
Se você já me viu falar de persistência, você talvez já saiba do que eu estou falando, mas talvez não entenda os argumentos.
A história do NHibernate
NHibernate é um full featured ORM que nasceu em 2005 como um port do Hibernate do Java aqui na plataforma .NET.
O Hibernate do Java nasceu em 2001, e a versão .NET pode herdar, toda a história de erros e acertos do Java, que fez dele um sucesso pelo lado de lá.
A comunidade Java naquele momento, estava anos luz à frente da comunidade .NET no que diz respeito à orientação a objetos, não só por ter nascido em 1995 enquanto a gente estava começando em 2002. No Hibernate as principais decisões foram baseadas nos interesses e anseios da comunidade e não no interesse da SUN, nem JBoss, nem da ORACLE.
Aqui todo o acesso a dados era projetado pela perspectiva da Microsoft e não pelas decisões autônomas da comunidade.
Aqui no mundo Microsoft, pela forma maternal com que a Microsoft cuida de seus clientes, nós não fomos “obrigados” a adotar .NET, o mercado permaneceu com VB, VB.NET e ASP por muito tempo, fazendo com que a adoção de .NET por algum tempo fosse quase que exclusiva de early adopters.
Ao mesmo passo a quantidade de desenvolvedores trabalhando com .NET que migraram das tecnologias anteriores era enorme. E novamente, com essa visão maternal, a Microsoft sempre tentou “simplificar” e “facilitar” até o que não deveria.
Não é a toa que do lado de cá, vimos WebForms por tanto tempo, além dos famigerados DataSet, DataTable, DataAdapter etc.
O port do Hibernate no NHibernate traz consigo algumas considerações importantes:
- Hibernate era um sucesso na comunidade Java.
- Entre erros e acertos se passaram 4 anos e 2 grandes releases. A primeira e a segunda que de fato mudou o rumo do projeto.
Meu primeiro contato com NHibernate
Meu primeiro contato com NHibernate se deu em 2005, quando o projeto estava no início do seu desenvolvimento. Naquela época ainda era comum usarmos DataTables e DataSets.
Mas o NHibernate já vinha com uma visão diferente, onde desenhávamos nossos POCOs (plain old c# object), mapeávamos nossos objetos e usávamos em diversos bancos!
Antes de começar a usar NHibernate, usava bastante um projeto chamado Gentle.NET. O que sobrou do projeto ainda está no SourceForge ( https://sourceforge.net/projects/gopf/ ).
Desde 2005 até os dias de hoje muita coisa mudou. A Microsoft dobrou de tamanho algumas vezes, o ciclo de vida de lançamento do .NET aumentou. Um novo runtime inteiro foi criado. Agora somos multiplataforma, damos suporte à docker, podemos trabalhar Cloud Native first.
Mas uma coisa não aconteceu: Ainda não houve um segundo acerto no acesso a dados tão grande quanto a do ADO .NET.

A história do acesso a dados na plataforma .NET
Eu não sei desde quando você trabalha com .NET, eu trabalho desde as primeiras versões.
Vamos lembrar da história:
ADO .NET
ADO .NET: Nasce junto com o .NET em meados de 2000 com base no ADO, conjunto de bibliotecas COM do VB6. Agora repaginado com o nome de ADO.NET, com uma clara atualização no estilo e forma de realizar as atividades no acesso a dados.
DataTable, DataSet e DataAdapter: Uma visão horrenda baseada em tabelas e modelos virtuais.
Enterprise Library: DAAB
Em 2005 a Microsoft lança o Microsoft Enterprise Library, bibliotecas que traziam application blocks para os principais dilemas de aplicações corporativas. (Fonte)
Um dos principais Application Block, dos mais usados era o Data Access Application Block, destinado ao acesso a dados.
Data Access Application Block: Uma tentativa de copiar o Spring do java que deu muita dor de cabeça por aqui.
.NET Framework 3.5 e LINQ
Em 2007 nasceu o LINQ e com ele o LINQ to SQL (Fonte)
LINQ to SQL: LINQ to SQL começou a deixar as coisas mais engraçadinhas, e mais parecidas com o que temos hoje. Mas ainda tinha graves problemas de performance. Mas o Linq, integrado à linguagem, era algo incrível e revolucionário, embora o resultado prático fosse um caos.
