
Segunda-feira, 14h. Pico de tráfego. Sua aplicação .NET começa a derreter conexões com o RabbitMQ. Você abre o Grafana, vê 800 conexões abertas contra um broker que aguenta confortavelmente 50, e a hipótese imediata é “vamos limitar o pool”. Alguém sobe um SemaphoreSlim, faz deploy, e na quarta-feira o problema inverte: as conexões caem para duas, ficam ociosas, e quando o próximo burst chega, a latência explode porque cada nova publicação está pagando 200ms de handshake TLS + AMQP.
Esse vai-e-volta é o sintoma.
A causa é mais profunda: recursos caros e voláteis estão sendo tratados como recursos baratos e estáveis.
E quase nenhuma abstração padrão do .NET lida bem com isso.
… até hoje!
Diagnóstico: o que “recurso caro” realmente significa
Quando falamos de pooling no ecossistema .NET, a referência mental costuma ser Microsoft.Extensions.ObjectPool, otimizado para um caso de uso bem específico:
- objetos baratos de criar
- stateless
- sem ciclo de vida
StringBuilder- buffers
- parsers
Para esse cenário, ele é excelente. MaximumRetained cobre o problema.

O problema é que ninguém pouca gente usa pooling para StringBuilder em produção, em aplicação crítica.
As coisas que realmente precisam de pool são outras:
- Conexões Kafka (
IProducer<TKey,TValue>da Confluent.Kafka): bootstrap de metadata + descoberta de partições + autenticação SASL/SCRAM custa centenas de ms na primeira mensagem. - Conexões SQL Server / PostgreSQL / MongoDB: o pool nativo do ADO.NET resolve parte do problema, mas só dentro do seu próprio escopo, sem hooks de saúde customizáveis e sem visibilidade de telemetria do que o engine decide.
- Conexões RabbitMQ (
IConnectiondoRabbitMQ.Clientv7+): handshake TCP + TLS + AMQP custa entre 5ms e 300ms. CadaIConnectionocupa um socket, mantém heartbeat, e tem limite de 2047 canais por padrão no broker. - Clientes HTTP de longa duração (
HttpClientcomSocketsHttpHandlercustomizado, ougRPCChannel): criar o handler reinicia o pool TCP interno; reutilizar indefinidamente sem health-check leva a conexões zumbis após failover de load balancer. - Conexões Redis (
StackExchange.Redis.ConnectionMultiplexer): a recomendação oficial é manter uma instância única por processo, mas em cenários multi-tenant ou multi-shard, você precisa de várias, cada uma cara para inicializar. - Clientes de cloud SDKs (S3, Azure Service Bus, Google Pub/Sub): autenticação OAuth/IAM, descoberta de regiões, configuração de retry policies — tudo isso acontece na construção.
- Browsers headless em workers de scraping ou geração de PDF (Playwright, Puppeteer): cada instância consome centenas de MB de RAM e leva segundos para subir.
Todos esses recursos compartilham três características que ObjectPool não modela:
- Custo de criação assimétrico: criar é caro, reutilizar é barato, descartar é caro também.
- Estado interno mutável: a instância pode “quebrar” silenciosamente (socket morto, token expirado, conexão TCP em estado FIN_WAIT esperando timeout do SO).
- Demanda altamente variável: por horas inteiras, uma única instância basta. Em segundos, você precisa de cem.
Todos nós já tentamos resolver isso em algum momento
Quem trabalha com sistemas distribuídos há tempo suficiente, já implementou alguma variação desse pool pelo menos três vezes. E cada implementação descobre, da pior forma possível, o mesmo conjunto de armadilhas.
Armadilha 1: o pool que cresce mas não diminui
Você sobe a aplicação, ela cresce até 64 conexões durante um pico noturno, mas às 4 da manhã com 2 requisições por minuto, ainda tem 64 conexões abertas consumindo memória, heartbeats e file descriptors. O Kubernetes não consegue fazer scale-down porque o pod nunca libera recursos. O time de SRE chama a aplicação de “leaky”.
