
Arquitetura é estratégia.
Projetar uma arquitetura envolve muito mais do que escolher tecnologias, implica em compreender como os conectar pontos e principalmente como lidar com limitações e restrições.
Em um mundo utópico, sem escassez, não precisaríamos nos preocupar com arquitetura, toda estratégia seria válida, poderíamos escolher absolutamente qualquer estratégia e tudo magicamente funcionaria perfeitamente.
A realidade nos impõem limitações de tempo, time, recursos, criando restrições das quais precisamos lidar.
Nesse post vou falar como projetei uma arquitetura para 140 mil salas de chat, podendo aceitar até 2 bilhões de mensagens por dia.
Nesse ano uma das minhas últimas atividades significativas em um cliente, foi a criação de um chat server. Onde fui responsável da concepção à implementação e implantação desse chat server no Kubernetes.
Mas afinal, o que é um chat server?
Um chat server é o backend de um serviço de chat. É o serviço que permite que clientes se conectem para enviar e receber mensagens.
Embora o envio de mensagens do cliente para o Chat Server até possa ser feito através de um endpoint API HTTP comum, o recebimento de mensagens (Chat Server para Cliente) precisa ser reativo.
A natureza de serviços de chat, exige essa reatividade.
Essa reatividade em geral é provida por tecnologias como mqtt, websocket, grpc streams, elas são as as tecnologias mais indicadas para esse cenário e possuem diversas implementações disponíveis.
Quais são os desafios de um chat server?
Conexões de longa duração
Um chat server precisa estabelecer conexões de longa duração com seus clientes. Isso consome milhares de vezes mais recursos do que API’s HTTP simples.
Ao mesmo tempo o número de conexões simultâneas importa muito nesse caso.
Se tivermos muitas instâncias, e salas fragmentadas, temos de assegurar que somente instâncias que necessitam de um dado recebam esse dado. Todo desperdício de envio de mensagens para instâncias que não tem o que fazer com a mensagem se traduz em tráfego de rede desnecessário.
Reconexão
O usuário pode precisar se reconectar, mas ele não necessariamente chegará no mesmo POD.
Atualizações
Não é possível esperar todos os clientes encerrarem suas conversas para somente então fazer updates. É necessário suportar updates constantes mesmo que tombem conexões, para que possamos atualizar a aplicação gerando zero impacto.
Custos
Por exemplo, podemos atender a milhões de requests em uma Web API com uma única instância no Azure App Services, entretanto só podemos ter 350 conexões WebSocket por instância, com o plano básico.
Assim, para termos 1000 usuários conectados são necessárias 3 instâncias.
Já para atender aos 140 000 usuários do teste, seriam necessárias 400 instâncias.
Considerando o preço de R$ 63,32 por instância do Basic Plan, estamos falando de R$ 25.328,00, caso precisássemos manter essas instâncias por todo o mês. Mas essa limitação de 350 conexões WebSocket é uma questão do basic plan.
Em contrapartida, em planos premium, solicitações simultâneas máximas permitidas por CPU (também conhecido como maxConcurrentRequestsPerCpu):
- 7.500 por VM pequena
- 15.000 por VM média (7.500 x 2 núcleos)
- 75.000 por VM grande (18.750 x 4 núcleos)
Dessa forma, se escolhêssemos o service plan Premium v3 P2mv3 teríamos 4 vCPU e 32GB de RAM em um custo de R$ 1.385,66 por instância. Ou seja, precisaríamos de apenas 2 instâncias, com um custo total de R$ 2.771,32 para atender 140 mil clientes. Muito diferente dos R$ 25k!!!
Já para entregar o arranjo ideal de service plan e escala, dependeríamos de dados reais e da projeção de adoção da solução.
Esses números eu peguei do AppServices para ilustrar a relação de custo. Lembrando que a solução executada foi hospedada em outro serviço/oferta: O Azure Kubernetes Services.
