
No post anterior eu mostrei como as coisas acontecem na interface de gerenciamento do RabbitMQ. Agora é hora de mostrar as principais iterações com o RabbitMQ via código.
Naturalmente, privilegiarei C# aqui, mas você pode usar as principais tecnologias para realizar as tarefas a seguir. O objetivo desse post é lhe ambientar, já que estamos tentando falar em alto nível, se você nunca viu RabbitMQ então irá te ajudar a entender como as coisas funcionam.
Pacote Nuget
Todas as dependências do RabbitMQ são carregadas a partir desse pacote: https://www.nuget.org/packages/RabbitMQ.Client
Enviando uma mensagem para uma fila
Criar uma fila manualmente pela interface ou criar dinamicamente via código faz parte da estratégia que você vai definir. Não há limitação em nenhum dos dos lados, você precisa fazer escolhas que melhor se adequam ao seu perfil de uso.
É muito importante ficar claro que haverá cenário em que você criará filas temporárias, criadas dinamicamente via código. É o fundamento do fluxo de RPC sobre filas, por exemplo.
Fila previamente criada
Nesse exemplo, tirado da documentação, temos a publicação de uma mensagem usando a exchange direct, enviando a mensagem para a fila hello.
using System;
using RabbitMQ.Client;
using System.Text;
class Send
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
string message = "Hello World!";
var body = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchange: "",
routingKey: "hello",
basicProperties: null,
body: body);
}
}
}
OBS:
- Nesse exemplo, não usamos basicProperties
- Assim não definimos se a mensagem será transiente ou durável.
- Como consequência esse é um exemplo funcional, porém não resiliente.
Nova fila
Já nesse caso, temos a criação da fila antes do envio.
using System;
using RabbitMQ.Client;
using System.Text;
class Send
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.QueueDeclare(queue: "hello",
durable: false,
exclusive: false,
autoDelete: false,
arguments: null);
string message = "Hello World!";
var body = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchange: "",
routingKey: "hello",
basicProperties: null,
body: body);
}
}
}
- Nesse exemplo, não usamos filas duráveis
- Assim as filas são perdidas durante o restart do servidor.
- Como consequência esse é um exemplo funcional, porém não resiliente.
Consumindo mensagens de uma fila
Agora temos um exemplo COM AUTOACK. É o exemplo que encontramos na documentação. Você sabe que não usará AutoAck nunca né?! De qualquer forma deixei aqui para poder falar nisso.
using RabbitMQ.Client;
using RabbitMQ.Client.Events;
using System;
using System.Text;
class Receive
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body;
var message = Encoding.UTF8.GetString(body);
};
channel.BasicConsume(queue: "hello",
autoAck: true,
consumer: consumer);
Console.ReadLine();
}
}
}
- Nesse exemplo, estou demonstrando com autoack
- Assim as mensagens possuem processamento confirmado, antes de efetivamente terem sido processadas.
- Como consequência esse é um exemplo funcional, porém não resiliente.
Note que é o consumo do Evento Receive que efetivamente é encarregado por processar a mensagem que veio de uma fila.
Outro ponto de atenção é que o código está desempacotando o body da mensagem. Isso quer dizer que não há automação nesse processo. Se você serializar um objeto em json, terá de deserializar. Não é responsabilidade do RabbitMQ fazer isso por você, mas os envelopes de mensagem (essa message que você recebe, é um envelope) possuem cabeçalhos e são bons para expressar.
Sobre o acknowledgment
Já no segundo tutorial temos:
Message acknowledgment
Doing a task can take a few seconds. You may wonder what happens if one of the consumers starts a long task and dies with it only partly done. With our current code, once RabbitMQ delivers a message to the customer it immediately marks it for deletion. In this case, if you kill a worker we will lose the message it was just processing. We’ll also lose all the messages that were dispatched to this particular worker but were not yet handled.
But we don’t want to lose any tasks. If a worker dies, we’d like the task to be delivered to another worker.
In order to make sure a message is never lost, RabbitMQ supports message acknowledgments. An ack(nowledgement) is sent back by the consumer to tell RabbitMQ that a particular message has been received, processed and that RabbitMQ is free to delete it.
If a consumer dies (its channel is closed, connection is closed, or TCP connection is lost) without sending an ack, RabbitMQ will understand that a message wasn’t processed fully and will re-queue it. If there are other consumers online at the same time, it will then quickly redeliver it to another consumer. That way you can be sure that no message is lost, even if the workers occasionally die.
There aren’t any message timeouts; RabbitMQ will redeliver the message when the consumer dies. It’s fine even if processing a message takes a very, very long time.
Manual message acknowledgments are turned on by default. In previous examples we explicitly turned them off by setting the autoAck (“automatic acknowledgement mode”) parameter to true. It’s time to remove this flag and manually send a proper acknowledgment from the worker, once we’re done with a task.