Armadilha 2: o pool que encolhe rápido demais
Para evitar a armadilha 1, alguém implementa um timeout agressivo. Agora, toda vez que o tráfego oscila entre vales e picos (o que é a norma, não a exceção), o pool destrói e recria recursos compulsivamente. Você acabou de transformar um problema de memória em um problema de latência e thrashing.
Armadilha 3: o handshake do diabo
A instância está no pool, parece saudável (IsOpen == true), você empresta para a thread, ela tenta usar, e descobre que o servidor do outro lado fechou a conexão silenciosamente há 30 segundos. BasicPublishAsync lança AlreadyClosedException. A thread captura a exceção, descarta a instância, pede outra ao pool, e tem 70% de chance de receber outra conexão morta do mesmo lote. Stampede de reconexão. Broker entra em sobrecarga.
Armadilha 4: o pool que não conta
Você usa um ConcurrentBag<IConnection> com um contador Interlocked.Increment. Funciona. Até o dia em que uma exceção na factory deixa o contador inflado sem que nenhum recurso real exista. A partir desse momento, o pool acredita que tem 32 conexões disponíveis quando na verdade tem 30. O 31º caller espera para sempre. Isso é o que chamamos de “ghost reservation” — um bug que não aparece em testes unitários e só se manifesta após semanas de operação.
Armadilha 5: o waiter perdido
Implementações ingênuas usam Monitor.Wait / Monitor.Pulse ou TaskCompletionSource em listas. Sob alta concorrência, o handoff entre quem libera e quem espera tem uma janela onde o Pulse acontece antes do Wait. Resultado: a thread fica parada para sempre em uma fila vazia, esperando uma notificação que já foi enviada. Você descobre isso quando o circuit breaker dispara no upstream.
AutoScalling não é suficiente
Toda discussão sobre elasticidade em .NET eventualmente esbarra em alguém sugerindo “deixa o HPA cuidar disso“.
A premissa é sedutora: se a aplicação está sob pressão, o Kubernetes escala horizontalmente, sobe mais pods, distribui a carga.
Por que se preocupar com pool no processo?
A resposta está na escala de tempo.
O HPA opera em ciclos de avaliação de 15 segundos por padrão, e mesmo após decidir escalar, o ciclo completo: scheduler colocando o pod em um node, pulling da imagem se não estiver em cache, container start, readiness probe, registro no service discovery leva entre 30 segundos e 2 minutos para clusters bem dimensionados, e pode chegar a 10 minutos quando o Cluster Autoscaler precisa provisionar um node novo na AWS, GCP ou Azure.
Já o burst de tráfego que derruba seu pool acontece em 200ms.
Quando o pod novo finalmente entra em rotação, o pico já passou e agora você tem capacidade ociosa que vai demorar mais alguns minutos para o HPA decidir reduzir, geralmente com stabilizationWindowSeconds de 5 minutos para evitar flapping.
O pool elástico opera na escala de microssegundos a milissegundos;
o autoscaling opera na escala de dezenas de segundos a minutos.
São camadas complementares, não concorrentes:
- o pool absorve a volatilidade de curto prazo dentro de cada réplica,
- o HPA ajusta a capacidade agregada de médio prazo.
Sem o pool, o HPA precisa ser configurado de forma reativa demais (CPU thresholds baixos, cooldowns curtos) e passa a oscilar; com o pool, o HPA pode trabalhar com sinais mais estáveis, porque cada réplica já está absorvendo internamente os picos que duram menos que seu ciclo de decisão.
E há um ponto que costuma passar batido nessa discussão: nem toda aplicação .NET roda em Kubernetes.
Workers rodando em Containers com Docker Compose, diretamente em VM’s, ferramentas de linha de comando que processam lotes. Todos esses cenários têm exatamente o mesmo problema de gerenciamento de recursos caros, sem ter qualquer orquestrador para chamar de socorro.