Note: Escala é custo! E não falamos do resto que precisa escalar para acompanhar esse volume de operações simultâneas.
recursos, e pela natureza dessas conexões
Entendendo o Contexto
Vou contextualizar usando dados fictícios de negócio, trocando o ramo de atuação, e os atores de negócio envolvidos. De tal forma a manter a clareza do problema, e ajude a dar luz às decisões sobre a solução, suas restrições, mas sem expor questões próprias do cliente.
Entendendo a demanda
Imagine um edifício no coração de São Paulo, onde uma equipe de usuários altamente especializados controla, de forma remota, telescópios distribuídos ao redor do mundo, todos apontados para as estrelas. Esses profissionais monitoram e ajustam cada instrumento com precisão, capturando imagens e dados astronômicos em tempo real, como se estivessem fisicamente ao lado de cada telescópio, a partir de uma sala de controle centralizada na metrópole.
Eles controlam remotamente cada telescópio através de uma aplicação desktop, um cliente desenvolvido em C++ que se comunica remotamente usando um protocolo proprietário, semelhante ao VNC ou RDP, que transmite comandos, dados e vídeo em realtime. Este sistema permite que o usuário manipule os telescópios com alta precisão, como se estivesse operando-os localmente, apesar da distância física.
No local físico onde os telescópios estão instalados, usuários locais realizam tarefas solicitadas pelos usuários remotos.
A operação dos telescópios se dá em conjunto, onde os 2 precisam realizar ações para que cada tarefa seja realizada. Ambos são parcialmente autônomos, e dependem um do outro para concluir o trabalho. O chat é o canal pelo qual essa comunicação acontece.
App Desktop C++
Embora existisse um cliente web, da versão antiga, uma nova versão desktop estava em desenvolvimento havia sido projetada para assumir o papel de principal cliente, usada nas principais demonstrações e que ganhou prêmios internacionais em inovação.
Claro que o contexto real não são telescópios ok?
A escolha do C++ para esse cliente estava fora do meu escopo de trabalho, e foi conduzida pelo time de especialistas, pela necessidade de lidar com otimização e precisão, permitindo lidar em baixo nível com o streaming bidirecional, de alta qualidade e ultra baixa latência, mesmo em distâncias muito grandes.
A qualidade da transmissão é tão importante quanto aquelas utilizadas em cirurgias remotas, onde o vídeo, e os braços mecânicos são empenhados para, em tempo real, realizar cirurgias, na medicina.
A experiência com SignalR
Chat não era uma novidade na solução, a versão web, antiga, já possuía uma implementação de chat, baseada em SignalR.
Eram comuns os relatos de que nunca havia funcionado bem.
Outro ponto importante é que a empresa tinha um volume razoável de clientes no Brasil, e os deployments eram realizados por cliente.
Ao adotar um deployment por cliente, os problemas com SignalR diminuíram, mas não foram solucionados. Vale ressaltar, se não me falhe a memória, que usavam SignalR sem backplane do Redis, além de estarem sob o .NET Framework.
E parte das dores com o SignalR se dava exatamente pela soma desses fatores.
O Chat
O fluxo de trabalho acontece com o uso intenso do chat, que permite envio de texto, áudio, fotos, etc.
Além dos usuários, o chat também deveria suportar um número não limitado de profissionais em uma sala. Seja por uma necessidade de supervisão, troca de plantão na operação dos telescópios, mas também por ser um microsserviço que atenderia outros contextos de uso que não vou abordar nesse texto.
O que é importante entender aqui é que a maioria das salas teriam menos de 5 usuários, mas algumas poderiam ter milhares.
O time
O time era misto, a versão antiga tinha um time .NET, enquanto a versão nova tinha um novo time multidisciplinar independente.
A versão antiga da aplicação web era hospedada no AppServices, em deployments semi-manuais.
Os skills de estratégia de código e arquitetura eram baixos, mas não nulos. Havia intenção, querer, mas não havia conhecimento necessário para participar da nova versão sem que passassem por alguma capacitação.
Infraestrutura e Recursos
Embora a versão anterior tivesse sido projetada para ser implantada no Azure AppServices, a nova versão do ecossistema inteiro estava sendo projetada para o Kubernetes, e usaríamos o Azure Kubernetes Services para hospedar as API’s e serviços de infraestrutura.
