
Recém lançado em agosto, Kubernetes 1.25 trouxe desafios para o longhorn. Há pouco mais de 10 dias foi liberada na master do projeto a versão que permite usá-lo no Kubernetes 1.25. Mas afinal, o que é Longhorn?
Se você usa AKS, EKS, GKE, ou Microk8s e instalações das mais variadas de Kubernetes, já deve ter se perguntado como persistir arquivos de forma realmente eficiente no Kubernetes.
Block Storage é a tecnologia que controla o armazenamento de dados e os dispositivos de armazenamento. Ele pega todos os dados, como um arquivo ou entrada de banco de dados, e os divide em blocos de tamanhos iguais. Em seguida, o sistema de block storage armazena o bloco de dados no armazenamento físico subjacente de uma maneira otimizada para acelerar o acesso e a recuperação. Os desenvolvedores preferem o block storage para aplicações que exigem acesso eficiente, rápido e confiável aos dados. Pense no block storage como um canal mais direto para os dados. Por outro lado, o armazenamento de arquivos tem uma camada extra que consiste em um sistema de arquivos (NFS, SMB) para processar antes de acessar os dados.
Na prática o Longhorn implementa API’s do Kubernetes para que ele possa hospedar e gerenciar volumes no Kubernetes.
No Kubernetes temos Storage Classes que determinam implementações de storage. Assim diversas soluções podem ser instaladas no mesmo cluster.
