
Será que o RabbitMQ consome demais?
Se você pensava que ele consumia muita memória, está enganado.
Ele só deixa em memória as mensagens que ele pretende entregar mais cedo para os consumidores.
Então depende diretamente do throughput.
Ele vai tentar balancear para não consumir muito, mas se o volume trafegado é intenso (chegada de mensagens e entrega de mensagens), significa que você terá um consumo de memória maior.
O óbvio que precisa ser dito
O RabbitMQ precisa que a mensagem esteja em memória para que ele entregue para qualquer cliente. Ou seja, por mais que ela exista no disco, ele traz para a memória para poder entregar via rede para qualquer cosumidor conectado a ele.
Então naturalmente ele vai precisar de memória na proporção em que haja publicação e consumo.
Deve ser considerado que, se uma mensagem tem 2 MiB, por exemplo, ela vai consumir ao menos esses 2 MiB.
Ou seja, o consumo de memória também é influenciado pelo tamanho das mensagens.
Consumidores, consomem memória
Conexões e Canais consumirão memória também. Isso tem de ser considerado.
Quanto consome um canal ou conexão? Não dá para prever. Depende de muitas variáveis. A melhor forma de chegar a um número coerente é medindo.
Exemplo real e prático
Nessa instância, por exemplo, temos mais de 1milhão e 100 mil mensagens, e um consumo de apenas 265 MiB de RAM.
Você pode ver, na lista de filas, abaixo, que a fila com mais mensagens tem 602MiB de mensagens persistidas, e somente 6.3 MiB em memória. Cerca de 10% das mensagens apenas.
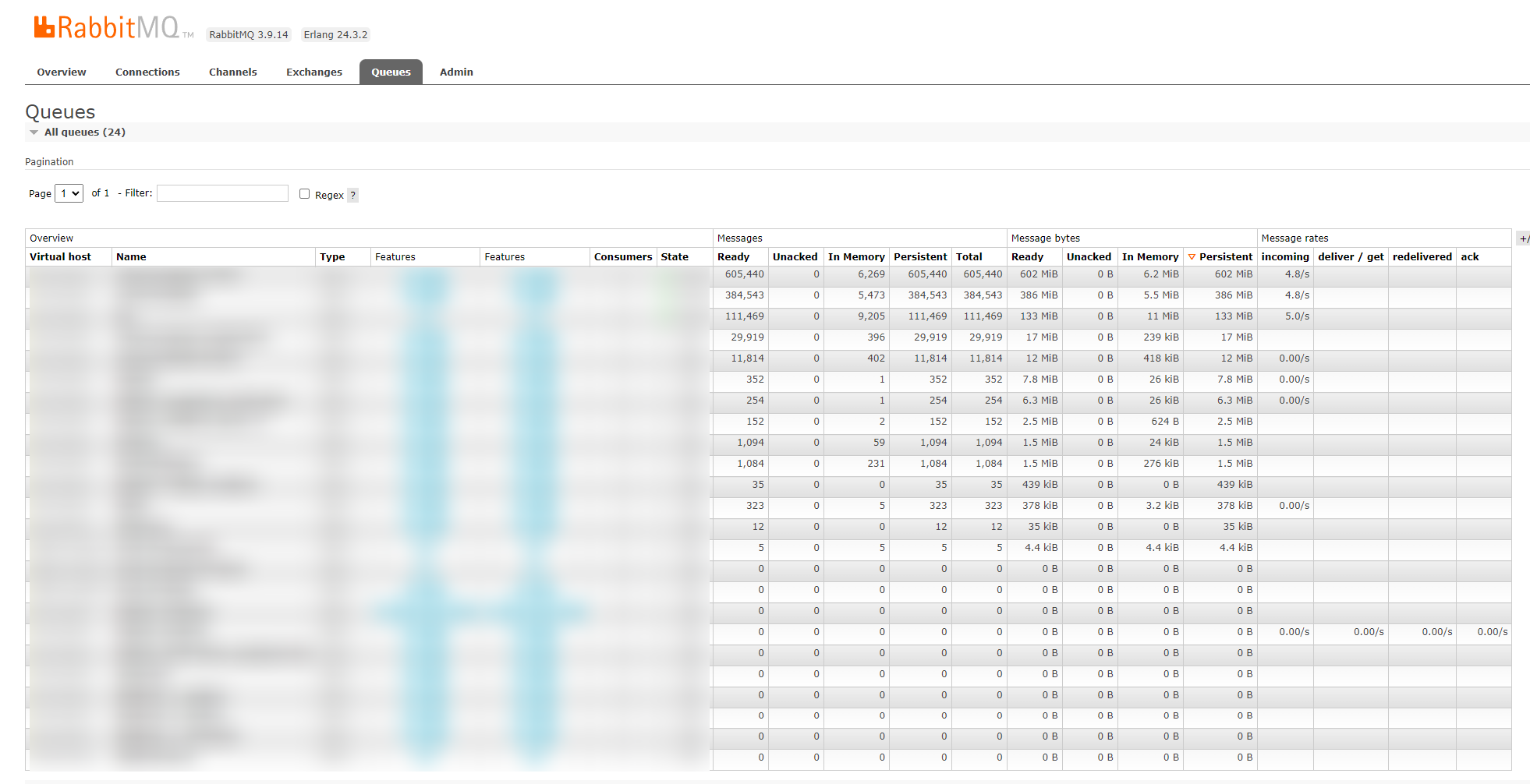
Nesse deployment, o RabbitMQ consome 3.2 GB de disco.
Então, disco também não é um problema!
Uma vantagem
Uma das vantagens do modelo de filas em relação à streams é exatamente o consumo de disco.
Pela natureza das filas, de apagar as mensagens após a confirmação de processamento, sua preocupação com disco só ocorre quando os processos param de consumir.
Esse comportamento ajuda na manutenção do consumo de disco, evitando paralisações por esse motivo. Entretanto, muitas filas, com milhões de mensagens grandes e não processadas, podem consumir todo o disco. Mas por sorte, basta processarmos para devolvermos o espaço alocado. Isso não pode ser feito, ao menos não dessa forma, com streams.
Com filas, vamos consumir mais disco somente quando os consumidores pararem, e nesse meu exemplo, os consumidores estão parados há 2 anos porque sequer foram desenvolvidos ainda.
E na medida que as mensagens forem consumidas, e processadas, o RabbitMQ vai liberando o espaço usado. Ao fim do processamento serão apenas alguns megas de disco consumidos.






0 comentários