicação: usar confirmação de publicação do broker, aplicar outbox pattern, fazer retry idempotente da publicação de atenção ou manter uma reconciliação periódica que encontre filas com backlog sem atenção recente. O detalhe da técnica pode variar, mas a decisão arquitetural é a mesma: mensagem de trabalho e pedido de atenção fazem parte da mesma intenção operacional.
Nos exemplos abaixo, aparecem três termos comuns em RabbitMQ. O exchange é o ponto onde a aplicação publica a mensagem. A routingKey é a chave usada para decidir o caminho da mensagem. A queue é a fila onde a mensagem fica armazenada até algum consumidor processá-la.
A primeira publicação carrega o trabalho real:
exchange: process.marketplace routingKey: store.store-873 body: tarefa completa de sincronização
A segunda publicação carrega apenas o pedido de atenção:
{
"tenantId": "seller-group-a",
"storeId": "store-873",
"marketplace": "mercado-livre",
"priority": "normal"
}
O worker de atenção recebe esse segundo evento e monta a fila real:
process.marketplace.store_873.work
Antes de consumir, aplica uma política:
maxConsumptionTimeSeconds = 20 maxMessages = 100 maxConcurrentConsumers = 2
Nesse exemplo, maxConcurrentConsumers = 2 significa que no máximo dois consumidores podem processar a fila dessa loja ao mesmo tempo. Em outro cenário, esse valor poderia ser 1, garantindo um único consumidor ativo por fila de trabalho. Isso é útil quando a ordem dos eventos importa, quando há risco de conflito em atualizações de estoque, ou quando a API do marketplace exige chamadas mais controladas. Se a loja tiver um plano maior, integração estável e operações independentes, o limite poderia ser 10.
Então ele tenta adquirir um token de concorrência para essa loja. Se já existem consumidores suficientes processando essa fila, a atenção é republicada para uma tentativa futura.
Se houver permissão, o worker consome até 100 mensagens ou até 20 segundos. Ele não continua até o fim da fila porque isso permitiria que uma única loja ruidosa ocupasse o worker por tempo demais. Se ainda restarem mensagens, ele republica uma nova atenção. Essa nova atenção volta para attention.marketplace.work e será disputada pelos consumidores dessa fila de atenção. Se a fila estiver vazia, ele encerra.
Implementação
O padrão pode ser implementado com cinco componentes.
Ele não exige uma abstração genérica de mensageria. Os exemplos a seguir usam vocabulário comum em aplicações .NET e RabbitMQ, mas a parte mais importante é o contrato explícito do domínio: uma mensagem de trabalho, uma mensagem de atenção, um worker que entende esse contrato e uma política clara de consumo.
O primeiro é a fila de trabalho granular. Ela guarda mensagens reais por entidade, cliente, loja, conta ou qualquer unidade que precise de isolamento. É nela que está o payload que a regra de negócio vai processar.
O segundo é a fila de atenção agregada. Ela recebe sinais pequenos agrupados por tipo. Essa fila é consumida por poucos workers permanentes.
O terceiro é o envelope de atenção. Ele contém os identificadores mínimos para localizar a fila de trabalho que precisa de atenção. Esse envelope deve ser seguro para repetição: publicar ou consumir o mesmo pedido mais de uma vez não pode corromper o estado do sistema. Em C#, ele seria uma classe simples, por exemplo:
public sealed class AttentionRequest
{
public required string TenantId { get; init; }
public required string StoreId { get; init; }
public required string Marketplace { get; init; }
}
O quarto é o worker de atenção. Ele valida o estado da entidade, inicia um consumidor temporário, processa em lote controlado e decide se precisa de nova atenção. Esse worker não precisa esconder RabbitMQ atrás de uma abstração genérica; ele pode chamar APIs explícitas do broker ou serviços internos próprios.
O quinto é o controle de concorrência. Ele normalmente é apoiado por Redis, banco de dados ou lock distribuído, para impedir que múltiplos workers processem a mesma fila além do limite permitido. Esse limite não precisa ser maior que 1. Em muitos casos, o valor correto é exatamente 1 consumidor ativo por fila de trabalho. Em outros, o limite pode ser 10 ou mais, desde que o processamento seja independente, idempotente e seguro para paralelismo.
Em uma base .NET, esses componentes poderiam aparecer como contratos próprios do sistema:
public interface IAttentionPublisher
{
Task PublishAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public interface IAttentionWorker
{
Task<AttentionResult> ProcessAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public enum AttentionResult
{
Done,
NeedMoreAttention
}
Essas interfaces não precisam prometer que servem para qualquer broker ou qualquer caso de mensageria. Elas existem para representar uma decisão arquitetural específica: publicar pedidos de atenção e consumir filas de trabalho sob demanda.
Um pseudocódigo possível:
No pseudocódigo, ack attention significa confirmar ao broker que aquela mensagem de atenção foi tratada e pode sair da fila. Se o worker falhar antes do ack, o broker pode tentar entregar a mesma atenção de novo, dependendo da configuração. Esse é mais um motivo para o pedido de atenção ser idempotente. O oposto do ack costuma ser chamado de nack, usado quando a mensagem não foi processada com sucesso e deve seguir a política de erro ou retentativa.
on attention_received(attention):
resource = load_resource(attention.resource_id)
if resource cannot receive processing:
ack attention
return
queue_name = build_work_queue_name(resource)
if rate_limit_blocked(queue_name):
republish attention
ack attention
return
if queue_does_not_exist(queue_name):
ack attention
return
if queue_is_empty(queue_name):
ack attention
return
consume_until(
queue = queue_name,
max_messages = resource.max_messages,
max_time = resource.max_time
)
if queue_has_remaining_messages(queue_name):
republish attention
ack attention
O republish attention não é uma recursão nem uma chamada imediata ao mesmo worker. Ele coloca um novo pedido no fim da fila de atenção. Depois disso, o worker atual finaliza o ciclo e fica livre para pegar o próximo pedido disponível. O broker entrega a nova atenção quando ela chegar à vez dela, respeitando a concorrência e a ordem operacional da fila.
Em RabbitMQ, uma implementação concreta pode usar uma topologia semelhante. O binding é a regra que liga um exchange a uma queue.
exchange: attention.marketplace queue: attention.marketplace.work binding: store.* exchange: process.marketplace queue: process.marketplace.store_873.work binding: store.store-873
A API publica o payload completo na fila de trabalho e publica um envelope pequeno na fila de atenção:
HTTP request from integrator API validates request API publishes process event API publishes attention event
Na implementação real, esses dois últimos passos devem ter uma estratégia explícita de consistência. Se não houver uma transação única envolvendo tudo, a aplicação precisa de confirmação, retry, outbox ou reconciliação para não deixar trabalho sem atenção.
O worker de atenção, por sua vez, não precisa conhecer todas as lojas antecipadamente. Ele só precisa saber transformar o envelope de atenção em nome de fila, política de consumo e chave de controle de concorrência.
Observabilidade
Attention Queue só é confortável de operar quando o sistema mostra claramente onde há trabalho parado, onde há excesso de atenção e onde há bloqueio por política.