Estávamos saindo da topologia de 1 deployment por cliente para 1 deployment por por país/região, onde cada deployment deveria atender a mais usuários do que todos os deployments do Brasil somados já atendiam.
Financeiro, Política e Relevância
A empresa estava em vias de fechar um novo contrato, dessa vez um contrato de distribuição global. Não me recordo se havia chegado ao breakeven ou chegaria com esse contrato.
A perspectiva para os próximos anos era de implantações em todo o mundo, principalmente em 3 grandes continentes, além do que já existia aqui no Brasil.
O problema
A base de clientes aumentaria drasticamente com esse novo contrato, e adotar a mesma estratégia de deployment por cliente traria um custos elevados para além da conta.
Ao mesmo tempo os problemas de observabilidade na versão anterior eram críticos, e se tornariam vezes maiores com o crescimento.
O segmento lidava com um risco elevado, então qualidade, confiabilidade eram requisitos acima da média, com implicações acima da média.
Não chegava a ser uma cirurgia remota, mas não estava muito distante do assunto, e passava pelos mesmos crivos de FDA e órgãos similares de todo o mundo.
A solução
Do ponto de vista de infraestrutura, começaríamos 3 clusters Kubernetes (AKS) ao redor do mundo coordenados com Azure Fleet Manager. 2 Clusters nos estados unidos, e 1 cluster em algum lugar da Europa, para começar. Novos clusters seriam criados para Ásia e possivelmente mais clusters na Europa.
O projeto tem potencial para em alguns anos ter ao menos 1 cluster por região no globo. Mas isso não é tão relevante para o meu trabalho. O que importava era conseguir lidar com vários clusters.
Nesse cluster teríamos os serviços der infra:
- observabilidade
- mensageira
- cache
Além das aplicações:
- Web App
- Web Api
- Workers
Embora não seja escopo desse projeto, fazer uma versão on-premise da solução não custaria mais do que algumas horas de trabalho.
Kafka ou RabbitMQ?
O projeto foi o pensamento para usar Kafka originalmente, que inclusive sustentei a decisão por semanas, até que demandas internas do projeto por comportamento assíncrono me fizeram pensar em filas.
Aliado ao custo de infra do Azure HDInsights (Kafka gerenciado no Azure) que se mostrou maior do que estávamos dispostos, e até cogitei trazer o Kafka para o cluster Kubernetes, mas elevaria em muito os custos tanto com o cluster, quanto com armazenamento.
A implantação de Kafka, segundo as recomendações, custaria mais que todo o resto da infra.
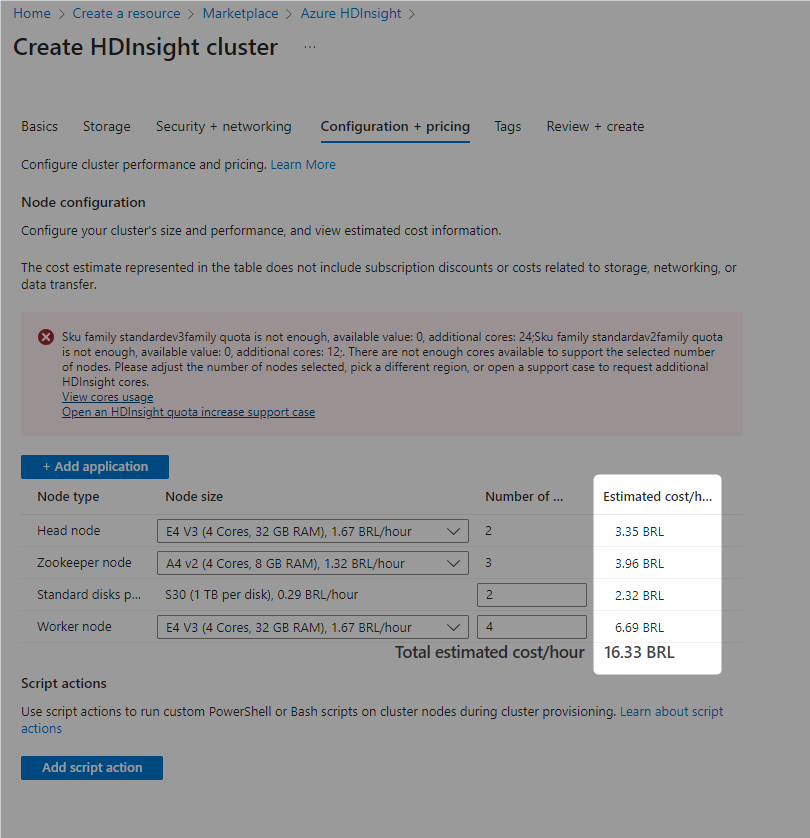

Outra composição de custo, com servidores com 64GB de RAM custariam o dobro.
