
Se você está vendo cache distribuído pela primeira vez, talvez tenha deduzido qual é a forma adequada de trabalhar com ele. A pergunta que fica é: Você levou em conta a concorrência?.
A questão é que quando o cache expira, devemos usar o recurso “lento” para produzir o dado que será cacheado. Mas se estamos falando de aplicações distribuídas, o que impede de 100 usuários de chegarem a uma página que não possui cache no mesmo instante?
O que acontece se essas 100 navegações demandarem o acesso ao recurso “lento” para pegar os mesmos dados, fazendo as mesmas queries para obter o mesmo objeto centenas de vezes?
Não é só eficiência
Claro que olhando para esse problema, vemos que a eficiência passou longe. Mas em e-commerces e projetos com um alto volume de acessos isso pode ser um caos, pois além de ser ineficiente, poderia tombar seu banco.
A resolução não é tão simples assim
Se você pensou que a resolução desse problema é usar Lock, sim, você está certo. Mas não é tudo.
Se você não prestar atenção à condição de concorrência, poderá achar que está resolvendo o problema mas na verdade está apenas reduzindo as probabilidades de que ele ocorra. Sem de fato resolver de uma vez por todas.
O fluxo certo parece o errado
O fluxo correto, leva em conta 2 consultas ao cache, no nosso caso o Redis. Isso se dá porque antes do lock você não faz ideia se uma outra instância já realizou o lock e está incumbida de percorrer todo o fluxo e no final alimentar o cache.
Se ao obter o lock você não refizer a operação, pode sim processar novamente o que já foi processado. E isso pode ocorrer com centenas de threads, bastando para isso ter um volume elevado de tráfego no exato momento errado.
Tem coisas boas aqui!
A parte boa é que você está no caminho da solução, só faltou um detalhe: lembrar que o lock é um semáforo e que existem outras instâncias que simultaneamente tentarão fazer a mesma coisa.
O fluxo
abaixo a gente tem o fluxo completo, simulando a obtenção dos dados de pedido.
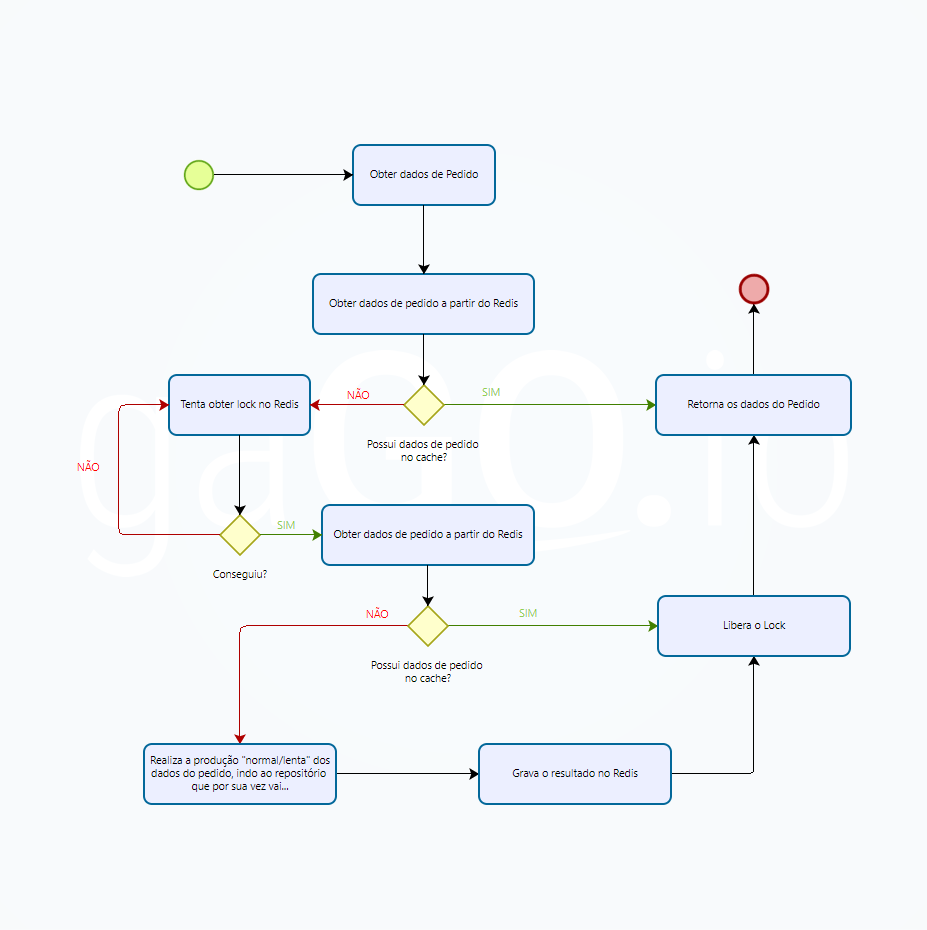
Algumas informações interessantes e explicações:
- A leitura do dado do cache não depende do lock
- O lock só é realizado quando o cache está vazio
- O lock garante que haja somente 1 vencedor (ou owner do lock), e todas as demais instâncias aguardarão a liberação do lock, que acontece ao concluir a tarefa.
- Só 1 instância/thread fará a operação (o owner do lock).