Algumas métricas úteis:
| Métrica | O que revela |
|---|---|
| Quantidade de mensagens por fila de loja | Quais lojas estão acumulando backlog |
| Idade da mensagem mais antiga por fila | Há quanto tempo a loja mais atrasada espera processamento |
| Número de atenções republicadas | Quais filas precisam de muitos ciclos para esvaziar |
| Atenções descartadas por loja desativada ou inválida | Quanto trabalho está sendo ignorado por estado operacional |
| Bloqueios por rate limit | Quais lojas estão batendo no limite de concorrência ou SLA |
| Tempo médio para zerar backlog | Quanto tempo o sistema leva para recuperar uma fila com trabalho pendente |
Essas métricas ajudam a separar problemas diferentes. Uma loja pode estar lenta porque tem backlog real, porque está limitada por plano, porque a integração está bloqueada, porque há muitas atenções repetidas, ou porque os workers disponíveis não são suficientes. Sem essas medidas, o padrão continua funcionando, mas fica difícil explicar seu comportamento em produção.
Quando não usar
Attention Queue não deve ser tratado como solução padrão para qualquer processamento assíncrono.
Se o sistema tem poucas filas, volume previsível e consumidores permanentes baratos de manter, o padrão pode adicionar complexidade desnecessária. Se uma fila única já atende bem, com latência aceitável e sem problemas de isolamento, talvez não exista dor suficiente para justificar filas granulares e pedidos de atenção.
Também não é uma boa escolha quando o processamento precisa obedecer uma ordem estritamente global entre todas as mensagens. O padrão favorece isolamento e justiça entre filas, não uma ordenação única do sistema inteiro.
Outro ponto é custo operacional. Filas dinâmicas exigem convenção de nomes, criação, remoção, monitoramento e capacidade de diagnóstico. Se o broker ou o time ainda não consegue operar muitas filas com segurança, é melhor amadurecer essa base antes de adotar o padrão.
Benefícios
O benefício principal do padrão é alinhar consumo com necessidade real.
Ele permite manter milhares ou milhões de filas lógicas sem exigir milhares ou milhões de consumidores ativos. O sistema fica mais elástico porque consumidores aparecem quando há backlog e desaparecem quando o trabalho acaba.
Também melhora o isolamento. Uma entidade ruidosa não precisa contaminar o fluxo das demais, porque cada entidade pode ter sua fila, seus limites e sua política de consumo.
Outro benefício é justiça operacional, ou fairness, entre lojas. O padrão distribui o processamento em fatias e evita que uma loja grande capture a maior parte dos workers apenas por ter mais volume. Ela pode receber mais atenção se a política permitir, mas isso passa a ser uma decisão explícita do sistema, não um efeito colateral do backlog.
Outro benefício é a governança operacional. Como o worker de atenção passa por uma etapa de enriquecimento antes de consumir, ele pode verificar estado, permissões, locks, manutenção, prioridade e limites antes de gastar esforço processando mensagens.
O padrão também abre espaço para acordos comerciais diferentes. Como a atenção passa por uma política interna antes de virar consumo real, o sistema pode dar tratamento diferente para lojas em planos diferentes: mais consumidores simultâneos, janelas de consumo maiores, mais mensagens por ciclo, prioridade maior na republicação da atenção ou regras específicas para campanhas e datas sazonais.
Um exemplo simples:
| Plano | Consumidores simultâneos por loja | Mensagens por ciclo |
|---|---|---|
| Basic | 1 | 50 |
| Pro | 3 | 200 |
| Enterprise | 10 | 1000 |
Isso permite transformar capacidade de processamento em SLA comercial sem expor a complexidade de filas para o integrador.
Há também um ganho de resiliência: se o processamento não terminar em um ciclo, a própria atenção pode ser republicada. O trabalho progride em fatias, como no time sharing da CPU. O sistema não precisa resolver todo o backlog de uma vez, e uma fila muito cheia não prende o worker indefinidamente.
Em resumo, o padrão Attention Queue é útil quando há muitas filas específicas, volume irregular, necessidade de isolamento e custo alto para manter consumidores permanentes.
Ele transforma processamento contínuo em processamento sob demanda.
A fila de atenção não carrega o peso do trabalho. Ela carrega a consciência de que existe trabalho.
Circular Buffer, Ring Buffer, ObjectPool e Objects Pools Elásticos
Segunda-feira, 14h. Pico de tráfego. Sua aplicação .NET começa a derreter conexões com o RabbitMQ. Você abre o Grafana, vê 800 conexões abertas contra um broker que aguenta confortavelmente 50, e a hipótese imediata é “vamos limitar o pool”. Alguém sobe um SemaphoreSlim, faz deploy, e na quarta-feira o problema inverte: as conexões caem para duas, ficam ociosas, e quando o próximo burst chega, a latência explode porque cada nova publicação está pagando 200ms de handshake TLS + AMQP.
Esse vai-e-volta é o sintoma.
A causa é mais profunda: recursos caros e voláteis estão sendo tratados como recursos baratos e estáveis.
E quase nenhuma abstração padrão do .NET lida bem com isso.
… até hoje!
ler mais…
Event-driven Architecture: você está reaproveitando eventos ou mentindo para o seu próprio sistema?
Quantos eventos no seu sistema são emitidos em situações onde o fato que eles representam simplesmente não aconteceu?
Um PedidoCriado disparado por uma rotina de correção. Um PagamentoConfirmado emitido por um job de reprocessamento. Um UsuarioCadastrado lançado por uma migração de base legada. O fato não aconteceu, mas o evento foi emitido assim mesmo — porque “já tem tudo plugado”.
Essa é a confusão mais destrutiva em event-driven architecture. Não é sobre nomenclatura. É sobre semântica. E quando a semântica quebra, o sistema inteiro passa a operar sobre premissas falsas.
ler mais…
OA03 – Fazemos o que precisa ser feito e arcamos com as consequências das decisões que tomamos
Seu time quer publicar pacotes NuGet mas não quer manter um NuGet Server. Quer rodar containers mas não quer contratar um Container Registry. Quer processar mensagens assíncronas mas acha que uma tabela com coluna status no PostgreSQL resolve.
A pergunta que ninguém faz é: por que você está adotando uma solução cujo custo operacional mínimo você se recusa a pagar?
ler mais…Containers

Simulando I/O limitado com Docker: como testar aplicações sob restrições realistas
Testar aplicações é um desafio recorrente e complexo na engenharia de software. Porém, quando o cenário envolve restrições específicas de I/O — como latência de disco, throughput de leitura/escrita reduzido ou limitação de operações por segundo — o desafio ganha outra dimensão.
Nesse contexto, a capacidade de simular gargalos de I/O torna-se uma ferramenta poderosa para validar a resiliência, eficiência e tolerância a falhas da sua aplicação. Felizmente, o Docker oferece mecanismos para isso, permitindo configurar limites finos de I/O em containers.
Não é todo dia que você é exposto a esse tipo de necessidade, como fui recentemente. Entretanto, a capacidade de ter à mão, algo tão simples quanto poderoso, permite validar e experimentar problemas previsíveis, muito antes de sequer contratar uma infra em produção.
É mais do que validar um setup, é sobre entregar previsibilidade arquietural.
Vamos explorar como isso pode ser feito, por que é útil e quais problemas essa abordagem ajuda a evitar.
ler mais…
Voltando do .NET Aspire para o Docker Compose
Já faz algum tempo que publiquei um post contando sobre minha experiência com o .NET Aspire. Depois de mais de 14 semanas com .NET Aspire chegou a hora de dizer “até logo”.
Neste texto, vamos discutir a viabilidade de usar o .NET Aspire em projetos baseados em Docker Compose e também mostrar o processo de migração do .NET Aspire de volta para o Docker Compose.
ler mais…
.NET ASPIRE Dashboard Standalone como Container
Nessa sexta-feira dia 16 foi lançado o Dashboard do ASPIRE como uma implementação OTLP standalone, em uma imagem docker, pronta para uso.