Tradução + TL;DR;
Se usar autoack vai se lascar todo!
Brincadeiras à parte, autoack pode te custar muito caro, e o problema é que quem faz autoack faz antes da mensagem ser processada. Isso quer dizer que quem o fará, não sabe se a mensagem foi processada ou não. Funciona como uma confirmação de entrega sem confirmação de recebimento. Enfim, lhe permite construir uma solida arquitetura distribuída sob um castelo de areia.
using RabbitMQ.Client;
using RabbitMQ.Client.Events;
using System;
using System.Text;
class Receive
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body;
var message = Encoding.UTF8.GetString(body);
channel.BasicAck(deliveryTag: ea.DeliveryTag, multiple: false);
};
channel.BasicConsume(queue: "hello",
autoAck: false,
consumer: consumer);
Console.ReadLine();
}
}
}
- Nesse exemplo, estou demonstrando ack manual
- Assim a mensagem só é excluída no RabbitMQ após de ter sido totalmente processada.
- Como consequência esse CONSUMO é FUNCIONAL e RESILIENTE.
- Nesse exemplo não vemos a criação da fila, portanto não conseguimos determinar se esse fluxo inteiro é 100% resiliente ou não.
- É que é possível afirmar que há tolerância a falhas na aplicação.
- Ainda assim não é possível determinar se há tolerância a restarts do RabbitMQ por não conhecermos os parâmetros da fila.
Acima temos o mesmo exemplo, com acknowledgment.
Abaixo temos a comparação entre as duas estratégias:
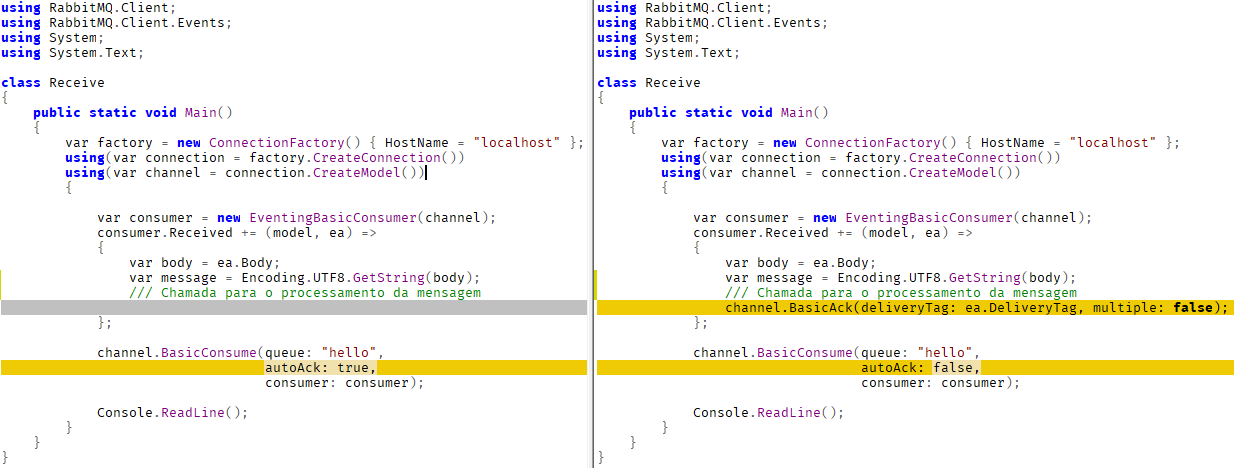
A diferença é extremamente simples, se traduz em uma chamada a mais no código no entanto não tê-la é sinônimo de caos à vista.
Por fim temos a criação de um binding, que liga uma fila a uma exchange. Olhe o exemplo 3 do tutorial do RabbitMQ:
using System;
using RabbitMQ.Client;
using RabbitMQ.Client.Events;
using System.Text;
class ReceiveLogs
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.ExchangeDeclare(exchange: "logs", type: "fanout");
var queueName = channel.QueueDeclare().QueueName;
channel.QueueBind(queue: queueName,
exchange: "logs",
routingKey: "");
Console.WriteLine(" [*] Waiting for logs.");
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body;
var message = Encoding.UTF8.GetString(body);
Console.WriteLine(" [x] {0}", message);
};
channel.BasicConsume(queue: queueName,
autoAck: true,
consumer: consumer);
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
}
}
}
No texto, em inglês, você encontra toda a narrativa que conta como e para que ele está criando a fila dinamicamente. Como nós já falamos sobre isso, fico aqui apenas com o código. Mas vou pontuar algumas linhas que considero relevantes para a explicação.
Linha 14: A exchange é criada. Note que é do tipo fanout (saiba mais).
Linha 16: O código está criando uma fila anônima. O RabbitMQ criará uma fila e entregará o nome como resposta.
Linha 17: Com o nome da fila, é criado um bind para a exchange (essa sim criada previamente).
