
O que faz Microsserviços estar no coração do Cloud Native? Seria a forma de distribuir aplicações? Seria a forma de lidar com complexidade? Seria pela forma como usa recurso de cloud?
Qual é a relação entre Microsserviços e Cloud Native?
Hoje vamos abordar essa relação de proximidade!
Não podemos falar da história dos Microsserviços sem citar Google e Netflix, berçários do que hoje conhecemos como Microsserviços. Apresentações vagas sobre os conceitos permearam os anos 2000, no entanto cases significantes apareceram apenas na década seguinte. E um dos mais citados é a Netflix.
Vou recorrer a uma apresentação realizada pelo Cloud Architect responsável pela Netflix, hoje VP na AWS: Adrian Cockcroft.
Se hoje referenciamos Sam Newman como um dos maiores nomes do tema, não podemos nos esquecer de Adrian Cockcroft. Foi ele quem idealizou e compartilhou a implementação mais aclamada de Microsserviços. Ele estava no local e no momento certo e teve de tomar as decisões que levaram a esse desenho.
Ao mesmo tempo ele fez isso à luz de demandas e problemas demandaram esse desenho, o que é muito significativo.
Em 2014, Adrian Cockcroft que já havia sido Diretor de Web Engineering de 2007 a 2010 e Cloud Architect de 2010 a 2013, nos presenteou com a apresentação:
Migrating to Cloud Native with Microservices, realizada no GOTO Berlin.
Você pode ver os slides aqui.
A apresentação é especial porque além de elucidar como implementaram microsserviços, mas ele também nos trás os elementos que nos ajudam a entender o contexto:
- Porque usaram?
- O que queriam?
- Qual era a intenção?
- O que levou à decisão?
- Quais implicações?
Adrian começa a apresentação contando sobre os aprendizados do processo de migração do on-premise para a AWS. Uma fala sutil que nos apresenta uma certa dose de conservadorismo no processo de migração.
Ele explica que primeiro queria entender como seria sua relação com o cloud provider, movendo processamento de background, processamento que não afetasse seus usuários, como primeiro movimento desse imenso jogo de xadrez.
Ele logo fala sobre como conduziu o estudo sobre a adoção do Apache Cassandra para banco, e em poucas palavras descreve o macroprocesso de tomada de decisão. Desde entender que poderia ser uma oportunidade, até ter 100% dos dados distribuídos algo entre 10 e 15 clusters Cassandra.
Em menos de 5 minutos de apresentação ele avança citando que cada microsserviço possuía seu próprio cluster Cassandra. Ele não deixa de citar que obviamente tiveram de lidar com a impossibilidade física de realizar joins entre tabelas, afinal, são clusters independentes.
Ele constrói a apresentação falando do início da jornada de Microsserviços na NETFLIX, citando frases e pensamentos comuns do mercado na época.

Adrian relembra que em 2011 quando ocorreu uma queda da AWS, a NETFLIX permaneceu no ar e lembra que não foi ao acaso, o produto foi projetado e arquitetado para a alta disponibilidade.
Mesmo que sutil, podemos concluir com os próximos 10 minutos de vídeo que a estratégia de disponibilidade projetada para o produto extrapolava as fronteiras do Cloud Provider. Vou abordar o assunto no decorrer do texto. Mas o ponto aqui é que eles contavam com a possibilidade de queda/paralisação de um datacenter inteiro.
No início da apresentação ele não deixa claro se adotou uma estratégia multicloud, ou se era geograficamente redundante no mesmo cloud provider, o que temos aqui é uma incrível demonstração de alguns elementos:
- Tamanho, dimensão, grandeza do produto que estava no ar.
- Quais as ambições em relação à disponibilidade, visto que tal feito nunca poderia ser um efeito colateral, nesse caso positivo.
O resultado implica na tolerância, inclusive, à indisponibilidade de um datacenter inteiro.
Mais à frente ele sana nossa dúvida sobre a estratégia.
Ele diz:
A Netflix estava otimizando para a velocidade,
Se você é uma empresa pequena e quer vencer em um mercado, você precisa ser capaz de correr mais rápido do que todos os outros, você precisa desenvolver mais rápido, você precisa aprender as coisas mais rápido e para fazer isso, você elimina o atrito do desenvolvimento de produtos, faz com que as coisas sejam construídas mais rapidamente e faz isso com um ambiente de alta confiança e baixo processo, sem trocas de bastão entre equipes e isso é produzido com uma cultura de liberdade responsável.