Entenda as novidades nesse post.
ler mais…
Microsoft Artifact Registry (MAR) – Descobrindo imagens e tags
Ao longo da jornada de containers do novo .NET desde sua primeira versão (.NET Core), temos o docker hub e posteriormente o MCR servindo imagens docker para nossas aplicações e servidores.
Sempre foi chato buscar as tags disponíveis, nos fazendo voltar às documentações e papers que descrevem migração.
Hoje você descobrirá que o Microsoft Container Registry mudou de nome e como descobrir as tags das principais imagens docker.
ler mais…
OCR Minimal API | .NET 8
Já pensou subir um serviço, com um simples docker run e ter um OCR ilimitado disponível para seu sistema? Você pode usar, comercializar, e fazer absolutamente qualquer coisa com o OCR.
Você pode usar para leitura de documentos, validação de prints, e muito mais.
Pois bem, hoje falarei sobre um projeto que criei e pode te economizar tempo e dinheiro no seu próximo projeto.
ler mais…Mensageria
Attention Queue: on-demand processing for granular queues
Consume thousands of specific queues without keeping thousands of active consumers.
The Problem
Imagine an e-commerce platform called MarketHub.
It integrates thousands of stores with marketplaces such as Amazon, eBay, Walmart Marketplace, and other sales channels. Each store needs to synchronize orders, inventory, prices, catalog data, shipping updates, and post-sale events. Most of the time, a small store generates little work. But when a large store performs a massive catalog update or receives a burst of orders during a campaign, it can generate thousands of tasks within minutes.
In MarketHub, each store has its own work queue. In simple terms, a queue is a persistent list of messages waiting to be processed. A producer puts messages into the queue; a consumer reads those messages and performs some action. In this scenario, the producer is MarketHub’s own API, not the external integrator.
This decision is not about aesthetic preference for granularity. It exists because different stores have different behaviors, priorities, and risks. A small store should not sit behind thousands of catalog updates from a very large store. A store with an unstable integration should not congest processing for the others. Also, a dedicated queue allows store-specific policies: consumption limits, operational pauses, maintenance, controlled discard, isolated reprocessing, respect for marketplace API limits, and direct observability into that store’s backlog.
In other words, a queue per store buys isolation, predictability, and operational control.
But it also creates a new architectural tension: if every store has its own queue, who consumes those queues?
The first solution seems obvious: create permanent consumers for every store queue. A permanent consumer would be a worker registered on that queue all the time, waiting for new messages.
But that creates another problem.
If there are 50,000 stores, it does not make sense to keep 50,000 active consumers, open connections, configured prefetch, and reserved resources for queues that are empty most of the time. The system starts spending compute capacity waiting for work that may not exist.
The real problem is not just processing messages.
The problem is finding an intermediate model between two bad extremes: too many permanent consumers or an overly centralized queue. The system needs to start consumers on demand for specific queues, but only when there is some indication that work is pending in that queue. It also needs to decide how long each temporary consumer should work, how many messages it should try to consume, and how to prevent multiple workers from processing the same queue in an uncontrolled way.
Considered Alternatives
Several solutions appear quickly.
The first is to use permanent consumers per queue. It is simple to understand, but it scales poorly when there are many granular queues and low average volume per queue.
The second is to use a single central queue for all stores. This reduces the number of consumers, but loses isolation. A noisy store can delay smaller stores, and store-specific policies become harder.
The third is to create grouped centralized queues. Instead of one queue for all stores, the system could create smaller groups, for example process.marketplace.group_01.work, process.marketplace.group_02.work, and so on. Each group would receive tasks from some stores. This approach looks like a middle ground: it reduces the number of queues and avoids making all stores compete in one global queue.
The problem is that isolation remains partial and accidental. Imagine group_01 has 100 stores. If one large store inside that group generates 1 million jobs during a campaign, the other 99 stores are stuck behind it or forced to compete with it inside the same queue. The problem is no longer global, but it became local: instead of one store affecting the whole platform, it affects every store in the group.
If group distribution becomes poor, teams need to rebalance stores across queues, which adds operations, migration, and risk. Also, store-specific policies remain difficult: API limits, pausing one integration, commercial priority, and isolated reprocessing need to be rebuilt inside the consumer, because the queue no longer represents a single store. Grouping improves the single-queue approach, but does not provide real isolation per store.
The fourth is to periodically poll all queues. A scheduler scans queues and processes the ones that have messages. It works, but it introduces artificial latency, increases empty calls to the broker, and wastes cycles when many queues are inactive. Here, broker means the messaging server, such as RabbitMQ, responsible for storing and delivering messages.
The fifth is to make the API publish messages directly to specific queues and, along with them, publish a small internal signal saying: this queue needs attention.
That is the solution we will call Attention Queue.
The core idea is to produce two types of messages inside the system. For the external integrator, there is still a single operation: an HTTP call to the API, for example to send an inventory update or synchronization task. After the API receives and validates that request, it internally publishes two messages. The first is the work message: it contains the real data that needs to be processed. The second is the attention message: it is smaller and only serves to tell the system itself that a specific queue has pending demand and needs to be consumed.
| Type | Where it lives | What it contains | What it is for |
|---|---|---|---|
| Work message | Store-specific queue | Real task payload, such as inventory update, order, or catalog data | To be processed by business logic |
| Attention request | Shared attention queue | Minimal pointers, such as tenant, store, marketplace, and priority | To trigger consumption of the correct work queue |
The real message enters the resource-specific queue. That queue is where the data that actually needs to be processed waits. For example:
process.marketplace.store_873.work
This queue name is only a didactic convention. An implementation can choose another format. The essential point is that the attention request has enough data to locate, derive, or query which work queue needs to be consumed.
The signal enters a shared attention queue. This queue does not store the complete work; it only stores notices that some specific queue needs to be inspected. For example:
attention.marketplace.work
That signal does not contain the full payload. It contains only what is needed to locate the queue that needs attention, meaning the queue that needs to be consumed: tenant, resource type, resource id, and some routing keys. For a .NET developer, this signal can be seen as a small DTO, serialized as JSON and published internally by the system itself.
With this, the system does not need to keep permanent consumers for every work queue. It keeps consumers on the attention queue. When an attention message arrives, a worker uses that notice to locate the specific queue, starts a temporary consumption cycle, consumes for a limited time or up to a maximum number of messages, and then decides whether the work is done or whether it needs to republish another attention request.
This decision to stop before consuming everything is intentional. The inspiration comes from process scheduling in operating systems, especially the concept of time sharing. The CPU keeps processes ready to run and does not allow a single process to monopolize the processor indefinitely. It gives one process a time slice, interrupts it, and then gives other processes a chance to advance. In Attention Queue, the attention queue plays a similar role to a ready queue: each attention message represents a work queue asking for a processing slice. If there are still messages after that slice, the queue enters the processing competition again through a new attention message.
The pattern is not only trying to be efficient; it is trying to be fair. Each store receives processing slices, preventing a large store from capturing most workers and turning volume into unintended operational privilege.
How It Works
The pattern works like an internal dispatcher.
It does not process the work directly. It points to where work exists. In a .NET application, think of it as a BackgroundService or worker that receives a small command and, from that command, decides which work queue should be consumed.
Instead of constantly asking whether each queue has messages, the system receives a signal when something new arrives. Instead of leaving an eternal consumer sitting on an empty queue, it starts a temporary consumer only when there is a reason to do so.
A typical flow would be:
- An integrator makes an HTTP call to the MarketHub API requesting a synchronization or sending an update.
- The API validates the request and internally publishes the task to
process.marketplace.store_873.work. - In the same internal operation, the API publishes a signal to
attention.marketplace.work. - A worker consumes that attention signal.