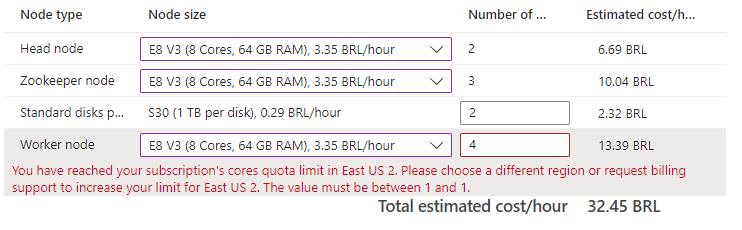

Isso me fez voltar às origens e refazer o desenho com RabbitMQ em cluster dentro do próprio Kubernetes usando RabbitMQ Cluster Operator.
As filas do RabbitMQ me trariam a resiliência que precisava, além do controle e distribuição de tarefas que me ajudava nos casos de uso críticos.
Ao mesmo tempo na medida que as filas são consumidas, temos a liberação imediata de recursos. Isso significa que embora se tenha o custo para hospedar e manter o RabbitMQ, o custo para manter as mensagens sempre tende a zero. Diferente do uso de streams, em que o histórico permanece no cluster, gerando custo para manter desses volumes que crescem ininterruptamente.
Muitas vezes eu tenho a sensação de que vivo sobre a máxima de que:
“Para quem só conhece o o martelo, todo problema é um prego”.
Por isso eu busco racionalizar essas decisões com base em números, mas ao longo desses 16 anos, chego à conclusão de que 80% dos problemas em arquitetura, escala, eficiência, resiliência, performance (problemas em sistemas em geral) se resolvem com:
– melhoria no código (refatoração)
– adoção de observabilidade
– usando cache (redis)
– usando mensageria (rabbitmq)
SignalR ou WebSocket?
SignalR tinha potencial para ser adotado nesse contexto, entretanto as abstrações sob WebSockets traziam um custo do qual não queria pagar nesse projeto.
O cliente C++ para SignalR aspnet/SignalR-Client-Cpp está às moscas, e o uso de redis como pub/sub me levou a crer na possibilidade de um tráfego interno intenso e desnecessário, com muitas mensagens sendo dropadas pela aplicação, por chegarem em todas as instâncias, principalmente instâncias que não teriam para onde enviar essas mensagens.