…
Isso é uma coisa muito importante, é muito difícil construir. Culturas como esta e é muito difícil manter, mas essa é uma das principais vantagens competitivas da Netflix.
É essa cultura e conversamos bastante sobre cultura na Netflix, e é uma arma competitiva importante que a Netflix usa para competir contra empresas que não têm uma cultura que os deixe ir rápido.
Você também quer tirar todas as coisas que ficam no seu caminho que são chatas e que não são essenciais para o seu negócio, então isso é um trabalho pesado indiferenciado.
Então construir data centers? Outras pessoas podem fazer isso!
É muito difícil quando você está crescendo rápido, quero dizer as empresas interessantes estão crescendo rápido certo se você
…
Durante toda a apresentação ele relata como a Netfix usa a própria arquitetura de microsserviços, somada à capacidade da AWS para realizar tarefas absurdamente insanas, como a subida de centenas de nós, de máquinas para atender demandas específicas.
Lembrando que plataformas de música e vídeo possuem demandas muito grandes de processamento batch. Em especial processos de encoding, que consistem em transformar uma mídia (MP3, MP4, MOV, etc.) em formatos diferentes com taxas de compressão diferentes.
Um ponto que me chama a atenção e acho que você deveria assistir essa apresentação pelo menos uma vez, é que por baixo da estratégia arquitetural, há muito assunto, que ao olhar desatento, pode parecer muito “Ops”, muito “infra”. Seja quando ele cita o CDN que construiu na AWS aqui no Brasil, para servir à América Latina, seja quando ele fala dos clusters Cassandra.
E é a forma como se estrutura um consumo de cloud é uma perspectiva Cloud Native, usando o melhor do Cloud Provider: Serviços gerenciados resultantes de anos de experiência e milhares de clientes com redundância de nível profissional, projetado para a escala. Ele cita que seus testes com Cassandra na nuvem, com carga foram suficientes para concluir sobre sua adoção. E a experimentação é parte fundamental do processo.
O ponto é que a forma como lidamos com os recursos de infraestrutura é completamente diferente da forma como víamos no mundo corporativo.
No ambiente corporativo, um time de Ops lida com esses aspectos, mas em uma visão cloud native, com foco em escala, essa divisão de responsabilidades é diferente. A proximidade do Dev com Ops é monstruosa, para que possamos extrair o máximo do que temos à nossa disposição.
Seja como um simples varnish cache, ou um redis, ou um mongodb, talvez Kong, talvez RabbitMQ. Não importa qual tecnologia, mas a forma como seu trabalho toca esses recursos e o que você precisa conhecer desses recursos muda.
Quando pensamos em cada microsserviço usando uma tecnologia específica, muitas vezes nos pegamos pensando em cada microsserviço usando uma linguagem específica. Mas cada microsserviço pode usar componentes arquiteturais e de infraestrutura diferentes. Um microsserviço precisa de filas, outro não. Um precisa de cache, outro não. Um precisa de um CDN HTTP outro não.
A independência dos microsserviços suportam esse tipo de decisão, suportam esse tipo de detalhe na estratégia.
Alguns microsserviços poderão ser geograficamente replicados, ou seja, serão hospedados perto do cliente, e serviços de DNS globais cuidarão para que cada cliente ao acessar seu serviço, será direcionado para o cluster na região do datacenter mais próximo. Serviços como Akamai, em conjunto com Route 53 da AWS são conhecidas soluções com essas capacidades. Vale olhar para seu cloud provider, provavelmente Azure, e entender como ele oferece esse tipo de abordagem.
Na apresentação Adrian conta que subiram algumas centenas de máquinas aqui nos datacenters da AWS no Brasil, e conta quão difícil seria se tivessem de despachar essas máquinas pra cá. Ele diz que em 1 semana descobriram que subir essas máquinas aqui, não resolveria seu problema de latência de rede, objetivo da investida. E conta como essa relação próxima com a cloud evitou o desgaste e a burocracia, não só para enviar e cuidar dessa infra, mas também de demitir equipe depois de descobrir que a estratégia não resolveria o problema.
Novamente a relação próxima com os serviços de infraestrutura de nuvem é o que torna cloud native tão próximo de microsserviços. Essa relação despretensiosa que soa até arrogante, por certo ponto, de simplesmente alocar o que é preciso, avaliar se aquilo atende e se não, seguir em frente buscando a solução que resolva seu problema é o que faz ser cloud native.