- The worker checks the state of the related store or integration.
- If the store is disabled, under maintenance, blocked due to credential errors, or removed, the attention is discarded.
- If the store is valid, the worker calculates the consumption limits: maximum time, maximum number of messages, and allowed concurrency.
- The worker tries to acquire rate-limit permission to avoid too many simultaneous consumers on the same queue. In this context, rate limit is just a capacity gate: how many consumers can work on that queue at the same time. This limit can be 1 when the queue must be consumed serially, or it can be higher, such as 5 or 10, when the domain allows safe parallelism.
- If allowed, it starts a temporary consumer on the store-specific queue.
- It processes messages until one of the stop conditions is reached: maximum time, maximum message count, operational error, or empty queue.
- At the end, it checks whether there is still backlog. If there is, it republishes a new attention request to the attention queue. If not, it stops.
- The new attention returns to the same shared attention queue and will be consumed in the next cycle by some available worker. It may be the same worker or another one. The point is that one large store’s queue does not monopolize processing indefinitely.
Finding the work queue empty is not an error. An attention request can arrive late: when the worker checks the work queue, it may already have been consumed by another cycle. In that case, the worker simply acknowledges the attention and stops.
The important point is that the attention signal is cheap, small, and repeatable.
It does not need to represent exactly one work message. It represents an intention: this queue deserves to be observed and probably needs to be consumed.
For that reason, the attention request must be idempotent. The system must tolerate receiving two or more attention requests for the same store without causing improper duplicate processing. In the worst case, an extra attention starts an attempt that finds the queue empty, is blocked by the concurrency limit, or notices that the backlog was already processed by another cycle.
This changes how we think about the design. The attention queue is not the work queue. It is the coordination queue. It works like a scheduling queue: it decides which work queue receives the next processing slice.
Complete Example
In MarketHub, each store has its own queue:
process.marketplace.store_{storeId}.work
The marketplace integration set has an attention queue:
attention.marketplace.work
When store store-873 needs to synchronize orders or update inventory in a marketplace, the integrator makes a single HTTP call to the API. For the integrator, the operation ends there: it sent the request to MarketHub. The API itself knows that it also needs to generate an attention request.
After receiving the HTTP call, the API performs two internal publications to the broker. This double publication must be treated as one operational unit: it is not enough to publish the work message and hope the attention request is also published. If the first publication succeeds and the second one fails, the store queue may contain pending work with no signal to trigger consumption.
There are several ways to protect this point, depending on the level of guarantee required by the application: use broker publish confirmations, apply the outbox pattern, perform idempotent retry of the attention publication, or keep a periodic reconciliation process that finds queues with backlog and no recent attention. The specific technique may vary, but the architectural decision is the same: the work message and the attention request are part of the same operational intent.
The examples below use three common RabbitMQ terms. The exchange is the point where the application publishes the message. The routingKey is the key used to decide the message path. The queue is where the message stays stored until some consumer processes it.
The first publication carries the real work:
exchange: process.marketplace routingKey: store.store-873 body: complete synchronization task
The second publication carries only the attention request:
{
"tenantId": "seller-group-a",
"storeId": "store-873",
"marketplace": "amazon",
"priority": "normal"
}
The attention worker receives this second event and builds the real queue:
process.marketplace.store_873.work
Before consuming, it applies a policy:
maxConsumptionTimeSeconds = 20 maxMessages = 100 maxConcurrentConsumers = 2
In this example, maxConcurrentConsumers = 2 means at most two consumers can process that store queue at the same time. In another scenario, this value could be 1, guaranteeing a single active consumer per work queue. That is useful when event order matters, when there is risk of conflict in inventory updates, or when the marketplace API requires more controlled calls. If the store has a higher plan, stable integration, and independent operations, the limit could be 10.
Then it tries to acquire a concurrency token for that store. If enough consumers are already processing that queue, the attention is republished for a future attempt.
If allowed, the worker consumes up to 100 messages or up to 20 seconds. It does not continue until the queue is empty because that would allow one noisy store to occupy the worker for too long. If messages remain, it republishes a new attention request. That new attention returns to attention.marketplace.work and will be competed for by the consumers of that attention queue. If the queue is empty, the worker stops.
Implementation
The pattern can be implemented with five components.
It does not require a generic messaging abstraction. The examples below use common .NET and RabbitMQ vocabulary, but the most important part is the explicit domain contract: a work message, an attention message, a worker that understands that contract, and a clear consumption policy.
The first is the granular work queue. It stores real messages per entity, customer, store, account, or any unit that needs isolation. This is where the payload that business logic will process lives.
The second is the aggregated attention queue. It receives small signals grouped by type. This queue is consumed by a small number of permanent workers.
The third is the attention envelope. It contains the minimum identifiers needed to locate the work queue that needs attention. This envelope must be safe to repeat: publishing or consuming the same request more than once must not corrupt system state. In C#, it could be a simple class, for example:
public sealed class AttentionRequest
{
public required string TenantId { get; init; }
public required string StoreId { get; init; }
public required string Marketplace { get; init; }
}
The fourth is the attention worker. It validates entity state, starts a temporary consumer, processes a controlled batch, and decides whether more attention is needed. This worker does not need to hide RabbitMQ behind a generic abstraction; it can call explicit broker APIs or internal services.
The fifth is concurrency control. It is usually backed by Redis, a database, or a distributed lock, to prevent multiple workers from processing the same queue beyond the allowed limit. This limit does not need to be greater than 1. In many cases, the correct value is exactly 1 active consumer per work queue. In others, the limit can be 10 or more, as long as processing is independent, idempotent, and safe for parallelism.
In a .NET codebase, these components could appear as domain-specific contracts:
public interface IAttentionPublisher
{
Task PublishAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public interface IAttentionWorker
{
Task<AttentionResult> ProcessAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public enum AttentionResult
{
Done,
NeedMoreAttention
}
These interfaces do not need to promise that they work for any broker or every messaging use case. They exist to represent a specific architectural decision: publish attention requests and consume work queues on demand.
One possible pseudocode:
In the pseudocode, ack attention means confirming to the broker that the attention message was handled and can leave the queue. If the worker fails before the ack, the broker may try to deliver the same attention again, depending on configuration. This is another reason why the attention request must be idempotent. The opposite of ack is usually called nack, used when the message was not successfully processed and should follow the error or retry policy.
on attention_received(attention):
resource = load_resource(attention.resource_id)
if resource cannot receive processing:
ack attention
return
queue_name = build_work_queue_name(resource)
if rate_limit_blocked(queue_name):
republish attention
ack attention
return
if queue_does_not_exist(queue_name):
ack attention
return
if queue_is_empty(queue_name):
ack attention
return
consume_until(
queue = queue_name,
max_messages = resource.max_messages,
max_time = resource.max_time
)
if queue_has_remaining_messages(queue_name):
republish attention
ack attention
The republish attention step is not recursion and not an immediate call to the same worker. It places a new request at the end of the attention queue. After that, the current worker finishes the cycle and becomes free to pick up the next available request. The broker delivers the new attention when its turn comes, respecting concurrency and the operational order of the queue.
In RabbitMQ, a concrete implementation can use a topology like this. The binding is the rule that connects an exchange to a queue.
exchange: attention.marketplace queue: attention.marketplace.work binding: store.* exchange: process.marketplace queue: process.marketplace.store_873.work binding: store.store-873
The API publishes the full payload to the work queue and publishes a small envelope to the attention queue:
HTTP request from integrator API validates request API publishes process event API publishes attention event
In a real implementation, these last two steps must have an explicit consistency strategy. If there is no single transaction covering everything, the application needs confirmations, retry, outbox, or reconciliation to avoid leaving work without attention.