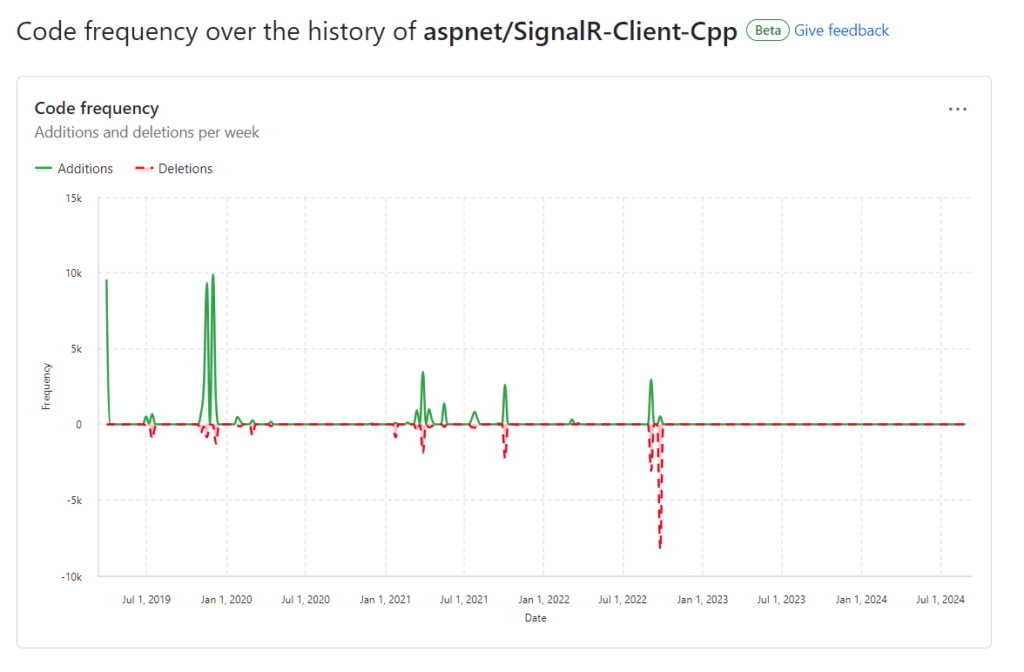
Para esse projeto descartei SignalR, implementar WebSocket puro me pareceu uma ideia mais sensata, embora trouxesse o ônus de ter de construir um backplane.
O uso de WebSocket
Mas como lidar com WebSockets sem um backplane, como o SignalR possui?
O papel do backplane é coordenar diversas instâncias do SignalR, o Redis é empregado para isso. De tal forma que fosse possível escalar a aplicação web, e assim continuaríamos conseguindo promover a comunicação de todos para todos, como se fosse uma coisa só.
Isso permitiria que um Usuário que caísse em uma determinada instância A, conseguisse conversar na mesma sala com um Usuário que caísse na instância B.
A alternativa, seria criar algum tipo de controle de afinidade, que forçasse ambos a caírem na instância da aplicação onde residisse a sala de chat, desde a primeira requisição.
Isso não me pareceu razoável, muito menos saudável, tampouco sensato.
Criando requisitos não funcionais: Evitando afinidade
Fazer com que 2 usuários interessados que precisassem se conectar a uma mesma sala, precisassem também se conectar à mesma instância específica da aplicação, gerava um cenário nocivo para a solução.
Depender de uma única instância para uma sala impõe um limite físico de participantes em uma sala. Embora o número só pudesse ser descoberto com testes, teríamos alguma limitação física óbvia.
Além disso, seria necessário achar um meio de impor alguma afinidade no roteamento HTTP do cluster Kubernetes, de tal forma que o load balancer interno no Kubernetes conseguisse determinar qual instância um usuário deveria se conectar para chegar em determinada sala.
Além desses 2 pontos, um usuário que precise se conectar à 2 salas, precisaria estabelecer 2 conexões WebSocket, uma para cada sala, nos casos em que as salas estivesse em uma instância diferente da aplicação, mesmo que estivesse no mesmo nó do cluster Kubernetes.
Também seria necessário prever que as salas crescessem com o tempo (meses), ou com o crescimento momentâneo de uma sala, ultrapassando o limite de usuários da instância.
E por fim, mas não menos importante, seria preciso pensar em reconectar usuários de uma mesma sala, caso o POD caísse, já que teriam de chegar novamente na mesma instância da aplicação. Caso contrario seríamos obrigados a trabalhar com janelas de manutenção e implantação.
E definitivamente eu não saí da cama para entregar para isso!
A projeção tinha como limite o número mágico de 140 mil salas para o teste de carga que seria realizado, cada sala contendo de 2 a 5 usuários, em outro contexto poucas salas poderiam ter mais de 1000 usuários (sem limite).
