
Embora não seja comum ver conteúdo sobre o assunto, Operators está no coração do Kubernetes e esse definitivamente é um dos temas mais legais na minha opinião no que diz respeito ao projeto.
Nessa série composta por 3 posts, vamos abordar step-by-step os 2 operators do RabbitMQ, mas hoje vamos primeiro elucidar o que são Operators e CRD’s.
Imagina que legal seria poder escrever um manifesto do Kubernetes parecido com isso:
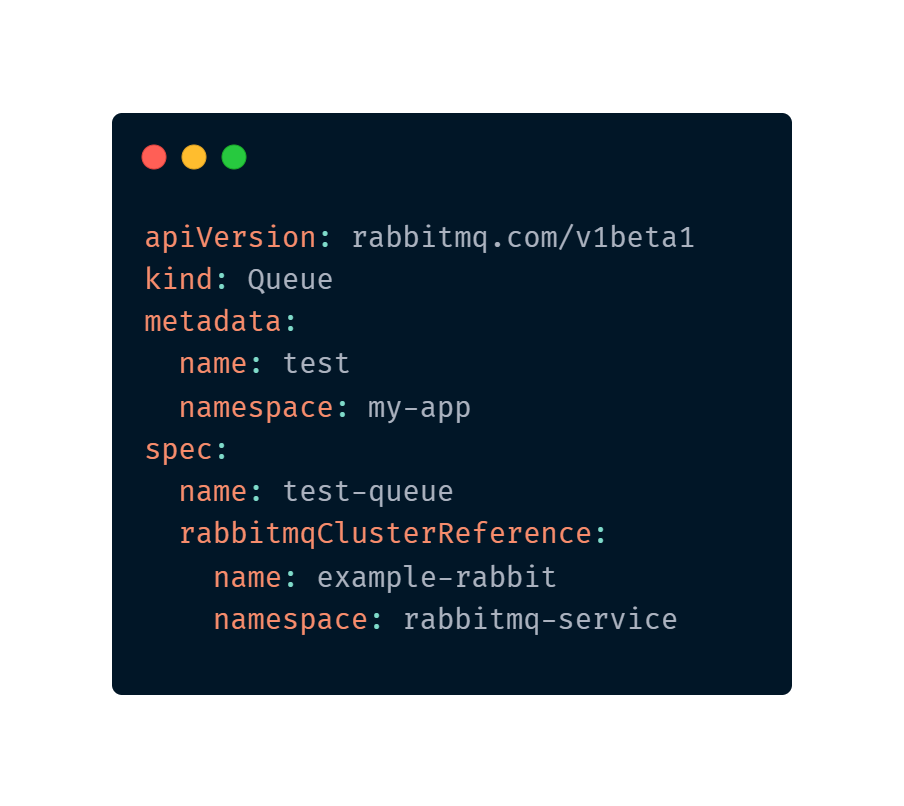
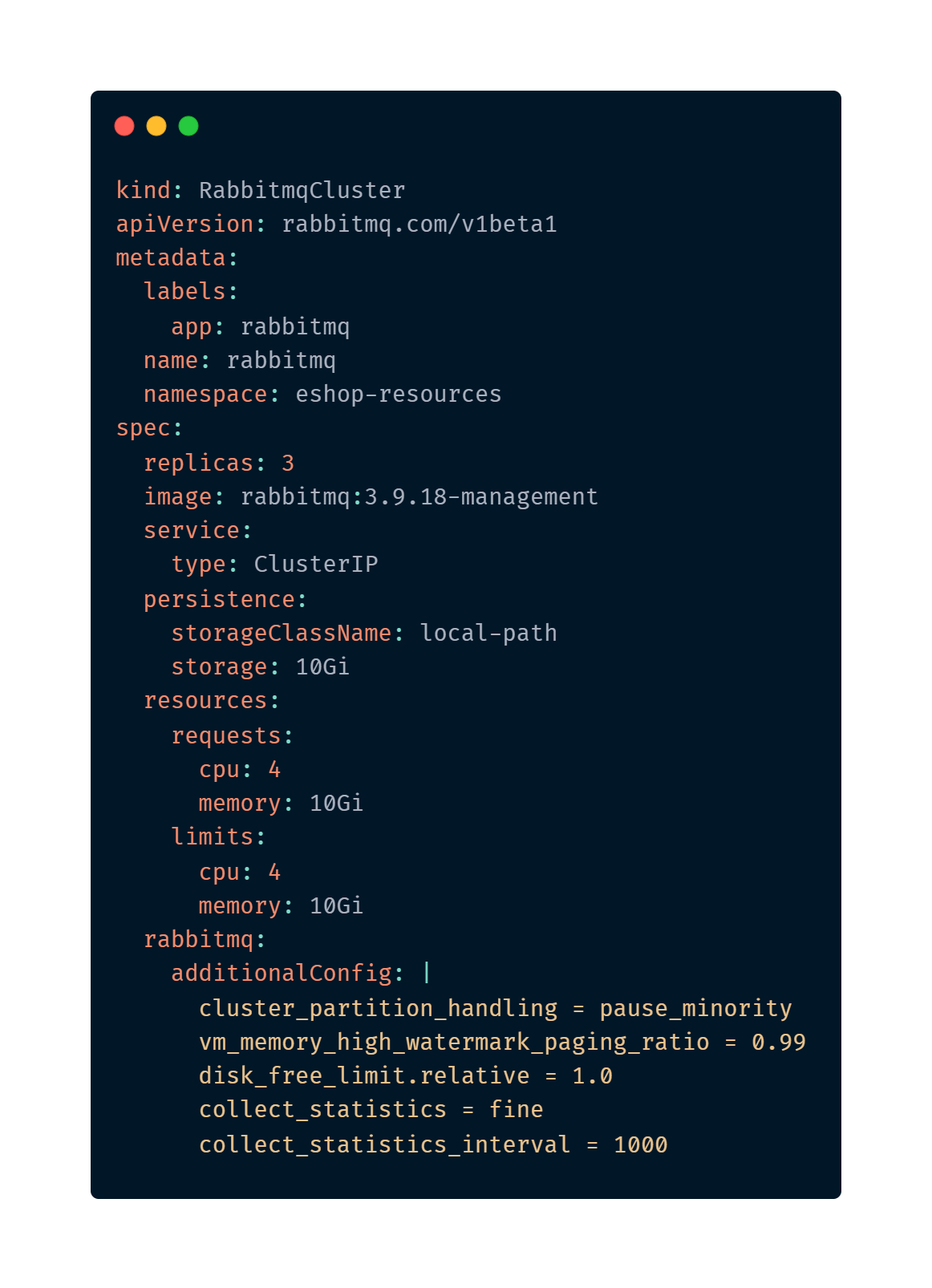
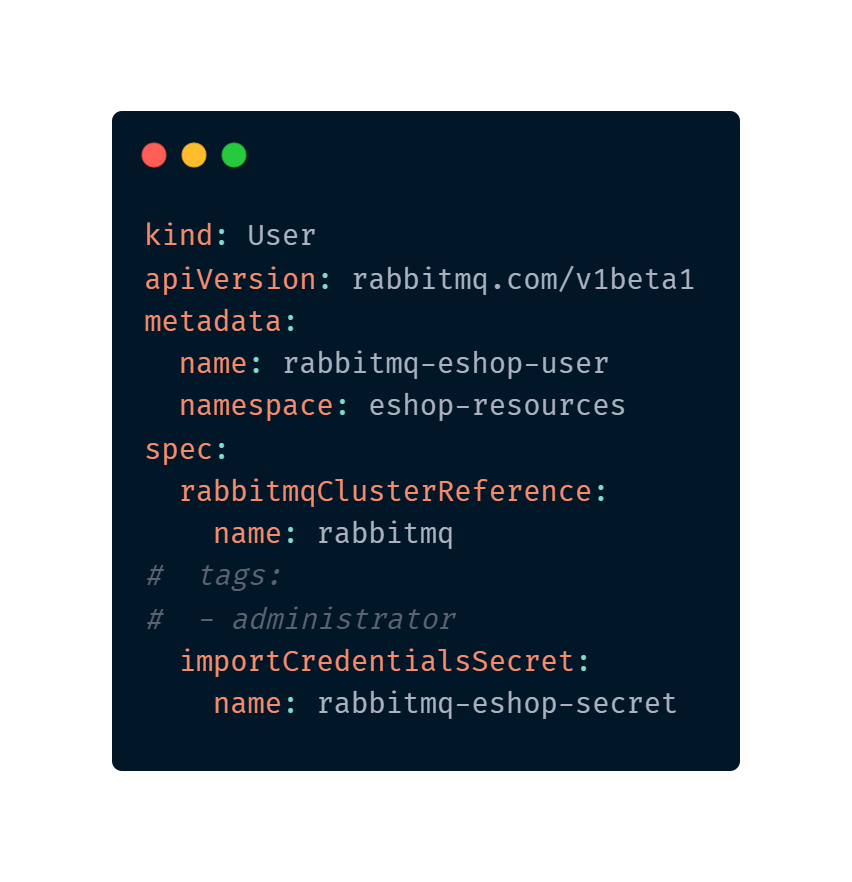
Se você viu o último post, o primeiro da série sobre Cloud Native (Cloud Native | 1 – Definindo Cloud Native) deve ter visto o que Brandan Burns, Ex-líder de engenharia do Kubernetes, de google de 2008 a 2016 disse sobre Cloud Native.
Pegando como ponto de partida a visão do Burns, quando ele diz:
…
Eu posso fazer basicamente o que eu preciso fazer de forma programática, em vez de criar um ticket em um sistema e alguém pegar uma máquina física e colocar em um rack.
É muito mais como se eu só quisesse dizer o que é realmente necessário para criar algo, via API.
…