The attention worker, in turn, does not need to know every store ahead of time. It only needs to know how to transform the attention envelope into a queue name, consumption policy, and concurrency-control key.
Observability
Attention Queue is comfortable to operate only when the system clearly shows where work is stuck, where there is too much attention, and where policy is blocking consumption.
Useful metrics include:
| Metric | What it reveals |
|---|---|
| Message count per store queue | Which stores are accumulating backlog |
| Age of the oldest message per queue | How long the most delayed store has been waiting for processing |
| Number of republished attentions | Which queues need many cycles to empty |
| Attentions discarded because the store is disabled or invalid | How much work is being ignored due to operational state |
| Rate-limit blocks | Which stores are hitting concurrency or SLA limits |
| Average time to clear backlog | How long the system takes to recover a queue with pending work |
These metrics help separate different problems. A store may be slow because it has real backlog, because it is limited by plan, because the integration is blocked, because there are too many repeated attentions, or because available workers are not enough. Without these measurements, the pattern still works, but explaining its behavior in production becomes difficult.
When Not To Use It
Attention Queue should not be treated as the default solution for every asynchronous processing problem.
If the system has few queues, predictable volume, and permanent consumers that are cheap to maintain, the pattern may add unnecessary complexity. If a single queue already works well, with acceptable latency and no isolation problems, there may not be enough pain to justify granular queues and attention requests.
It is also not a good choice when processing must obey a strictly global order across all messages. The pattern favors isolation and fairness across queues, not one single ordering for the whole system.
Another point is operational cost. Dynamic queues require naming conventions, creation, removal, monitoring, and diagnostic capability. If the broker or the team cannot yet operate many queues safely, it is better to mature that foundation before adopting the pattern.
Benefits
The main benefit of the pattern is aligning consumption with real demand.
It allows the system to maintain thousands or millions of logical queues without requiring thousands or millions of active consumers. The system becomes more elastic because consumers appear when there is backlog and disappear when work is done.
It also improves isolation. A noisy entity does not need to contaminate the flow of others, because each entity can have its own queue, limits, and consumption policy.
Another benefit is operational fairness between stores. The pattern distributes processing in slices and prevents a large store from capturing most workers simply because it has more volume. It can receive more attention if policy allows it, but that becomes an explicit system decision, not a side effect of backlog.
Another benefit is operational governance. Because the attention worker goes through an enrichment step before consuming, it can check state, permissions, locks, maintenance, priority, and limits before spending effort processing messages.
The pattern also opens space for different commercial agreements. Because attention goes through an internal policy before becoming real consumption, the system can treat stores in different plans differently: more simultaneous consumers, larger consumption windows, more messages per cycle, higher priority when republishing attention, or specific rules for campaigns and seasonal dates.
A simple example:
| Plan | Simultaneous consumers per store | Messages per cycle |
|---|---|---|
| Basic | 1 | 50 |
| Pro | 3 | 200 |
| Enterprise | 10 | 1000 |
This allows processing capacity to become a commercial SLA without exposing queue complexity to the integrator.
There is also a resilience gain: if processing does not finish in one cycle, attention itself can be republished. Work progresses in slices, as in CPU time sharing. The system does not need to clear the entire backlog at once, and a very full queue does not hold a worker indefinitely.
In summary, the Attention Queue pattern is useful when there are many specific queues, irregular volume, a need for isolation, and a high cost to keep permanent consumers.
It transforms continuous processing into on-demand processing.
The attention queue does not carry the weight of the work. It carries the awareness that work exists.
Attention Queue: processamento sob demanda para filas granulares
Um padrão para consumir milhares de filas específicas sem manter milhares de consumidores ativos.
O problema
Imagine uma plataforma de e-commerce chamada MarketHub.
Ela integra milhares de lojas com marketplaces como Amazon, Mercado Livre, Shopee e outros canais de venda. Cada loja precisa sincronizar pedidos, estoque, preço, catálogo, notas de envio e eventos de pós-venda. Na maior parte do tempo, uma loja pequena gera pouco trabalho. Mas, quando uma loja grande faz uma atualização massiva de catálogo ou recebe uma rajada de pedidos em uma campanha, ela pode gerar milhares de tarefas em poucos minutos.
No MarketHub, cada loja tem sua própria fila de trabalho. Em termos simples, uma fila é uma lista persistente de mensagens esperando processamento. Um produtor coloca mensagens na fila; um consumidor lê essas mensagens e executa alguma ação. No nosso cenário, o produtor é a própria API do MarketHub, não o integrador externo.
Essa decisão não nasce de preferência estética pela granularidade. Ela existe porque lojas diferentes têm comportamentos, prioridades e riscos diferentes. Uma loja pequena não pode ficar atrás de milhares de atualizações de catálogo de uma loja muito grande. Uma loja com integração instável também não pode congestionar o processamento das demais. Além disso, a fila própria permite aplicar políticas específicas por loja: limite de consumo, pausa operacional, manutenção, descarte controlado, reprocessamento isolado, respeito a limites de API do marketplace e observabilidade direta do backlog daquela loja.
Em outras palavras, a fila por loja compra isolamento, previsibilidade e controle operacional.
Mas ela também cria uma nova tensão arquitetural: se cada loja tem sua fila, quem consome essas filas?
A primeira solução parece óbvia: criar consumidores permanentes para todas as filas de lojas. Um consumidor permanente seria um worker registrado o tempo todo naquela fila, aguardando novas mensagens.
Mas isso cria outro problema.
Se existem 50 mil lojas, não faz sentido manter 50 mil consumidores ativos, conexões abertas, prefetch configurado e recursos reservados para filas que, na maior parte do tempo, estão vazias. O sistema passa a gastar capacidade computacional esperando por trabalho que talvez nem exista.
O problema real não é apenas processar mensagens.
O problema é encontrar um modelo intermediário entre dois extremos ruins:
- consumidores permanentes demais
- ou uma fila centralizada demais.
A solução demanda que:
- O sistema precisa iniciar consumidores sob demanda para filas específicas,
- mas apenas quando houver algum indício de que existe trabalho pendente naquela fila.
- Também precisa decidir
- por quanto tempo cada consumidor temporário deve trabalhar,
- quantas mensagens ele deve tentar consumir,
- e como evitar que múltiplos workers processem a mesma fila de forma descontrolada.
Alternativas consideradas
Algumas soluções aparecem rapidamente.
A primeira é usar consumidores permanentes por fila. É simples de entender, mas escala mal quando há muitas filas granulares e baixo volume médio por fila.
A segunda é usar uma fila central única para todas as lojas. Isso reduz a quantidade de consumidores, mas perde isolamento. Uma loja ruidosa pode atrasar lojas menores, e políticas por loja ficam mais difíceis.
A terceira é criar agrupadores de filas centralizadas. Em vez de uma fila única para todas as lojas, o sistema poderia criar grupos menores, por exemplo process.marketplace.group_01.work, process.marketplace.group_02.work e assim por diante. Cada grupo receberia tarefas de algumas lojas. Essa abordagem parece um meio-termo: reduz a quantidade de filas e evita que todas as lojas disputem uma única fila global.
O problema é que o isolamento continua sendo parcial e acidental. Imagine que group_01 tenha 100 lojas. Se uma loja grande dentro desse grupo gera 1 milhão de jobs durante uma campanha, as outras 99 lojas ficam presas atrás dela ou passam a competir com ela dentro da mesma fila. O problema deixou de ser global, mas virou local: em vez de uma loja afetar a plataforma inteira, ela afeta todas as lojas do grupo.