Tratar pool como problema de infraestrutura terceiriza para fora do código uma responsabilidade que pertence ao próprio runtime da aplicação.
Quando a arquitetura piora a engenharia
Esse conjunto de problemas se intensifica quando a aplicação é distribuída. Em uma arquitetura de microsserviços orquestrada com Kubernetes, cada réplica do pod mantém seu próprio pool. Se você tem 30 réplicas e cada uma sobe até 32 conexões no pico, são 960 conexões simultâneas. O alvo das conexões pode aceitar mas alguém deveria questionar.
Pior: durante um rolling deployment, os pods novos sobem com pools vazios e os pods velhos morrem com pools cheios. Por alguns segundos, você tem 2x a capacidade alocada. Em sistemas com SLAs apertados, esse spike é exatamente quando os timeouts começam a se acumular e o HPA decide escalar mais, quando, na realidade, o problema vai se autorresolver em 30 segundos.
Tudo isso se aplica também a:
- OpenTelemetry: pools sem instrumentação são caixas-pretas. Você não sabe se está sub-dimensionado ou super-dimensionado. Sem métricas como
pool.size,pool.waiting,pool.acquire.wait.duration, qualquer ajuste é chute calibrado. - Aspire / Dapr: orquestradores assumem que serviços expõem health checks e graceful shutdown. Um pool que não responde a
IHostApplicationLifetime.ApplicationStoppingsegura o pod por minutos durante oterminationGracePeriodSeconds, derrubando deploys. - Redis distribuído com cache + lock: o
ConnectionMultiplexerfaz seu próprio pooling interno de sockets, mas se você usa múltiplos multiplexers para isolar workloads (caching vs. distributed locks vs. pub/sub), a coordenação de saúde entre eles vira responsabilidade da aplicação.
É um custo que não aparece em nenhuma planilha
A consequência prática de não resolver esse problema corretamente costuma aparecer em três camadas:
A primeira é financeira
Pods super-dimensionados em AKS, EKS ou GKE custam dinheiro continuamente. Brokers RabbitMQ, ElastiCache Redis ou Confluent Kafka cobram por conexão concorrente em alguns tiers. Uma aplicação que mantém 4x as conexões necessárias durante 22h por dia desperdiça orçamento de cloud silenciosamente.
A segunda é operacional
Times de SRE passam ciclos investigando “latência intermitente” que se resolve sozinha. Postmortems apontam para “thundering herd após failover do broker”, mas nunca chegam à causa real: o pool não sabe distinguir um recurso morto de um vivo até tentar usá-lo. As soluções aplicadas (timeouts, circuit breakers, retries com backoff) tratam sintomas e adicionam complexidade.
A terceira é arquitetural
Como o pool é frágil, decisões de design começam a evitá-lo.
- “Não vamos usar mensageria assíncrona porque conexão com RabbitMQ é instável“,
- “vamos fazer batch para evitar muitas conexões com o banco“,
- “vamos usar HTTP síncrono em vez de gRPC streaming“.
- “Vamos abrir uma conexão nova a cada requisição e fechar no final” onde toda operação que passa no fluxo paga o custo de handshake, mas pelo menos é previsível. O time troca latência consistente alta por latência variável imprevisível.
- “Vamos consumir Kafka com batch grande e commit manual a cada hora” em vez de processar streaming contínuo, o time força o workload a se comportar como batch para minimizar o número de sessões de consumer ativas, perdendo a vantagem de processamento near-real-time.
- “Não vamos usar gRPC bidirectional streaming, vamos fazer polling com REST” o cliente gRPC mantém conexão HTTP/2 aberta, e pool de
GrpcChannelé considerado “risco”. Volta-se a fazer 60 requisições por minuto em vez de 1 stream aberto. - “Vamos colocar um proxy/sidecar na frente” Envoy, Linkerd, HAProxy assumem a responsabilidade de pooling. Funciona, mas adiciona um hop de rede, mais um componente para operar, mais um lugar para falhar, e mais latência. A complexidade migra de dentro do código para o cluster.