Aviso
Por hora vou atender a outros projetos pessoais, portanto retomo a série após o carnaval.






Olá Luiz, sou iniciante, li seu artigo, entendi um pouco, mais estou com dúvida. Estou usando no meu projeto, um servidor ubuntu server, nginx como proxy reverso, .net core 2 linux, identityserver4 com postgresql para identidade do usuário..
Eu tenho algumas dúvidas: Para construção de notificação de status do site e um aplicativo de chat privado .net core 2, é recomendável utilizar o Rabbitmq ou Redis? qual é melhor opção? Se for usar Rabbitmq, o envio teria que ser por direct? Qual seria a melhor forma de separar as mensagens privadas dos usuários que possuem guid e dos usuários anônimos dentro do Rabbitmq? teria que criar uma fila para cada usuário? me de um exemplo por favor?
Redis é um Cache, (
até hoje não entendo como forçaram a barra para chamá-lo de NoSQL, mas tudo bem). Ele tem um pub/sub, que nunca usei, dificilmente usaria e não me vejo recomendando.É simples: A maioria das implantações de Redis, sequer trabalha com persistência, isso quer dizer que se um servidor morre, seus dados morrem junto.
E quando você habilita persistência, tem outro problema: os ciclos de escrita, que em geral são em segundos.
Isso quer dizer que em um cenário de queda/falha/shutdown ou reboot, os dados imputados ou alterados desde o último ciclo até o momento do shutdown são perdidos.
Sendo assim, REDIS eu uso para cache, e somente cache passivo (alguém que sabe processar um recurso de alto IO, usa o Redis para não realizar a tarefa e mas quando necessário a faz, preenchendo o cache novamente).
Dito isso, Redis não é uma opção para nenhum dos assuntos que listou. Pelo menos para mim. Para um chat e status, sinceramente eu usaria SignalR.
De qualquer forma, RabbitMQ pode resolver suas questões com certa facilidade também, já que trabalha com Stomp e Mqtt protocolos de mensageria feitos para a web. Na documentação você encontra detalhes sobre os plugins e como habilitá-los. Eu tenho uma apresentação que mostra isso e tem um repositório com exemplos “Message Broker & .Net Core – Introdução ao RabbitMQ” https://gago.io/blog/message-broker-net-core-introducao-ao-rabbitmq/.
Se você é iniciante, redobre o cuidado, há maior probabilidade de tomar decisões erradas do que certas, e revalidar suas próprias decisões quebra esse dogma da juventude. É sadio revisar as premissas que levaram a uma decisão.
No mais obrigado por participar perguntando, é muito legal ver que está lendo, vi que já viu os 6 posts! Obrigado mesmo!
Tem um post novo, acho que agora você vai começar a entender o argumento para não usar Redis para mensageria resiliente | https://gago.io/blog/rabbitmq-amqp-8-redis/
Oi Luiz, também sou iniciante em RabbitMQ e fiquei com algumas dúvidas referente ao Ack:
– O que esse código faz?
channel.BasicAck(deliveryTag: ea.DeliveryTag, multiple: false);
O código acima complementa esse?
channel.BasicConsume(queue: “hello”,
autoAck: false,
consumer: consumer);
Ack é uma abreviação de Acknowledge.
Quando configuramos o consumo com AutoAck falso estamos buscando resiliência, isso quer dizer, estamos dizendo para o RabbitMQ para que ele só delete a mensagem da fila após receber um comando Ack (que é exatamente o que fazemos quando chamamos o método BasicAck do Model/Channel).
Sim, são complementares.
Quando trabalhamos com AutoAck true, é forma mais performática e não resiliente, onde a mensagem é deletada da fila no momento em que é entregue para o consumidor. Isso quer dizer que se algo ocorrer e falhar, a mensagem está perdida para todo o sempre!
Ficou claro?
Há bons cenários de uso para AutoAck true e AutoAck false, vale a pena uma googlada para dar uma olhada nisso.
Show, parabéns pelo artigo.
Eu fiquei com uma dúvida, como faria para consumir as mensagens utilizando uma aplicação ASP.NET MVC ou uma API por exemplo? Não entendi como deixar essa aplicação escutando os eventos dessa fila.
Opa Valdir, obrigado.
Uma aplicação web não é o melhor lugar para você hospedar o consumo de filas. Tanto a aplicação web, quanto o consumo de filas demandam escala. Por motivos diferentes, por demandas diferentes. E amarrar as duas causa, inevitavelmente o acúmulo de responsabilidades fazendo com que uma atrapalhe a outra.
Dito isso, sim é possível sim, desde que não seja uma aplicação web antiga (cujo ciclo de vida é gerenciado pelo IIS).
Se seu processo não sofre recycle, e você tem controle do ciclo de vida dele, pode usar uma aplicação web sim, embora eu não te aconselhe a fazer isso.