Entity Framework
O Entity Framework desembarcou dos headquarters da Microsoft para a comunidade em 11 de Agosto de 2008, junto com o NET Framework 3.5 Service Pack 1 e Visual Studio 2008 Service Pack 1 (Fonte).
Entity Framework: Sem sombra de dúvidas até o momento é a melhor solução de acesso a dados com a marca Microsoft. Mas isso não foi o suficiente para considerar sequer uma boa solução.
Conclusão
Em menos de 3 anos, ou seja, de 2005 a 2008, foram 3 tentativas frustradas de criar alguma abstração decente sobre o ADO .NET.
A Microsoft falhou miseravelmente em todas as 3 iniciativas.
Eram soluções ruins, engessadas, difíceis de produzir novos providers, feitas apenas para trabalhar com o SQL Server, ignorando a possibilidade de usar qualquer outra tecnologia de banco.
Após inúmeras reclamações e acenos de outros fornecedores de bancos de dados e os clientes que tinham essa demanda, ao ponto de não ser incomum usar a difícil compatibilidade como argumento para adotar outras tecnologias que não .NET, para aplicações que eram obrigadas a usar determinados banco de dados, como Oracle, DB2, Postgres e MySQL.
No ADO.NET já tínhamos providers para outras plataformas, mas a cada novo framework de acesso a dados, produzido pela Microsoft, demandava que os fornecedores criassem adapters novos e isso leva tempo até alcançar algum nível de maturidade.
O que quero trazer com muita clareza é que depois do ADO .NET, que eu acho uma arquitetura muito vencedora, e a estabilidade do seu design é uma demonstração clara disso, a Microsoft não conseguiu produzir absolutamente NADA com notável e notória qualidade além do LINQ ( Linguagem SQL Based incorporado ao C#).
Ou seja Enterprise Library, LINQ TO SQL e Entity Framework nasceram em 3 anos, e nenhuma delas era notoriamente boa, ou ao menos completa o suficiente.
Como eu escolhi NHibernate para a Petrobras em 2005?
Em 2005 eu buscava a solução de acesso a dados para o Framework Corporativo Petrobras. Eu participava do time de Suporte ao Desenvolvimento da Petrobras Macaé, a maior unidade de negócios do país, e minha missão era a de propor o modelo de acesso a dados.
Claro que eu não era o senior do time, e a decisão não era minha. Meu papel era estudar as tecnologias disponíveis no mercado e produzir avaliações e por um uma recomendação.
Minha análise seria avaliada e debatida por todo o time, inclusive os seniors e arquitetos de verdade.
Eu usava Gente.NET nos meus projetos pessoais, no entanto isso não me dava o direito de sair recomendando o que eu usava. Eu não havia parado para fazer um estudo profundo. Minha decisão por usar o glentle era muito mais por ser prático o suficiente para os meus projetos, coisas que eu fazia sozinho, sem outras demandas.
Eu nos meus projetos pessoais só tinha a demanda para uma solução que definitivamente funcionasse e que não fosse muito lenta. Eu não precisava me preocupar com absolutamente mais nada.
Olhando para a necessidade de propor o ORM da empresa, e de uma empresa com o tamanho da Petrobrás, era óbvio precisava de novos critérios, bem mais específicos e com ambições corporativas.
Eu não poderia recomendar o Gentle .NET sabendo que um eventual problema poderia custar milhões, caso desse alguma dor de cabeça grande.
Um estudo para adotar algo para o framework corporativo dependia de entender quais eram os melhores players e o que eles ofereciam. E como eu era jovem, e de certa forma amedrontado com o desafio, para que eu me sentisse seguro defendendo A ou B eu queria chegar ao nível de conhecer o código para poder produzir uma opinião carregada de fortes e contundentes argumentos, ao ponto de não poder ser refutado. Para isso eu queria ler o código e entender cada um dos ORM’s.