Se a distribuição por grupo fica ruim, surge a necessidade de rebalancear lojas entre filas, o que adiciona operação, migração e risco. Além disso, políticas por loja continuam difíceis: limite de API, pausa de uma integração, prioridade comercial e reprocessamento isolado precisam ser reconstruídos dentro do consumidor, porque a fila já não representa uma única loja. O grupo melhora a fila única, mas não entrega isolamento real por loja.
A quarta é fazer polling periódico em todas as filas. Um scheduler varre as filas e processa as que têm mensagens. Funciona, mas introduz latência artificial, aumenta chamadas vazias ao broker e desperdiça ciclos quando há muitas filas inativas. Aqui, broker é o servidor de mensageria, como RabbitMQ, responsável por armazenar e entregar mensagens.
A quinta é fazer a API publicar mensagens diretamente em filas específicas e, junto com elas, publicar um pequeno sinal interno dizendo: esta fila precisa de atenção.
Essa é a solução que chamaremos de Attention Queue.
A ideia central é produzir dois tipos de mensagem dentro do sistema. Para o integrador externo, continua existindo uma única operação: uma chamada HTTP para a API, por exemplo para enviar uma atualização de estoque ou uma tarefa de sincronização. Depois que a API recebe e valida essa requisição, ela publica internamente duas mensagens. A primeira é a mensagem de trabalho: ela contém o dado real que precisa ser processado. A segunda é a mensagem de atenção: ela é menor e serve apenas para avisar ao próprio sistema que uma fila específica tem demanda pendente e precisa ser consumida.
| Tipo | Onde fica | O que contém | Para que serve |
|---|---|---|---|
| Mensagem de trabalho | Fila específica da loja | Payload real da tarefa, como atualização de estoque, pedido ou catálogo | Ser processada pela regra de negócio |
| Pedido de atenção | Fila compartilhada de atenção | Ponteiros mínimos, como tenant, loja, marketplace e prioridade | Acionar o consumo da fila de trabalho correta |
A mensagem real entra na fila específica do recurso. Essa fila é onde ficam os dados que efetivamente precisam ser processados. Por exemplo:
process.marketplace.store_873.work
Esse nome de fila é apenas uma convenção didática. A implementação pode escolher outro formato. O ponto essencial é que o pedido de atenção tenha dados suficientes para localizar, derivar ou consultar qual fila de trabalho precisa ser consumida.
O sinal entra em uma fila compartilhada de atenção. Essa fila não guarda o trabalho completo; ela guarda apenas avisos de que alguma fila específica precisa ser olhada. Por exemplo:
attention.marketplace.work
Esse sinal não contém o payload completo. Ele contém apenas o necessário para localizar a fila que precisa de atenção, ou seja, a fila que precisa ser consumida: tenant, tipo do recurso, id do recurso e algumas chaves de roteamento. Para um desenvolvedor .NET, esse sinal pode ser visto como um DTO pequeno, serializado em JSON e publicado internamente pelo próprio sistema.
Com isso, o sistema não precisa manter consumidores permanentes para todas as filas de trabalho. Ele mantém consumidores na fila de atenção. Quando uma mensagem de atenção chega, um worker usa esse aviso para localizar a fila específica, inicia um consumo temporário, consome por um tempo limitado ou até uma quantidade máxima de mensagens, e depois decide se o trabalho acabou ou se precisa republicar outra atenção.
Essa decisão de parar antes de consumir tudo é intencional. A inspiração vem do escalonamento de processos em sistemas operacionais, especialmente do conceito de time sharing. A CPU mantém processos prontos para executar e não deixa um único processo monopolizar o processador indefinidamente. Ela entrega uma fatia de tempo para um processo, interrompe, e depois dá oportunidade para outros processos avançarem. No Attention Queue, a fila de atenção faz um papel parecido com uma fila de processos prontos: cada mensagem de atenção representa uma fila de trabalho que quer uma fatia de processamento. Se ainda houver mensagens depois dessa fatia, a fila entra novamente na disputa por processamento por meio de uma nova mensagem de atenção.
O padrão não tenta ser apenas eficiente; ele tenta ser justo. Cada loja recebe fatias de processamento, evitando que uma loja grande capture a maior parte dos workers e transforme volume em privilégio operacional involuntário.
Como funciona
O padrão funciona como um despachante interno.
Ele não processa o trabalho diretamente. Ele aponta onde existe trabalho. Em uma aplicação .NET, pense nele como um BackgroundService ou worker que recebe um comando pequeno e, a partir dele, decide qual fila de trabalho deve ser consumida.
Em vez de perguntar o tempo todo se há mensagens em cada fila, o sistema recebe um sinal quando algo novo chega. Em vez de deixar um consumidor eterno parado em uma fila vazia, ele inicia um consumidor temporário apenas quando há motivo para isso.
Um fluxo típico seria:
- Um integrador faz uma chamada HTTP para a API do MarketHub solicitando uma sincronização ou enviando uma atualização.
- A API valida a requisição e publica internamente a tarefa na fila
process.marketplace.store_873.work. - Na mesma operação interna, a API publica um sinal em
attention.marketplace.work. - Um worker consome esse sinal de atenção.
- O worker consulta o estado da loja ou integração relacionada.
- Se a loja está desativada, em manutenção, bloqueada por erro de credencial ou removida, a atenção é descartada.
- Se a loja está válida, o worker calcula os limites de consumo: tempo máximo, quantidade máxima de mensagens e concorrência permitida.
- O worker tenta adquirir permissão de rate limit para evitar excesso de consumidores simultâneos na mesma fila. Nesse contexto, rate limit é apenas uma trava de capacidade: quantos consumidores podem trabalhar naquela fila ao mesmo tempo. Esse limite pode ser 1, quando a fila precisa ser consumida de forma serial, ou pode ser maior, como 5 ou 10, quando o domínio permite paralelismo seguro.
- Se permitido, ele inicia um consumidor temporário na fila específica da loja.
- Ele processa mensagens até atingir uma das condições de parada: tempo máximo, quantidade máxima, erro operacional ou fila vazia.
- Ao final, ele verifica se ainda há backlog. Se houver, republica uma nova atenção na fila de atenção. Se não houver, encerra.
- A nova atenção volta para a mesma fila compartilhada de atenção e será consumida no próximo ciclo por algum worker disponível. Pode ser o mesmo worker ou outro. O ponto é que a fila de uma loja grande não monopoliza o processamento indefinidamente.
Encontrar a fila vazia não é erro. Uma atenção pode chegar atrasada: quando o worker olha a fila de trabalho, ela já pode ter sido consumida por outro ciclo. Nesse caso, ele apenas confirma a atenção e encerra.
O ponto importante é que o sinal de atenção é barato, pequeno e repetível.
Ele não precisa representar exatamente uma mensagem de trabalho. Ele representa uma intenção: essa fila merece ser observada e provavelmente precisa ser consumida.
Por isso, o pedido de atenção deve ser idempotente. O sistema precisa aceitar a possibilidade de receber duas ou mais atenções para a mesma loja sem duplicar processamento indevido. No pior caso, uma atenção extra inicia uma tentativa que encontra a fila vazia, é bloqueada pelo limite de concorrência, ou percebe que o backlog já foi processado por outro ciclo.
Isso muda a forma de pensar. A fila de atenção não é a fila de trabalho. Ela é a fila de coordenação. Ela funciona como uma fila de escalonamento: decide qual fila de trabalho recebe a próxima fatia de processamento.