Criar afinidade, seria um tiro no pé, aquele tipo de solução que 2 pessoas na empresa entendem e quebra o tempo todo, até ganhar maturidade e ninguém mais mexer. Um belo dia para de funcionar e todo mundo se desespera.
Conceito de Salas virtuais
Estava claro para mim que o comportamento que eu queria:
- permitiria a um usuário que se conectasse à plataforma, poderia se conectar em absolutamente qualquer instância da aplicação
- caso o pod caísse, por um problema/falha ou durante um deployment, deveria ser quase imperceptível para o usuário. Deveria aparecer no máximo um ícone de reconexão, nada mais.
- um usuário para receber mensagens de 2 ou mais salas, precisaria apenas de 1 conexão (não implementado, essa seria a evolução do mecanismo)
Ao definir esses comportamentos, a quantidade de gestão e coisas mirabolantes seria reduzido e simplificado:
- Sem necessidade de criar afinidade
- Sem grandes preocupações com reconexão
O conceito que desenhei para esse projeto foi o de salas virtuais. Cada instância da aplicação pode receber qualquer usuário, interessado em quaisquer salas.
Ao receber uma conexão WebSocket, o server já recebe o id da sala para o qual o usuário quer se conectar. Uma vez autorizado, a aplicação verifica se a sala virtual existe na própria memória do processo. Caso não exista, a sala é criada, e a conexão websocket do cliente do chat é colocada debaixo da sala virtual.
Caso a sala exista, porque ao acaso outro cliente se conectou à mesma sala, e por milagre, caiu no mesmo POD, a segunda conexão WebSocket é pendurada debaixo da sala existente.
O resultado é algo assim:
- Chat
- ChatServer – POD A
- Salas
- Sala1
- Conexões
- WebSocket 1 – Usuário Luiz
- WebSocket 2 – Usuário Carlos
- Conexões
- Sala2
- Conexões
- WebSocket 1 – Usuário Luiz
- Conexões
- Sala1
- Salas
- ChatServer – POD B
- Salas
- Sala2
- Conexões
- WebSocket 3 – Usuário Maria
- Conexões
- Sala2
- Salas
- ChatServer – POD A
- O usuário Luiz está conectado no POD A, nas salas 1 e 2.
- Os usuários Luiz e Maria estão conectados na sala 2, mas em PODS diferente.
A quantidade de salas no POD não tem relevante, mas a quantidade de usuários conectados ao POD, somado às métricas de CPU e Memória, torna fácil determinar se precisamos escalar ou não os POD’s.
Scale Up é fácil, mas Scale down também, visto que não precisamos nos preocupar com qual POD o usuário se conectou, e a troca de conexão de um POD para outro é transparente para o cliente.
Vale lembrar que o chat server
lida apenas com a conversa,
e não com o streaming de vídeo.
Esse desenho permite:
- partirmos de 2 ou 3 PODS para 100
- depois de 100 para novamente 2 ou 3
- fazendo deploy durante o dia, com usuários conectados
- fazendo scaledown e scaleup
- podemos perder nós inteiros no Kubernetes, que mantemos a alta disponibilidade do serviço
sem que haja nenhum gap na comunicação, no máximo reconexões, que duram um piscar de olhos.
Para concluir a solução ficou um ponto pendente: Como as mensagens que são recebidas por um sala em um determinado POD, chegam na mesma sala, nos demais POD’s que possuem a mesma sala? Cadê o backplane?
Como coordenar o envio das mensagens para salas distribuídas em várias instâncias?
Quando o POD do chat server é criado uma única conexão com o RabbitMQ é estabelecida, e uma fila anônima, exclusiva, e temporária é criada.
Essa fila tem a função de entregar mensagens para o POD.
Assim cada POD tem sua própria fila temporária, isso quer dizer que:
- POD nasce, fila nasce.
- POD morre, fila morre.
Uma exchange do tipo TOPIC, que é destinada ao recebimento e distribuição das mensagens, é criada manualmente já na primeira implantação do projeto. Ao mesmo tempo, uma fila persistente e durável é criada com bind e routing key específica, par que todas as mensagens sejam persistidas, independente da origem e da sala.