Essa parte foi bem curiosa, porque alguns foram mais fáceis de entender outros mais difíceis. Alguns você via um acoplamento claro e nítido entre classes, e do outro lado via mais abstrações injetáveis. E isso me chamou muito a atenção. Como havia uma separação clara de responsabilidades. Como os padrões faziam sentido e por mais que à primeira vista você pensasse “Pra que isso?” ou “Qual problema isso está resolvendo?” dois passos seguintes você entendia o motivo.
Minha escolha se deu por
- Funcionalidades
- Qualidade de código.
- Herança da experiência do Java.
- Possibilidade de reaproveitar a galera do Java em projetos .NET
NHibernate era o mais maduro, era o que tinha a maior comunidade, a maior quantidade de projetos. Herdava o histórico de erros e acertos lá do java, que multiplicava por 10 a quantidade de usuários. Ao ponto de ser possível olhar a documentação do java para achar algo aqui no .NET. Até as exceptions eram as mesmas.
O fracasso
Eu, após ~3 meses tomei minha decisão, e passei mais 2 meses para conseguir sustentar minha defesa em uma apresentação para a equipe. Não era fácil conciliar as agendas, essa ideia de framework corporativo demandava viagens dos meus superiores, dos seniors, dos arquitetos, de todo mundo… bom, quase todo mundo!
Quando eu fiz a defesa, eu falhei miseravelmente, de diversas formas. Mas a principal foi achar que eles viam o que eu via. Foi falta de marketing, falta de jogo de cintura, falta de discernimento sobre como eu poderia cativar os caras.
Eu fui afoito, evitei expor o que era óbvio, embora o óbvio precisasse ser dito.
A decisão dos caras foi construir um ORM do absoluto Zero!
Essa decisão de bosta me matou por dentro. 6 meses jogados no lixo, para tomar uma decisão bosta dessas com dinheiro da caralha do filha da puta do contribuinte: Nós! Eu, você, seu pai, sua mãe toda a sua e a minha famílias.
PS: essa história tem plot twist!
Porque eu continuo adotando NHibernate em 2022?
O primeiro ponto é que para muita gente o “Default” é Entity Framework.
Eu respeito, mas para a experiência com acesso a dados que eu tenho, o default nos meus projetos não é Entity Framework.
O default nos meus projetos é o NH.
E não ache que eu sou “do contra” ou “diferentão” há milhares de desenvolvedores que compartilham da mesma visão.
O Entity Framework é um projeto medíocre em relação ao que poderia ser, principalmente por se tratar de um projeto construído dentro dos headquarters da Microsoft.
Se o EF fosse de fato bom, Dapper nem teria nascido, ou se tivesse, não teria abocanhado uma fatia tão significativa dos projetos.
A forma como a Microsoft lida com a produção das suas próprias libraries, produz uma concorrência desleal.
Todo concorrente morre de inanição no segundo seguinte que a Microsoft anuncia que criará alguma coisa naquela direção.
Dapper não é uma exceção, a Microsoft que tem sérios problemas de design, quando o assunto é acesso a dados, seu último grande acerto foi há 20 anos atrás com o ADO.NET.
O primeiro ponto é que eu preciso de um ORM que seja flexível e me ajude ao invés de me limitar. Muitas vezes (mais de 5) eu vi trocas do EF para outra estratégia de acesso a dados por conta de problemas de performance no acesso a dados.
Já vi adoção de procedures, já vi adoção de CQRS por conta de problemas do ORM.
A adoção de CQRS por esse motivo, é a pior pra mim. Até porque os cenários eram típicos cenários de no máximo algumas centenas de usuários. Nada absurdo.
Houve casos em que já usávamos NH e os problemas de performance foram resolvidos acertando as configurações. Teve cenário em que coloquei cache L2.
No EF eu tentei fazer uma implementação de um cache L2 em 2015, mas foi bem chato ter de injetar forçadamente alguns objetos lá dentro do EF, em lugares que sequer eram extensíveis. Somente agora em
Ele não foi pensado nisso, fato.
Features com mais de 10 anos no NH que não existem ou chegaram há pouco tempo no EF:
- Estratégia de Join: Na hora de trazer um objeto e suas dependências, eu consigo escolher se vai vir via join, ou subselects, ou selects paralelos.
- Suporte 1st Class aos mais variados bancos: Eu não preciso ficar preocupado com a birra do provider com a Microsoft. Os principais bancos dão suporte desde sempre.