Brandan Burns
É disso que ele falava, de apenas definir o que precisa. E de forma simplificada, de forma direta ao ponto.
E podemos em um cluster Kubernetes definir POD’s, Deployments, StatefulSets etc, mas podemos também usar definições customizadas para criar objetos de domínio específico, como os que vimos nas imagens.
Podemos até criar as nossas próprias estruturas.
E vou detalhar isso nesse post.
Eu não espero que você crie suas próprias extensões para o Kubernetes, embora pudesse, não é essa a intenção. Minha intenção é mostrar que há esse ponto de extensão, e como funciona. Isso reduz a curva de aprendizado. Nos próximos posts falarei mais especificamente dos operators do RabbitMQ, aqui vamos entender o que são operators e CRD’s.
Extensibilidade no Kubernetes
O Kubernetes permite extensibilidade de diversas formas em diversos momentos. Nós aqui, nessa série, vamos dar atenção a somente 2 desses pontos:
- CRD’s (custom resource definitions)
- e Operators.
Operators
Operators são aplicações que implantamos no cluster kubernetes e elas interagem com o cluster Kubernetes em si, se tornando parte dele. Em vez dessa aplicação entregar uma funcionalidade uma API de negócio, ela entrega um comportamento de infraestrutura.
São POD’s com aplicações que sabem lidar com a API do Kubernetes e usam dessa integração para estender as capacidades de um ambiente kubernetes.
Do ponto de vista do arquiteto, você poderia ir ao https://operatorhub.io/ e buscar por um operator de PostgreSQL (https://operatorhub.io/?category=Database&keyword=Postgres), por exemplo.
Se fizesse isso agora, junto comigo, enquanto escrevo esse post, encontraria esses 8 operators.
O próximo passo seria entrar em cada um desses links e entender o que cada um desses operators é capaz de fazer. Cada operator implementa recursos, e podem ser melhores, piores, mais ou menos completos, mais ou menos estáveis.
Nesse momento é bom nos debruçarmos em testes e análises. É importante entender o operator certo, porque é muito incomum que operators diferentes sejam complementares.
Essa interoperabilidade entre operators não é comum, portanto precisamos lidar com muito cuidado e cautela da escolha do operator.
O operator é implantado em geral com um yaml.