- Se 2 instâncias concorrem, o lock faz as demais aguardarem. Quando o lock for liberado, uma segunda instância será a nova vencedora, será owner do lock. Nesse momento essa instância precisa perguntar novamente ao cache se existe o dado nele ou não. Caso sim, o fluxo é interrompido e o objeto é retornado sem processar novamente a mesma tarefa. Caso contrario, ou seja, o cache continua vazio, então é hora de processar.
Dessa forma você evita que requisições simultâneas que encontraram o cache vazio por algum motivo, produzam uma enxurrada de operações duplicadas.
Se você tem 100 páginas e recebe 1 request em cada uma delas, você de fato tem 100 páginas para processar e entregar.
Mas se você tem 100 páginas, e recebeu 10’000 requests, não faz sentido processar completamente (sem cache) todos os 10’000. Isso é oneroso, ineficiente, e até vergonhoso. Coisas assim fazem com que o consumo de infraestrutura seja muito maior.
Como seria uma versão em pseudo-c#?
public decimal GetPrice(int productId)
{
string priceKey = $"cache:product:{productId}:price";
decimal? returnValue = this.Redis.Get<decimal>(priceKey);
if(returnValue == null)
{
string priceLockKey = $"{priceKey}:lock";
bool locked = false;
using (var lock = this.Redis.Lock(key: priceLockKey, timeout: TimeSpan.FromSeconds(2), retry: 3))
{
//AQUI EU COMENTARIA ALGO COMO:
//NÃO ALTERE, NÃO OTIMIZE, ESSA CHAMADA É INTENCIONALEMNTE REDUNDANTE
//SE VOCÊ CONSIDERA REMOVÊ-LA, LEIA SOBRE "Double-checked locking"
// https://en.wikipedia.org/wiki/Double-checked_locking
returnValue = this.Redis.Get<decimal>(priceKey);
if(returnValue == null)
{
returnValue = this.Repository.GetPriceByProduct(productId);
this.Redis.Set<decimal>(returnValue);
}
}
}
return returnValue;
}
Essa é a versão verbosa do fluxo,
desenhada para a melhor didática e compreensão.
Em ambientes reais esse fluxo é quase que totalmente abstraído e simplificado.
Esse é um pseudo-código, a API do Redis não é assim, a API de Lock não é tão simples, mas é possível expressar as intenções aqui. A segunda validação ocorre porque enquanto quando você produz o lock, podem 2, 3, 10, 1000 serviços tentarem produzir o mesmo lock.
Isso é comum com alta concorrência sobre o mesmo dado. O ponto é que quando o primeiro vencedor do lock estiver reprocessado as linhas 19 e 20 e saindo da linha 22, um outra instância ganhará o lock. Se esse novo ganhador não perguntar novamente se o ainda é necessário realizar o processamento (linha 16), esse vencedor executará novamente as linhas 19 a 20. É função de quem implementa o lock, lidar com isso. Na linha 16 de um segundo vencedor do lock, a chamada ao cache retornará dados, fazendo com que as linhas 19 e 20 não sejam executadas.
Conclusão
Inúmeras são as práticas dedicadas à redução da carga de trabalho sob o banco de dados. Táticas assim permitem otimizar o consumo de infraestrutura, que deveria ser o default. No entanto esse é um tipo de conhecimento que caminha distante da maioria, principalmente dos mais jovens.
Banco de Dados é o tipo de componente que escala diferente, é mais complexo, custa mais caro.
Fazer um uso eficiente desse recurso pode significar atender algumas vezes mais clientes.
PS:
Pensar em processamento assíncrono, paralelo e concorrente é um grande desafio de desenvolvedores Plenos e Seniors. É normal dar um nó na cabeça, é aqui que sua capacidade de abstração a trazer diferencial competitivo.
Update 08/10/2022
Se você quer ver isso na prática, veja o exemplo no DotnetFiddle.
É possível simular esse comportamento com .NET puro. Lembre-se que quando falamos de Redis estamos falando de cache distribuído. E é útil quando nossos serviços rodam distribuídos em diversos processos, potencialmente em diversos servidores também.
Mesmo com um contexto tão diferente, ainda assim o exemplo abaixo consegue ilustrar e demonstrar de forma clara qual é o problema.
Teste como está, veja o resultado.
Da forma original, simultaneamente temos muitas operações acontecendo ao mesmo tempo, ofendendo nosso banco de dados para obter o preço do mesmo produto.
Ao descomentar a linha 52, habilitamos o lock, isso não é o suficiente. Somente descomentando também a linha 54 conseguimos fazer com que essas threads reaproveitem o cache de forma eficiente fazendo com que somente 1 operação seja realizada em vez de 30.
Detalhes pequenos mas que fazem toda diferença.









Muito claro o conteúdo teórico do assusto, mas para ficar mais claro ainda teria algum exemplo de codigo em seu repositório? Muito obrigado
Originalmente não era a intenção ter código para evitar copy and paste burro, em que as pessoas copiam sem entender o que estão fazendo.
Double-checked locking pattern é um exemplo claro de que se você não entende concorrência, você simplesmente removerá a segunda checkagem por considerar redundante, o que é uma imbecilidade causada pela falta de compressão do padrão e até de concorrência em si.
Assim eu achei mais importante fazer esse post para quem quer entender a ideia.
A implementação você encontra em qualquer post sobre Double-checked locking pattern, inclusive na wikipedia.