Adrian retoma o exemplo de seus estudos sobre a adoção de Cassandra, e fala sobre seus clusters de testes com: 96 máquinas, 64 GB de RAM cada, 2TB de SSD cada distribuídos em 6 datacenters em 2 regiões: Oregon e Virgínia.
Tomar conhecimento desses detalhes nos permite entender a estratégia de resiliência e tolerância à falhas da Netflix.
Microsserviço não é objetivo em si
Ao falarmos de Microsserviços, precisamos compreender quais forças empurram sua arquitetura para esse desenho. Aqui na apresentação do Adrian, ele mostra quais eram as ambições e desafios que apontaram para essa direção.
Ao fazer o resgate dessa apresentação, conseguimos entender sua origem, e esse slide abaixo nos sinaliza quais eram as ambições da empresa, naquele momento, que viabilizaram essas estratégia e táticas que mais tarde se consolidaram com o termo microsserviço.

Adrian nos conta que a Netflix, naquele momento, tinha o drive para a velocidade. Ou seja, time to market. Mais releases, mais mudanças mais novidades.
Não é difícil encontrar diferenças fundamentais entre startups e o mundo corporativo.
Por exemplo: Nesse slide (acima) o que mais chama a atenção é “High trust, low process, no hand-offs between teams“.
Não é ao acaso, mas é o extremo oposto do que ocorre no mundo corporativo:
| Netflix (Startup) | Enterprise |
|---|---|
| High trust | Low trust |
| Low process | High process |
| no hand-offs between teams | a lot of hand-offs between teams, many times |
Esse tipo de diferença entre o mundo corporativo e o universo das startups é um desafio a ser superado.
Testes como os que apontaram Cassandra como uma solução viável, multicloud, para armazenamento de dados, simplesmente seriam suprimidos na primeira reunião onde o assunto fosse exposto, caso estivéssemos falando de um ambiente corporativo.
A filosofia por trás de Freedom and responsability culture, é essencial para esse tipo de experimentação. E principalmente, para estar disposto a validar ideias, gastando dinheiro no caminho, sem a certeza de sucesso.
No universo corporativo, boa parte das demandas de planejamento, projeto, concepção, elaboração (isso é usado ainda?) são realizados para tentar assegurar previsibilidade. O mundo corporativo tem o drive no custo. Diferente do drive na velocidade, como vemos na apresentação.
Isso muda tudo, inclusive a arquitetura.