Por exemplo eu busquei um operator para PostgreSQL,
- encontrei o EDB Postgres for Kubernetes,
- descobri que era pago,
- mas também, que era fork de outro operator o CloudNativePG,
- que por sua vez é gratuito.
E ao analisar o CloudNativePG percebi que beira a perfeição.
A instalação funciona assim:
kubectl apply -f https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/main/releases/cnpg-1.15.0.yaml
Funciona assim: Você roda esse comando. O YAML em questão possui diversas definições como Pods, CRD’s, Roles. Um em específico, o ClusterRole descreverá as permissões que esse operator precisa no cluster. Ele narra quais permissões seu operator precisa para poder se integrar ao Kubernetes. Essas permissões permitem que seu componente escute eventos, e envie comandos.
Parece bom demais para ser verdade? Não é?!
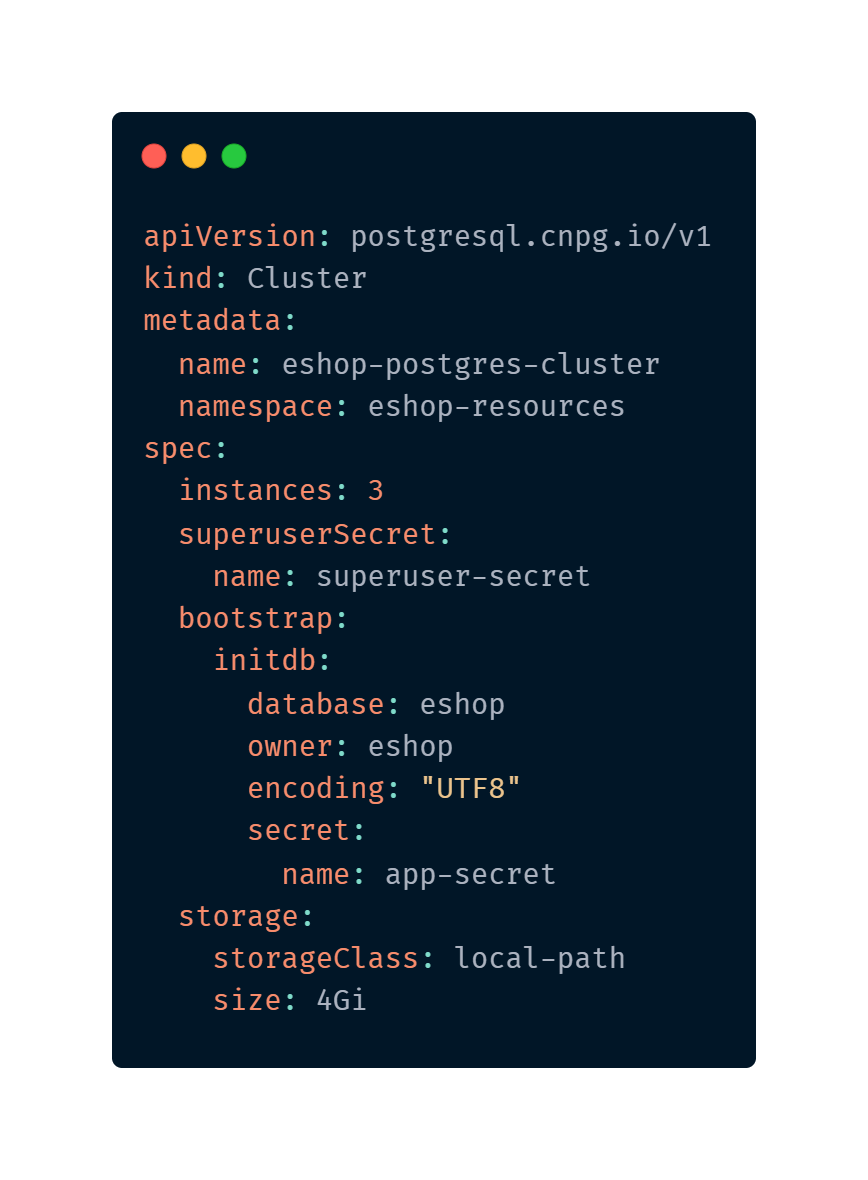
Voltando ao nosso operator, o CloudNativePG, olhando a documentação conseguimos ver que deplois de implantado, ele nos permite aplicar essa configuração abaixo para criar um cluster PostgreSQL.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
instances: 3
primaryUpdateStrategy: unsupervised
storage:
size: 1Gi
E parece incrível. Ele se preocupa com os detalhes de cada um dos componentes e configurações necessárias para criar o cluster. Claro que a configuração é extensa, tem muitos detalhes, e fazer o setup certo vai levar algum tempo.