- 1×1, NxN, 1xN … todos os modelos de relacionamento com chave simples ou chave composta.
- Coluna timestamp: controle automático.
- Version: Controle de concorrência.
- Componente: Mapeamento de tipos complexos como parte de uma entidade.
- Não necessidade do campo ID da referência do mapeamento.
- Herança por classe, por subclasse, por classe concreta
- 2 mecanismos LINQ (performance vs completude)
- Pelo menos 3 estratégias de consulta
- Query
- QueryOver
- Criteria
- Métodos avançados para produção de specification pattern (Criteria)
- Interceptors
- Second Level Cache (com a possibilidade de uso do redis)
- Lazy Load
- Para Relacionamentos
- Para Colunas (excelente para cenários com CLOB, BLOB etc).
Então eu uso tudo isso?
Não! Da mesma forma como eu não faço todos os exames, simplesmente por ter um plano de saúde.
No entanto me deparei com uma questão esses dias.
Eu estava monitorando, via log console, todas as queries que eram executadas e me deparei com um dilema. Eu tenho algumas colunas do tipo CLOB em uma tabela. Essa tabela possui um JSON em uma coluna, e um HTML em outra coluna. Ambas são CLOB’s.
Nada de errado com o tipo do dado, nada de errado com o armazenamento em tabelas.
Ao olhar para a query que o NHiberante estava fazendo, eu percebi que eu estava trazendo ambos os campos em todas as consultas, inclusive nas de listagem que não necessitam desse dado.
Que bom que eu percebi, pois a solução me custou 1 linha de código.
Era só definir que a propriedade era Lazy.
E como eu tenho um extension method para centralizar meus requirements… só precisei acertar nele. Todo campo CLOB é mapeado como Lazy. Problema resolvido!
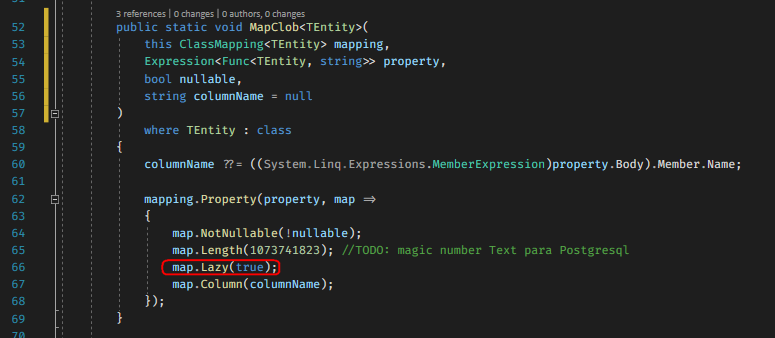
Esse é o Extension Method de que falei.
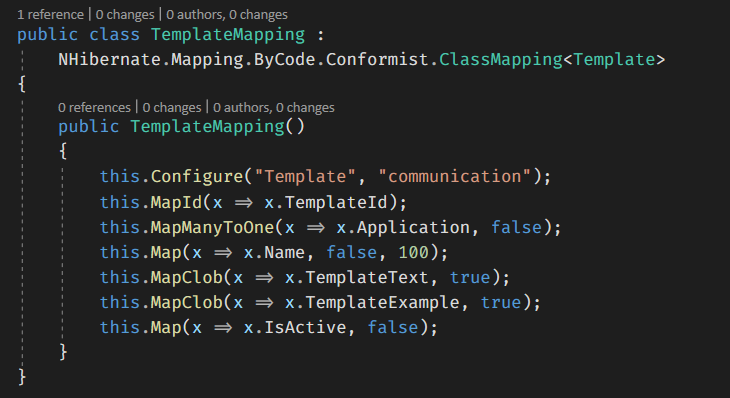
Esse é o resultado do meu mapeamento. E claro só está tão simples porque eu fui criando minhas extensões para resolver questões bobas, como as que você viu acima.
O ponto, é que eu tenho total flexibilidade.
Em muitos dos projetos que eu vi sofrendo uma rearquitetura para CQRS por conta de performance e consumo de banco, que sinceramente coloco minha mão no fogo de que na maioria, se usasse NH, era apenas uma questão de configurar o cache L2 para conseguir aguentar.