A persistência existe para que o usuário que não estiver conectado possa receber posteriormente as mensagens que trafegaram na sala enquanto ele esteve offline, ou caso reconecte a partir de um novo desktop, ou mesmo caso fechar e reabra a aplicação.
O consumidor da fila de persistência tem o papel de escrever as mensagens no MongoDB.
Dessa forma, a exchange recebe cada mensagem enviada por cada usuário, roteia todas para a fila de persistência, enquanto lida de forma otimizada replicando a mensagem apenas para os PODS interessados naquela determinada SALA.
Isso é possível pois quando uma sala virtual é criada em qualquer instância da aplicação, a implementação da sala cria o bind entre a exchange que recebe mensagens e a fila do POD.
A routing-key é o ID da sala.
Caso o POD morra, a fila da sala morre junto, mesmo que tenha mensagens. Esse é o comportamento desejado pela solução.
Ao reconectar, o cliente informa qual sua última mensagem recebida da sala. A partir daí, o serviço do chat pega as mensagens antigas e envia para o cliente via WebSocket. Enquanto as novas seguem o fluxo WebSocket -> ChatServer -> RabbitMQ -> ChatServer -> WebSocket.
Nesse desenho, as filas dos POD’s permitem que o POD só recebe estritamente as mensagens que tem para quem encaminhar.
Essas filas só fazem sentido para o fluxo ao-vivo, online e reativo de troca de mensagens.
O nascimento e morte das filas anônimas, não afetam resiliência. Se o POD morreu, não tem conexão WebSocket para receber a mensagem. Ao se reconectar, o cliente informará qual sua última mensagem e o fluxo volta a funcionar normalmente obtendo mensagens antigas.
E como chegar a 2 bilhões de projeção?
Para produzir essas projeções é preciso pensar em cenários de pico. Aqui estou projetando que 50% desse worklolad ocorra durante 4h horas, enquanto 30% está diluído em mais 6 horas e 20% está diluído em 14 horas, completando as 24 horas de um dia.
Imagine que 50% desse tráfego ocorra durante 4 horas, isso produz:
- 1 bilhão de mensagens em 4 horas
- 250 milhões de mensagens por hora
- 4 milhões de mensagens por minuto
- 70 mil mensagens por segundo
Imagine que 30% desse tráfego ocorra durante 6 horas, isso produz:
- 600 mil mensagens em 6 horas
- 100 milhões de mensagens por hora
- 1 milhão de mensagens por minuto
- 30 mil mensagens por segundo
Imagine que 20% desse tráfego ocorra durante 14 horas restantes, isso produz:
- 400 mil mensagens em 14 horas
- 28 milhões de mensagens por hora
- 480 mil mensagens por minuto
- 7 mil mensagens por segundo

A escolha desses ranges não foi aleatório, optei por uma conta conservadora.
2 bilhões em 24 horas, distribuídos de forma igualitária, produziria aproximadamente ~23k mensagens por segundo. 23k msg/s é um workload já experienciado diversas vezes em ambiente de desenvolvimento, não seria um desafio. Também não seria nem justo, muito menos realista, a realidade é sempre mais agressiva.
Portanto arbitrei de uma forma mais racional, embora fictícia, obviamente.
- Separei 4 horas para ser o período crítico, momento de alto consumo, responsável por 50% da demanda diária, ou seja 1 bilhão de mensagens.
- Reservei mais 6 horas para atender 30% da demanda.
- Restando 14 horas, e 20% da demanda, representando um momento menos intenso, como horários da noite, etc.
Note que a intenção de criar um pico de demanda é extrapolar limites, criar problemas e contenções. Atender 23k msg/s não é uma dificuldade enorme, é relativamente simples de serem atendidas, e isso é um problema, porque gera a falsa sensação de que seria fácil cumprir a missão.
Ao passo que com esse balanceamento (50%-4h, 30%-6h, 20%-14h), mesmo que hipotético, criamos um pico de 70k msg/s por 4 horas, isso representa 3 vezes mais tráfego, do que na distribuição igualitária.