O próximo passo é testar e avaliar. Para isso preciso de um Kubernetes rodando. E no meu caso eu usei o k3d para criar um ambiente kubernetes de PoC.
Mas qual é o papel do Operator?
O Operator é um componente que instalamos no cluster kubernetes que passa a fazer parte do cluster, ele passa a estender as capacidades do cluster Kubernetes.
No nosso caso, o CloudNativePG tem a função de era criar e cuidar de um cluster de banco, cuidando do backup, recriação de nós, eleição de master.
Já no cenário do RabbitMQ temos 2 operators e vou abordá-los em 2 posts dessa série aqui. Um operator criará o cluster e outro operator que criará os objetos (filas, exchanges, binds) do RabbitMQ.
Resource Definition
Toda configuração de implantação no kubernetes tem pelo menos 1 ou mais objetos. Cada objeto possui no mínimo algumas pripriedades:
apiVersion: Descreve a API e versão da API. É como um identificador do produto/componente e a versão dele.
kind: É o tipo de objeto tratado por esse componente.
metadata: são metadados adicionais.
spec: aqui entra a CRD, a spec é mutante, cada Kind/apiVersion possui um schema específico para a spec. E é na spec que definimos as estruturas de dados específicas de cada componente.
CRD – Custom Resource Definition
As CRD’s estendem o Kubernetes permitindo definir novos formatos de Yaml. Funciona como um JSONSchema ou XMLSchema, em que ele define que a partir da instalação da CRD, um formato novo de yaml pode ser criado.
Por exemplo a partir da CRD que define Vhosts (abaixo):
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.8.0
creationTimestamp: null
name: vhosts.rabbitmq.com
spec:
group: rabbitmq.com
names:
categories:
- all
- rabbitmq
kind: Vhost
listKind: VhostList
plural: vhosts
singular: vhost
scope: Namespaced
versions:
- name: v1beta1
schema:
openAPIV3Schema:
description: Vhost is the Schema for the vhosts API
properties:
apiVersion:
description: 'APIVersion defines the versioned schema of this representation
of an object. Servers should convert recognized schemas to the latest
internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources'
type: string
kind:
description: 'Kind is a string value representing the REST resource this
object represents. Servers may infer this from the endpoint the client
submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds'
type: string
metadata:
type: object
spec:
description: VhostSpec defines the desired state of Vhost
properties:
name:
description: Name of the vhost; see https://www.rabbitmq.com/vhosts.html.
type: string
rabbitmqClusterReference:
description: Reference to the RabbitmqCluster that the vhost will
be created in. Required property.
properties:
connectionSecret:
description: Secret contains the http management uri for the RabbitMQ
cluster. The Secret must contain the key `uri`, `username` and
`password` or operator will error. Have to set either name or
connectionSecret, but not both.
properties:
name:
description: 'Name of the referent. More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/names/#names
TODO: Add other useful fields. apiVersion, kind, uid?'
type: string
type: object
name:
description: The name of the RabbitMQ cluster to reference. Have
to set either name or connectionSecret, but not both.
type: string
namespace:
description: The namespace of the RabbitMQ cluster to reference.