A opinião de Vladimir Khorikov
Vladimir Khorikov é autor, e produziu uma comparação EF vs NH no post EF Core 2.1 vs NHibernate 5.1: perspectiva DDD, e atualizou esse post ano passado.
A equipe EF Core está colocando muito esforço, e EF Core está lentamente se aproximando da paridade com o NHibernate. Mas ainda está anos-luz atrás, e eu nem menciono todos os outros recursos não relacionados ao DDD.
E, francamente, não tenho certeza se algum dia alcançará a paridade. Quão difícil pode ser olhar para o NHibernate e copiar sua funcionalidade, pelo menos nas áreas-chave? E ainda, com todos os recursos disponíveis, o sinalizador ORM da Microsoft não está nem perto do concorrente que está sendo desenvolvido por apenas um punhado de pessoas.
E se você insiste que não existe um caminho único e que talvez a equipe EF Core tenha sua própria visão de como os ORMs devem funcionar, basta olhar para a progressão da EF. Quanto mais recente for o lançamento, mais próximo estará do NHibernate em termos das principais decisões de design. A equipe eventualmente chega às mesmas conclusões (ver ## 2, 3, 4, 6), exceto que no NHibernate, eles foram implementados há mais de uma década.
A Microsoft deveria ter adotado o NHibernate desde o início, e não tentado reinventar a roda. Este trem já se foi há muito tempo e ninguém vai abandonar o EF Core, então a próxima melhor coisa seria tentar acelerar a convergência e finalmente começar a ver como os outros resolvem os mesmos problemas. Implementar Objetos de Valor com múltiplos valores apropriados (leia: copiar o recurso Componente do NHibernate), o trabalho com gráficos desconectados de objetos, carregamento lento. Isso seria um bom começo.
Pare de trabalhar em recursos que não deveriam ter chegado ao ORM em primeiro lugar. Como o recurso de exclusão suave, por exemplo. A exclusão temporária deve ser responsabilidade do domínio, não algo que você delegue ao ORM.
Desenvolvedores, experimentem o NHibernate. Eu o tenho usado para construir modelos de domínio altamente encapsulados e limpos por muitos anos. E agora que ele oferece suporte a operações assíncronas e .NET Standard , não há motivo para não fazê-lo . A combinação que geralmente funciona melhor para mim é: NHibernate para comandos (operações de gravação) e Dapper para consultas (operações de leitura).
Vladimir Khorikov / Tradução Google Tradutor / post original
Por acaso estava escrevendo esse post e o Paulo Eduardo Correia postou o link no grupo do Docker Definitivo. Obrigado!
Conclusão
Quando eu penso em um ORM eu penso em um parceiro, um componente que me ajude. Quero poder começar meu desenvolvimento usando as abordagens mais práticas, caso haja demanda, vou trocando praticidade por performance.
E se ainda não for suficiente, tenho a chance de colocar um cache server.
São movimentos pensados previamente.
Agora eu estou te entregando meu pipeline de decisão, simples assim.
Sobre aquela 1 linha (o Lazy), não foi tão poético! Quando vi a coluna vindo na query, resolvi criar uma tabela e uma relação 1×1 com lazy, exatamente como se faz no EF. Isso porque eu não lembrava como funcionava no NH. Voltei à doc porque tinha uma pulga atrás da orelha. Algo me dizia que não era possível que isso ainda não tivesse sido solucionado em 2021. Enfim, achei, desfiz minha grande mudança e fiz a alteração de 1 linha.
É esse tipo de flexibilidade que eu espero de um ORM, e é isso que eu encontro no NH e não encontro no EF.
E sendo bem sincero, pela forma como o EF continua “acelerando” em ritmo de tartaruga. Só falta a comunidade se tocar.
Plot Twist da história da escolha do EF na Petrobras
Por volta de 2009~2010 um amigo me contou que após 2 anos de sofrimento, decidiram abandonar o ORM Made in BR, para adotar o NHibernate por volta de 2007~2008.
Enfim… embora eu tenha ficado puto da vida, em 2005, essa história ajudou a me forjar.









0 comentários