E não é possível ultrapassar muitas barreiras se seu projeto é grande demais. Não dá para reduzir a quantidade de reuniões e intercepções entre times em um roadmap, quando se fala de uma aplicação monolítica.

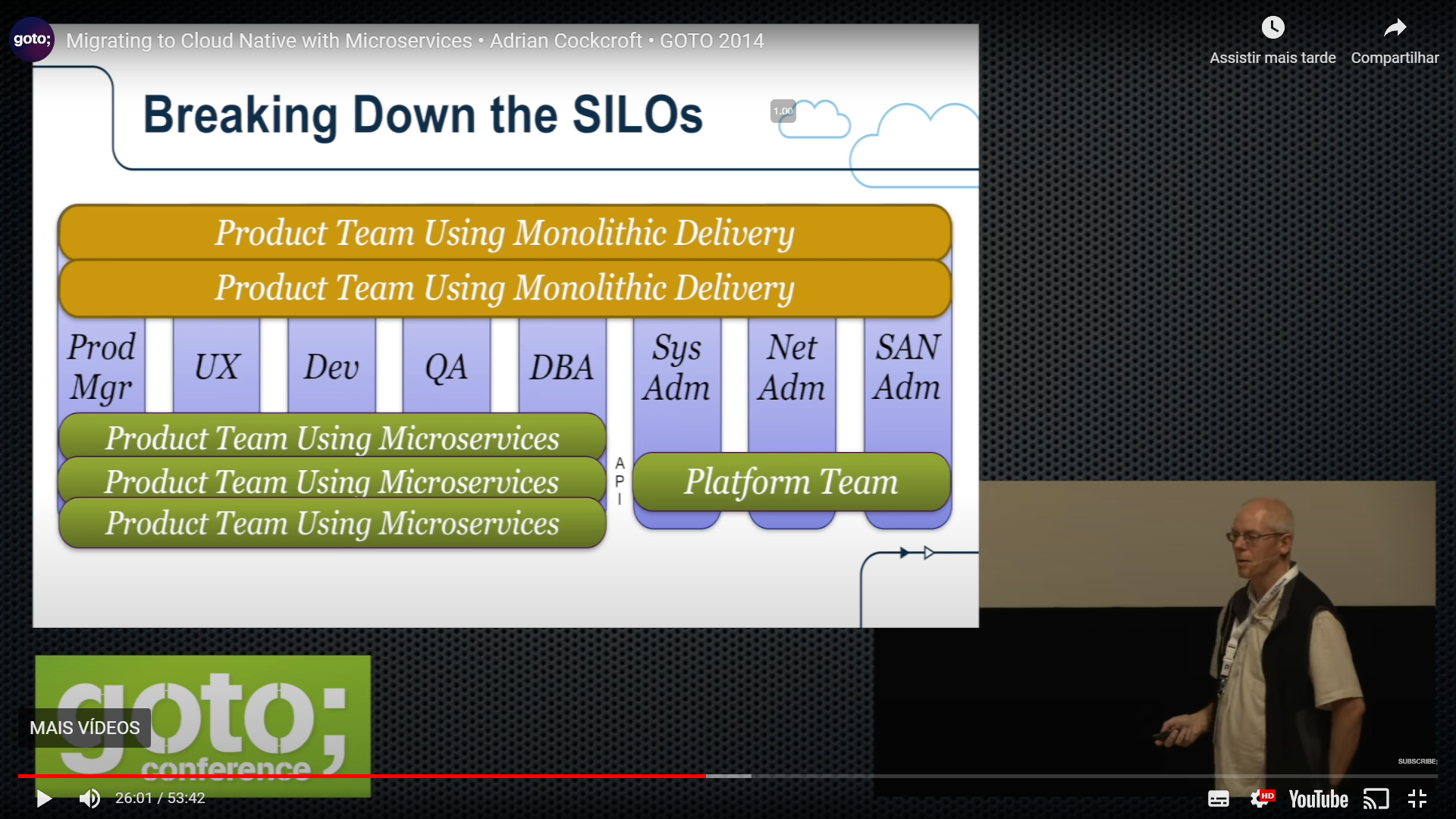
E é aí que entra DevOps (que inclusive é tema do nosso próximo post dessa série) e a forma como os times são dispostos em times multidisciplinares.
Note que a arquitetura é mais um dos elementos que acompanham as intenções de direcionar os esforços para a velocidade.
…
então é como uma mudança de 90 graus no organograma.
Se você está realmente fazendo DevOps corretamente, você faz a combinação e faz esse tipo de virada de 90 graus da sua equipe em seu organograma.
E então tudo fica muito mais fácil de fazer, o problema é um pouco menos eficiente, mas o ponto é que é muito mais rápido e se você for mais rápido você acaba ganhando em outro lugar.
Então como é em um aplicativo monolítico?
Você tem um plano de release, você tem um monte de desenvolvedores, eles estão todos usando a mesma estrutura, linguagem, framework.
Você passa o código deles no controle de qualidade, que trabalham nele por alguns dias para fazê-lo funcionar,
então eles jogam para Ops, que substituem a versão anterior pela nova versão
mas de vez em quando o controle de qualidade encontra um bug que bloqueia toda a versão. Então Ops encontram um bug e isso bloqueia toda a release.
E um bug bloqueia todos os outros desenvolvedores trabalham nesse projeto.
Esse trabalho não dando certo ao ponto de chegar ao cliente, nenhuma atividade está sendo percebida pelo cliente, sendo executado na frente do cliente.
Não entregou valor!Então este problema aqui é ok quando você tem quatro ou cinco desenvolvedores
Mas quando você tem uma centena de desenvolvedores é insano!
Porque um desenvolvedor bloqueia tudo e você não pode realmente dizer onde neste monólito algo quebrou, então você tem que ligar para todos os 100 para dizer quem quebrou.Toda sexta na Netflix haveria um email para todo o time de engenharia web, dizendo:
A release quebrou, todos devem olhar seus códigos para ver se foi o seu.
Isso é uma loucura, temos que fazer algo melhor!
Então isso foi meio que a percepção de que tínhamos que acabar com isso e essa é a razão fundamental pela qual a Netflix fez a transição.
Quando passou de cerca de cem desenvolvedores em um aplicativo monolítico, ficou muito doloroso.
Então mudamos para essa outra maneira de trabalhar.