Longhorn traz consigo uma storage class chamada longhorn.
Uma vez que exista ao menos storageclass no cluster, você pode solicitar volumes na criação dos seus recursos, via persitent volume claim, que demandará a criação deses volumes.
Isso é feito usando o storageclass padrão ou o storageclass do provider que escolher (e estiver previamente instalado no cluster). O provider cuidará com a criação e disponibilização do volume, que será entregue para o Kubernetes e posteriormente para o POD.
Essa mecânica, um tanto quanto burocrática, é necessária, pois uma das possibilidades é que seu próprio cloud provider tenha um storageclass instalado no seu cluster kubernetes, e muitas vezes precisa de minutos para provisionar discos para sua aplicação. Esse fluxo embora pareça burocrático, é inteligente e permite coisas absurdamente complexas e automágicas.

Com LongHorn você consegue configurar backup automático, consegue definir quantidade de replicas de seu volume. Tudo isso gera uma facilidade e uma praticidade sem igual, já que você tem redundância e alta disponibilidade dos seus volumes no próprio cluster.
Configurações e mais configurações!
Abaixo vou deixar alguns prints do dashboard e das configurações.
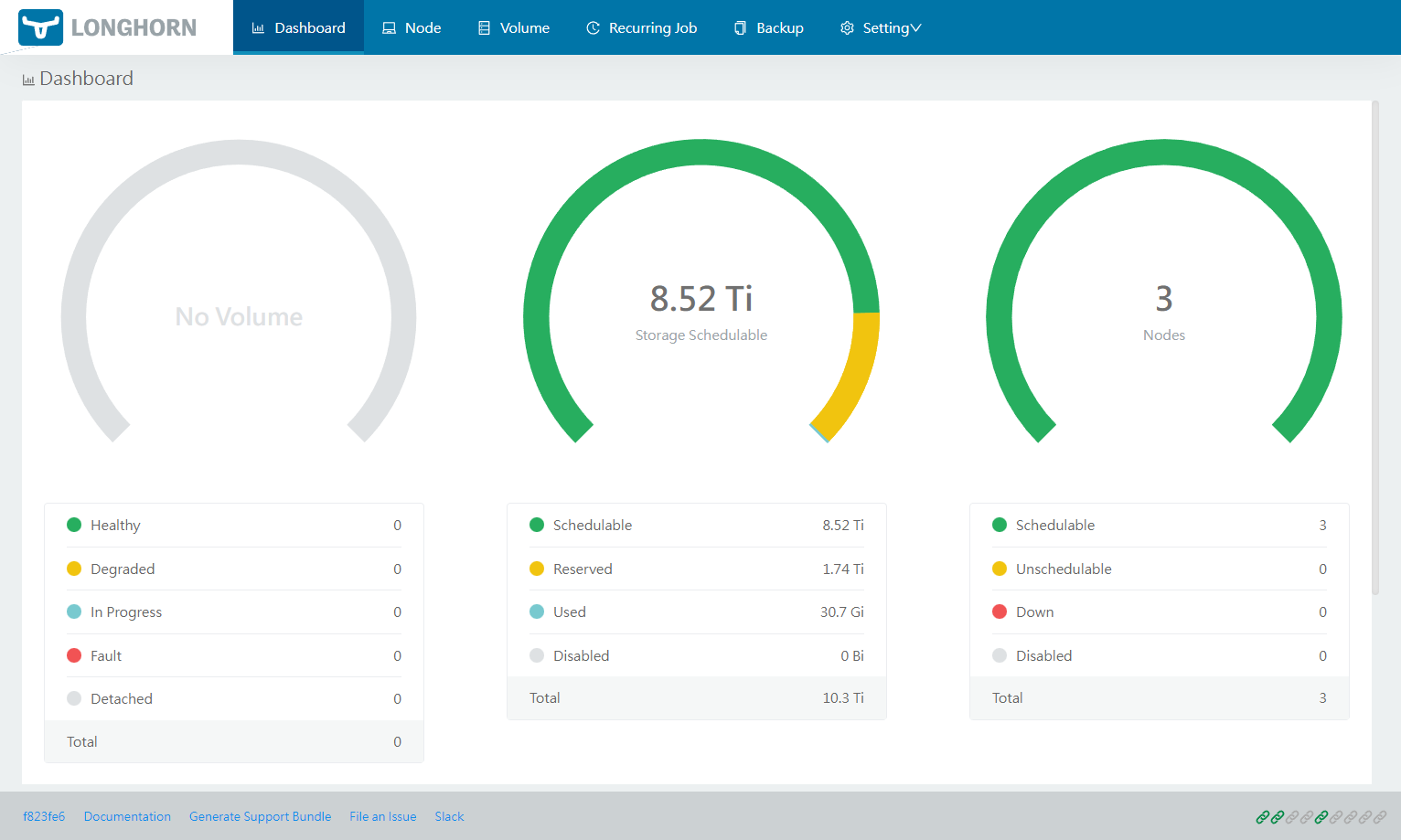