Defaults to the namespace of the requested resource if omitted.
type: string
type: object
tags:
items:
type: string
type: array
tracing:
type: boolean
required:
- name
- rabbitmqClusterReference
type: object
status:
description: VhostStatus defines the observed state of Vhost
properties:
conditions:
items:
properties:
lastTransitionTime:
description: The last time this Condition status changed.
format: date-time
type: string
message:
description: Full text reason for current status of the condition.
type: string
reason:
description: One word, camel-case reason for current status
of the condition.
type: string
status:
description: True, False, or Unknown
type: string
type:
description: Type indicates the scope of the custom resource
status addressed by the condition.
type: string
required:
- status
- type
type: object
type: array
observedGeneration:
description: observedGeneration is the most recent successful generation
observed for this Vhost. It corresponds to the Vhost's generation,
which is updated on mutation by the API Server.
format: int64
type: integer
type: object
type: object
served: true
storage: true
subresources:
status: {}
status:
acceptedNames:
kind: ""
plural: ""
conditions: []
storedVersions: []
Uma vez que essa CRD esteja implantada no cluster podemos enviar para o Kubernetes um yaml assim:
apiVersion: rabbitmq.com/v1beta1
kind: Vhost
metadata:
name: test-vhost
spec:
name: test-vhost
rabbitmqClusterReference:
name: test
Em geral as CRD’s são parte do arquivo de manifesto (yaml) do Operator. É importante entendermos porque é olhando para elas que vamos achar os detalhes mal documentados do Operator.
Quando você instala o operator, as CRD’s (ou pelo menos as principais) são instaladas, habilitando você a usá-las mais tarde.
Como um schema foi definido, o próprio Kubernetes lida com a validação do formato. O operator já valida a consistência e se estiver tudo certo, ele tem a capacidade de chamar a API do Kubernetes para criar novos Pods (do seu cluster) com todas as principais boas práticas.
Da mesma forma como com classes base da CLR, como string, int, double, boolean, object, conseguimos construir novas classes e usá-las, as CRD’s fazem o mesmo no nível das configurações do kubernetes.
O que isso tem a ver com Cloud Native?
O resultado desses operators é que temos um ambiente em que simplesmente definimos o que precisamos. No nível mais alto, não nos preocupamos se o cluster precisa de novos nós para atender um rollout. Simplesmente descrevemos o que precisamos.
Já quando pensamos na criação de um cluster PostgreSQL, não nos preocupamos com detalhes do processo de criação e configuração detalhada desses pods. Isso é abstraído para que possamos apenas expressar que precisamos de um cluster com X parâmetros. E a partir daí a mágica acontece.
Mas quando pensamos no RabbitMQ, temos também a oportundiade de criar filas, exchanges, vhosts etc. Sem que precisemos nos preocupar com detalhes de como fazer isso.
Era isso que o Brandan Burns dizia, era sobre trabalhar com a cloud no DNA, como se fizesse parte desde sempre, usando abstrações que simplificam nossa vida.
Conclusão
É nosso papel definindo uma arquitetura, em um ambiente Kubernetes, pensar em quais operators queremos no nosso cluster. Seja no ambiente de produção quanto no ambiente de desenvolvimento.
Isso deve fazer parte do processo de tomada de decisão, pois hora vamos querer usar serviços PaaS, gerenciados, hora vamos querer usar Operators.
Hora vamos usar operators apenas para subir ambientes de testes, isolados, para teste local. Hora vamos querer usar os operators em produção.
Cada caso é um caso.
Se você pensa que “O cara do DevOps” vai resolver isso por você, então, dificilmente. O conhecimento específico sobre as tecnologias é do arquiteto, não dele.
É você, arquiteto, que tem de ter consciência e tomar decisão se o RabbitMQ Messaging Topology Operator faz sentido ou não no seu ambiente. Se o RabbitMQ Cluster Operator faz ou não sentido.
Saber da existência dos operators, é o primeiro passo.
O segundo é conhecer Operators úteis, que fariam sentido nos seus projetos. Mesmo que não seja em produção.
Então aqui vão minhas dicas:
- RabbitMQ Cluster Kubernetes Operator for Kubernetes | link
- RabbitMQ Messaging Topology Operator for Kubernetes | link
- CloudNativePG – PostgreSQL Operator | link
Que tal fazer um teste?
Agora que você sabe da existência de Operators e CRD’s, e no próximo post dessa série detalhar como subir o RabbitMQ Cluster Kubernetes Operator for Kubernetes usando k3D.





0 comentários