Exemplo completo
No MarketHub, cada loja possui uma fila própria:
process.marketplace.store_{storeId}.work
O conjunto de integrações com marketplaces possui uma fila de atenção:
attention.marketplace.work
Quando a loja store-873 precisa sincronizar pedidos ou atualizar estoque em um marketplace, o integrador faz uma única chamada HTTP para a API. Para quem integra, a operação termina aí: ele enviou a solicitação para o MarketHub. Quem sabe que também precisa gerar um pedido de atenção é a própria API.
Depois de receber a chamada HTTP, a API faz duas publicações internas no broker. Essa dupla publicação precisa ser tratada como uma unidade operacional: não basta publicar a mensagem de trabalho e torcer para que o pedido de atenção também seja publicado. Se a primeira publicação funcionar e a segunda falhar, a fila da loja pode ficar com trabalho pendente sem nenhum sinal para acionar o consumo.
Existem várias formas de proteger esse ponto, dependendo do nível de garantia exigido pela aplicação: usar confirmação de publicação do broker, aplicar outbox pattern, fazer retry idempotente da publicação de atenção ou manter uma reconciliação periódica que encontre filas com backlog sem atenção recente. O detalhe da técnica pode variar, mas a decisão arquitetural é a mesma: mensagem de trabalho e pedido de atenção fazem parte da mesma intenção operacional.
Nos exemplos abaixo, aparecem três termos comuns em RabbitMQ. O exchange é o ponto onde a aplicação publica a mensagem. A routingKey é a chave usada para decidir o caminho da mensagem. A queue é a fila onde a mensagem fica armazenada até algum consumidor processá-la.
A primeira publicação carrega o trabalho real:
exchange: process.marketplace routingKey: store.store-873 body: tarefa completa de sincronização
A segunda publicação carrega apenas o pedido de atenção:
{
"tenantId": "seller-group-a",
"storeId": "store-873",
"marketplace": "mercado-livre",
"priority": "normal"
}
O worker de atenção recebe esse segundo evento e monta a fila real:
process.marketplace.store_873.work
Antes de consumir, aplica uma política:
maxConsumptionTimeSeconds = 20 maxMessages = 100 maxConcurrentConsumers = 2
Nesse exemplo, maxConcurrentConsumers = 2 significa que no máximo dois consumidores podem processar a fila dessa loja ao mesmo tempo. Em outro cenário, esse valor poderia ser 1, garantindo um único consumidor ativo por fila de trabalho. Isso é útil quando a ordem dos eventos importa, quando há risco de conflito em atualizações de estoque, ou quando a API do marketplace exige chamadas mais controladas. Se a loja tiver um plano maior, integração estável e operações independentes, o limite poderia ser 10.
Então ele tenta adquirir um token de concorrência para essa loja. Se já existem consumidores suficientes processando essa fila, a atenção é republicada para uma tentativa futura.
Se houver permissão, o worker consome até 100 mensagens ou até 20 segundos. Ele não continua até o fim da fila porque isso permitiria que uma única loja ruidosa ocupasse o worker por tempo demais. Se ainda restarem mensagens, ele republica uma nova atenção. Essa nova atenção volta para attention.marketplace.work e será disputada pelos consumidores dessa fila de atenção. Se a fila estiver vazia, ele encerra.
Implementação
O padrão pode ser implementado com cinco componentes.
Ele não exige uma abstração genérica de mensageria. Os exemplos a seguir usam vocabulário comum em aplicações .NET e RabbitMQ, mas a parte mais importante é o contrato explícito do domínio: uma mensagem de trabalho, uma mensagem de atenção, um worker que entende esse contrato e uma política clara de consumo.
O primeiro é a fila de trabalho granular. Ela guarda mensagens reais por entidade, cliente, loja, conta ou qualquer unidade que precise de isolamento. É nela que está o payload que a regra de negócio vai processar.
O segundo é a fila de atenção agregada. Ela recebe sinais pequenos agrupados por tipo. Essa fila é consumida por poucos workers permanentes.
O terceiro é o envelope de atenção. Ele contém os identificadores mínimos para localizar a fila de trabalho que precisa de atenção. Esse envelope deve ser seguro para repetição: publicar ou consumir o mesmo pedido mais de uma vez não pode corromper o estado do sistema. Em C#, ele seria uma classe simples, por exemplo:
public sealed class AttentionRequest
{
public required string TenantId { get; init; }
public required string StoreId { get; init; }
public required string Marketplace { get; init; }
}
O quarto é o worker de atenção. Ele valida o estado da entidade, inicia um consumidor temporário, processa em lote controlado e decide se precisa de nova atenção. Esse worker não precisa esconder RabbitMQ atrás de uma abstração genérica; ele pode chamar APIs explícitas do broker ou serviços internos próprios.
O quinto é o controle de concorrência. Ele normalmente é apoiado por Redis, banco de dados ou lock distribuído, para impedir que múltiplos workers processem a mesma fila além do limite permitido. Esse limite não precisa ser maior que 1. Em muitos casos, o valor correto é exatamente 1 consumidor ativo por fila de trabalho. Em outros, o limite pode ser 10 ou mais, desde que o processamento seja independente, idempotente e seguro para paralelismo.
Em uma base .NET, esses componentes poderiam aparecer como contratos próprios do sistema:
public interface IAttentionPublisher
{
Task PublishAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public interface IAttentionWorker
{
Task<AttentionResult> ProcessAsync(AttentionRequest request, CancellationToken cancellationToken);
}
public enum AttentionResult
{
Done,
NeedMoreAttention
}
Essas interfaces não precisam prometer que servem para qualquer broker ou qualquer caso de mensageria. Elas existem para representar uma decisão arquitetural específica: publicar pedidos de atenção e consumir filas de trabalho sob demanda.
Um pseudocódigo possível:
No pseudocódigo, ack attention significa confirmar ao broker que aquela mensagem de atenção foi tratada e pode sair da fila. Se o worker falhar antes do ack, o broker pode tentar entregar a mesma atenção de novo, dependendo da configuração. Esse é mais um motivo para o pedido de atenção ser idempotente. O oposto do ack costuma ser chamado de nack, usado quando a mensagem não foi processada com sucesso e deve seguir a política de erro ou retentativa.
on attention_received(attention):
resource = load_resource(attention.resource_id)
if resource cannot receive processing:
ack attention
return
queue_name = build_work_queue_name(resource)
if rate_limit_blocked(queue_name):
republish attention
ack attention
return
if queue_does_not_exist(queue_name):
ack attention
return
if queue_is_empty(queue_name):
ack attention
return
consume_until(
queue = queue_name,
max_messages = resource.max_messages,
max_time = resource.max_time
)
if queue_has_remaining_messages(queue_name):
republish attention
ack attention
O republish attention não é uma recursão nem uma chamada imediata ao mesmo worker. Ele coloca um novo pedido no fim da fila de atenção. Depois disso, o worker atual finaliza o ciclo e fica livre para pegar o próximo pedido disponível. O broker entrega a nova atenção quando ela chegar à vez dela, respeitando a concorrência e a ordem operacional da fila.
Em RabbitMQ, uma implementação concreta pode usar uma topologia semelhante. O binding é a regra que liga um exchange a uma queue.
exchange: attention.marketplace queue: attention.marketplace.work binding: store.* exchange: process.marketplace queue: process.marketplace.store_873.work binding: store.store-873
A API publica o payload completo na fila de trabalho e publica um envelope pequeno na fila de atenção:
HTTP request from integrator API validates request API publishes process event API publishes attention event
Na implementação real, esses dois últimos passos devem ter uma estratégia explícita de consistência. Se não houver uma transação única envolvendo tudo, a aplicação precisa de confirmação, retry, outbox ou reconciliação para não deixar trabalho sem atenção.