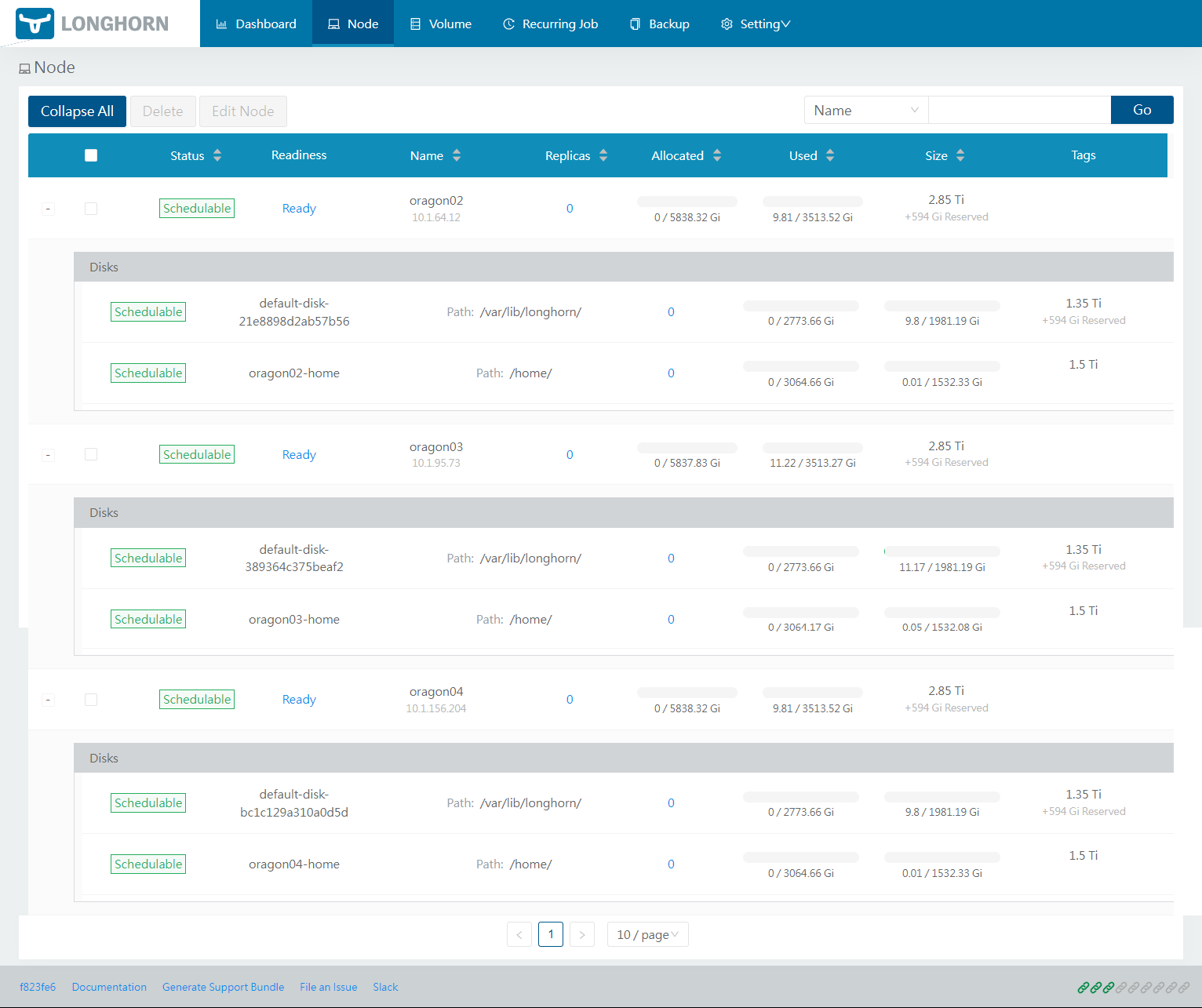

A versão 1.25 do Kubernetes
Na versão 1.25 do Kubernetes que foi lançado em agosto e chegou ao setup do Microk8s em setembro, descobri que o Longhorn não era compatível com a versão mais recente do Kubernetes e isso gerou a necessidade de manter meus setups em K8S 1.24.
Agora, 45 dias depois temos novidades na branch master do projeto, onde já conseguimos enxergar a versão compatível com o kubernetes 1.25.
A documentação e os procedimentos de instalação e atualização estão todos na documentação, disponível em https://longhorn.io/docs/1.3.2/, já a issue que aborda o assunto é a #4003 e a resposta mais motivadora é essa aqui .
Bom, por aqui nosso servidor está ok, com a versão nova da configuração. Ainda aguardo a tag correta e provavelmente a versão 1.4 ou 1.3.3
Aqui nosso setup do LongHorn no microk8s é o seguinte:
kubectl apply -f "https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml" kubectl set env --namespace longhorn-system deployment/longhorn-driver-deployer KUBELET_ROOT_DIR=/var/snap/microk8s/common/var/lib/kubelet kubectl -n longhorn-system wait --timeout=5m --for=condition=Available deployments longhorn-ui
Detalhe: No Microk8s é necessário informar o path do kubelet, e essa é a forma adequada.





0 comentários