Com essa estratégia, chegamos a 70k msg/s por 4 horas, o que é de fato um número expressivo. Entretanto do ponto de vista da solução, atender 30k msg/s é uma tarefa já realizada pelo desktop de desenvolvimento, para chegar a 100k bastaria poucas configurações de escala vertical.
E claro, a persistência e latência seria um desafio nesse volume de tráfego.
Mas por um acaso do destino, por LGPD/GDPR, a regra de descarte das mensagens é de no máximo 48h, o que me asseguraria que meu banco nunca teria mais do que 4 bilhões de mensagens.
Mas e esses números falsos?
Não há mágica, se eu não tenho um tráfego real, para medir, eu tenho de criar suposições e imaginar cenários, mesmo que eles se mostrem muito distantes da realidade.
Projetar para o stress ajuda a entender até onde sua solução vai, e quanto ela suporta, com que custo ela suporta o que suporta.
A escolha do banco de dados tende a afetar absurdamente esse throughput, mas somente explorando com testes, podemos validar esses números e fazer acertos para alcançar nossos objetivos.
Seria ótimo ter um passado para poder medir, entretanto, partindo do zero, é necessário ter um norte, ter um número-base e correr atrás dele.
No nosso caso, esse número foi absurdamente grande, expressivo.
Se a realidade mostrar que só conseguimos metade, ou 1/4 do estipulado, nos cabe olhar para o número e pensar se precisamos ou não chegar no estipulado originalmente ou só atualizar as documentações com os limites reais.
Não tem mágica, não tem adivinhação, muito menos exoterismo:
- Só podemos medir o passado
- As projeções são metas, mas é o passado que nos diz até quanto aguentamos.
- Medir é fundamental.
O que não está na superfície dessa solução?
Essa solução é 100% Cloud Agnóstic: Funciona perfeitamente em qualquer cloud (AWS, Azure ou GCP),também funciona on-premise, da mesma forma que em Cloud ou em colocation ou VPS.
Conclusão
Esse desenho arquitetural é um exemplo claro de como a inovação e a adaptação às circunstâncias são fundamentais no desenvolvimento de soluções robustas e escaláveis. Ao optar por WebSocket puro e uma arquitetura de salas virtuais, foi possível evitar complexidades desnecessárias, como a afinidade e a gestão excessiva de reconexões, simplificando a operação e manutenção do sistema. A decisão de utilizar RabbitMQ mostrou-se acertada ao balancear a necessidade de resiliência com os custos operacionais, mantendo a escalabilidade e flexibilidade necessárias para suportar um crescimento global.
Essa solução permite uma escalabilidade fluida, seja para atender um número crescente de usuários ou para se adaptar a picos de demanda temporários, sempre garantindo a continuidade do serviço com o mínimo de impacto para o usuário final. A abordagem de filas temporárias para o envio de mensagens entre PODs garante que o sistema continue operando de forma eficiente, mesmo em cenários de falhas ou durante atualizações de infraestrutura.
No fim, o sucesso desse projeto não reside apenas nas escolhas tecnológicas, mas na capacidade de entender profundamente o contexto, as limitações e os requisitos do negócio, traduzindo esses elementos em uma solução que não só atende às necessidades atuais, mas que está preparada para evoluir junto com as demandas futuras. É uma lembrança poderosa de que a arquitetura de software, quando bem projetada, é uma ferramenta estratégica que impulsiona o crescimento e a inovação, ao mesmo tempo em que mitiga riscos e custos.
Update 2024-09-14
Fizemos uma live sobre o assunto lá no canal .NET no dia 4 de Setembro, confere lá!









Caramba cara que massa, realmente o conhecimento sólido em arquitetura e fundamental, ainda mais para cenários desse tipo com alta disponibilidade e uma sincronização de conexões em vários pods.
Espero um dia chegar nesta maturidade de não apenas saber desenhar a arquitetura mas também ter a capacidade e conhecimento de colocar ar a mão no código e desenvolver a solução.
Parabéns.