O worker de atenção, por sua vez, não precisa conhecer todas as lojas antecipadamente. Ele só precisa saber transformar o envelope de atenção em nome de fila, política de consumo e chave de controle de concorrência.
Observabilidade
Attention Queue só é confortável de operar quando o sistema mostra claramente onde há trabalho parado, onde há excesso de atenção e onde há bloqueio por política.
Algumas métricas úteis:
| Métrica | O que revela |
|---|---|
| Quantidade de mensagens por fila de loja | Quais lojas estão acumulando backlog |
| Idade da mensagem mais antiga por fila | Há quanto tempo a loja mais atrasada espera processamento |
| Número de atenções republicadas | Quais filas precisam de muitos ciclos para esvaziar |
| Atenções descartadas por loja desativada ou inválida | Quanto trabalho está sendo ignorado por estado operacional |
| Bloqueios por rate limit | Quais lojas estão batendo no limite de concorrência ou SLA |
| Tempo médio para zerar backlog | Quanto tempo o sistema leva para recuperar uma fila com trabalho pendente |
Essas métricas ajudam a separar problemas diferentes. Uma loja pode estar lenta porque tem backlog real, porque está limitada por plano, porque a integração está bloqueada, porque há muitas atenções repetidas, ou porque os workers disponíveis não são suficientes. Sem essas medidas, o padrão continua funcionando, mas fica difícil explicar seu comportamento em produção.
Quando não usar
Attention Queue não deve ser tratado como solução padrão para qualquer processamento assíncrono.
Se o sistema tem poucas filas, volume previsível e consumidores permanentes baratos de manter, o padrão pode adicionar complexidade desnecessária. Se uma fila única já atende bem, com latência aceitável e sem problemas de isolamento, talvez não exista dor suficiente para justificar filas granulares e pedidos de atenção.
Também não é uma boa escolha quando o processamento precisa obedecer uma ordem estritamente global entre todas as mensagens. O padrão favorece isolamento e justiça entre filas, não uma ordenação única do sistema inteiro.
Outro ponto é custo operacional. Filas dinâmicas exigem convenção de nomes, criação, remoção, monitoramento e capacidade de diagnóstico. Se o broker ou o time ainda não consegue operar muitas filas com segurança, é melhor amadurecer essa base antes de adotar o padrão.
Benefícios
O benefício principal do padrão é alinhar consumo com necessidade real.
Ele permite manter milhares ou milhões de filas lógicas sem exigir milhares ou milhões de consumidores ativos. O sistema fica mais elástico porque consumidores aparecem quando há backlog e desaparecem quando o trabalho acaba.
Também melhora o isolamento. Uma entidade ruidosa não precisa contaminar o fluxo das demais, porque cada entidade pode ter sua fila, seus limites e sua política de consumo.
Outro benefício é justiça operacional, ou fairness, entre lojas. O padrão distribui o processamento em fatias e evita que uma loja grande capture a maior parte dos workers apenas por ter mais volume. Ela pode receber mais atenção se a política permitir, mas isso passa a ser uma decisão explícita do sistema, não um efeito colateral do backlog.
Outro benefício é a governança operacional. Como o worker de atenção passa por uma etapa de enriquecimento antes de consumir, ele pode verificar estado, permissões, locks, manutenção, prioridade e limites antes de gastar esforço processando mensagens.
O padrão também abre espaço para acordos comerciais diferentes. Como a atenção passa por uma política interna antes de virar consumo real, o sistema pode dar tratamento diferente para lojas em planos diferentes: mais consumidores simultâneos, janelas de consumo maiores, mais mensagens por ciclo, prioridade maior na republicação da atenção ou regras específicas para campanhas e datas sazonais.
Um exemplo simples:
| Plano | Consumidores simultâneos por loja | Mensagens por ciclo |
|---|---|---|
| Basic | 1 | 50 |
| Pro | 3 | 200 |
| Enterprise | 10 | 1000 |
Isso permite transformar capacidade de processamento em SLA comercial sem expor a complexidade de filas para o integrador.
Há também um ganho de resiliência: se o processamento não terminar em um ciclo, a própria atenção pode ser republicada. O trabalho progride em fatias, como no time sharing da CPU. O sistema não precisa resolver todo o backlog de uma vez, e uma fila muito cheia não prende o worker indefinidamente.
Em resumo, o padrão Attention Queue é útil quando há muitas filas específicas, volume irregular, necessidade de isolamento e custo alto para manter consumidores permanentes.
Ele transforma processamento contínuo em processamento sob demanda.
A fila de atenção não carrega o peso do trabalho. Ela carrega a consciência de que existe trabalho.

Oragon.RabbitMQ 1.6 – Welcome .NET 10
Desde a versão 1.1.0 (janeiro/2025), o Oragon.RabbitMQ passou por 6 releases com mais de 70 commits, resultando em +3.894 linhas adicionadas e -1.245 removidas ao longo de 112 arquivos.
A seguir, um resumo das principais novidades.
ler mais…
RabbitMQ: Filas efêmeras
Ao pensar em filas, é comum pensarmos em filas com um ciclo de vida muito longo, filas que existem enquanto a aplicação existir.
É comum pensarmos em filas como recursos estáticos que fazem parte dos requisitos de funcionamento da aplicação, nascendo quando a aplicação é implantada em produção pela primeira vez e somente deixando de existir somente quando a aplicação é desativada ou substituída.
Hoje vamos abordar filas que possuem um ciclo de vida diferente, um ciclo de vida absolutamente curto, filas que podem durar de poucos milissegundos e semanas, e eventualmente até meses ou anos.
Não adianta torcer o nariz. Muitos aplicativos que estão no teu celular hoje fazem uso desse recurso em seus backends.
ler mais…
Oragon.RabbitMQ 1.1 – Reduzindo Alocações
Então esse foi o dia que queimei a lingua!
Uma das criticas que faço às publicações que falam sobre ganhos absurdos de 50%, 80% e até mais de 100% de performance onde todas as variáveis se mantiveram as mesmas, é que afinal: Ganhamos 100% ou deixamos de perder 50%?
Como o velho ditado “A estatística é a arte de torturar os números até que eles confessem o que você quer demonstrar”.
Bem, eu não passei batido à minha própria critica! Hoje vou falar sobre a redução nas alocações de respostas.
ler mais…Conteúdo e Posicionamento


.NET + Cloud Native + Cloud Agnostic
.NET | DevOps | Microservices | Containers | Continuous Delivery
.NET muito além do .NET
O mínimo de infra que todo dev e/ou arquiteto deveria saber
Aplicações distribuídas e comunicação entre serviços (RabbitMQ / gRPC)
Containers, Docker e Kubernetes
RabbitMQ e Mensageria e comunicação assíncrona entre aplicações e serviços
Arquitetura de Software e Arquitetura de Solução com foco no melhor aproveitamento em projetos .NET
Nossos números
Desde 2002 trabalhando com desenvolvimento de software
Desde 2002 ajudando outros devs
Desde 2010 trabalhando exclusivamente como arquiteto
Contas atingidas no telegram/facebook
Alunos
Microsoft MVP
Títulos e Associações

2023-2024
2024-2025
2025-2026

2024-2025
2025-2026
2026-2027
Conteúdo Gratuito
Tudo que está aqui no gaGO.io é conteúdo gratuito, feito para ajudar desenvolvedores dos mais variados níveis.
Cursos
Tenho também alguns programas de acompanhamento. Esses programas tem a função de ajudar desenvolvedores em áreas específicas ou de forma mais abrangente na jornada do arquiteto.