Hoje temos muitas releases acontecendo independentemente, em momentos diferentes, com gerentes de produto diferentes, e muitos grupos de desenvolvedores diferentes, trabalhando em escalas de tempo totalmente diferentes, atualizando em frequências diferentes, usando linguagens diferentes e você não se importa mais e eles têm API’s entre eles, na medida em que precisam conversar entre si.
E então eles publicam usando um framework padrão,
E eu acabei de colocar o docker aqui porque basicamente não me importo com o que é uma vez que está em um contêiner.
…
Note algumas informações preciosas nessa parte:
O foco em Velocidade fazia com que o modelo monolítico não atendesse.
A adoção para esse desenho diferente de distribuição do time, chega a partir do momento em que se aproximam dos 100 devs.
A quebra da arquitetura em microsserviços acompanha essa revisão no organograma.
Essa revisão do organograma tem uma pegada DevOps muito intensa.
Note que a arquitetura é apenas um reflexo do contexto e do time, exatamente como descrevi em 2014 em Como definir a Arquitetura de um Software.
Novamente, durante a apresentação Adrian conta também que atividades Cross, que envolvem muitos times, são exceções.
E sim, é um desafio.
Mas o novo desenho foi otimizado para o trabalho autônomo de cada microsserviço e sua equipe.
Outra característica interessante é que o process de deployment não substitui os serviços antigos. Novas versões são colocadas lado-a-lado com versões antigas.

Aqui há outro ponto interessante sobre o contexto.
Os deployments em produção produzem diversas versões dos mesmos serviços, lado-a-lado.
Pela natureza difícil de testar a aplicação em televisores e videogames, por exemplo, optaram por usar a própria infraestrutura de produção. Com o auxílio de ferramentas que usam características do request para direcionar tráfego, conseguem rodar não só diversas versões do mesmo serviço, lado-a-lado, mas também conseguem fazer com que apenas testers consigam testar uma versão específica em determinado contexto/cenário.
O efeito colateral positivo, é que um novo código pode ser testado side-by-side com o anterior, isso permite testes da equipe, mas também, testes A/B e exposição de código ao comportamento do usuário, produzindo inteligência de negócio.
Esse é o tipo de requisito exótico, mas faz sentido para o negócio da Netflix.
Agora, ao olharmos para as 9 características dos microsserviços, apresentada por Fowler no mesmo evento de 2014, conseguimos ter uma visão muito mais clara sobre o que se trata.

Conseguimos entender quase que instantaneamente como as demandas do negócio quase que impuseram aquele desenho, quase impuseram essa lista de características.
E isso nos conecta à demanda de negócio, ao problema original em si. E quando fazemos isso, entendemos melhor o que podemos e o que não podemos fazer, pois entendemos que algumas flexibilizações, fariam aquelas premissas não serem cumpridas, fariam não conseguirmos atender algumas daquelas demandas.
Mas também, como subproduto, entendemos que são essas demandas de negócio, é o contexto ao qual estamos inseridos que determinam restrições e limitações que vão influenciar diretamente na arquitetura.
Agora conseguimos conectar o assunto DevOps e vemos como um time multidisciplinar autônomo, tão autônomo quanto uma empresa externa, é capaz de produzir velocidade em atividades que não ultrapassem o escopo do seu microsserviço.
A proximidade desse time com os seus microsserviços, proporciona foco no produto, no entregável e novamente, um desejável para o negócio: velocidade!
Conectando os pontos
Microsserviços estão no coração do Cloud Native porque é um desenho de arquitetura que se beneficia da Cloud de uma forma única, que nenhuma outra abordagem conseguiria se beneficiar tanto. Ao mesmo tempo, todo um universo ao redor do tema cloud native e principalmente ao redor do Kubernetes nasceu para dar suporte a esse tipo de serviços pequenos e fragmentados. Não só como runtime, como orquestração, como redes definida por software, mas recursos de observabilidade e governança.
Kubernetes está no centro dessa discussão, por ser a tecnologia que costura esse universo cloud native, mas esse universo extrapola o Kubernetes.
Por exemplo tenho um Harbor (container registry) trabalhando somente com docker, somos capazes de rodar prometheus, jaeguer e uma dúzia de soluções sem o kubernetes, embora o k8s seja de fato a casa desses serviços.
No próximo post
No próximo post da série vou abordar como Continuous Delivery e cloud native andam tão próximos…









0 comentários