Nenhum desses cases são hipotéticos, cada uma dessas decisões são reais e já vi sendo tomadas, uma, duas ou mais vezes, mas o ponto é que cada uma representa uma capacidade arquitetural perdida porque uma abstração de baixo nível não foi resolvida em sua plenitude.
Essas são respostas para problemas dos quais os times sequer sabiam que tinham. E pior, hoje, em pleno 2026, a maior parte dos times sequer sabe que sofre.
O que separa um pool ingênuo de um pool sério?
Esse é um tema importante, pois em 2020 escrevi “Ring Buffer – Antecipe, otimize e evite custos excessivos” (link), onde abordei como RingBuffer como forma de trazer a questão à tona. Depois, em 2025 escrevi o “Otimizando consumo de recursos em aplicações .NET com RingBuffer” ( link ) onde inclusive trouxe um esboço de implementação, apenas para ilustrar.
Em Out/2020 fiz o projeto Oragon.Common.RingBuffer que serviu de esboço e inspiração para o Fernando Cerqueira (EA – Arquiteto sênior | Microsoft MVP 2004~2014 | ☁️Cloud ♾️DevOps |⚙️C#/.NET Especialista | 💙Palestrante em Tecnologia e Inovação) implementar o projeto e library RingBufferPlus, do qual fiquei muito honrado de de alguma forma ter incentivado.
Circular Buffer/Ring Buffer não é um assunto novo, segundo o google trends, ele teve pico de pesquisa em 2004 e só volta a bater 70% do interesse de 2004 em 2022.
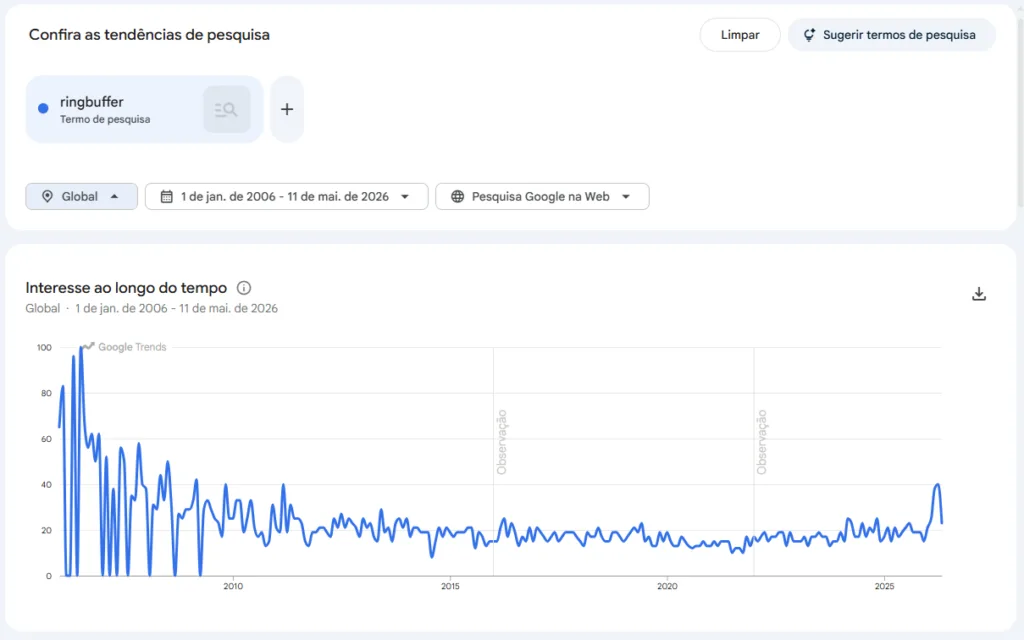
- Naquela época, não tínhamos Docker.
- As iniciativas no kernel do Linux só aconteceriam em 2008, 4 anos no futuro.
- Ainda usávamos muito VMWare e similares,
- a Amazon AWS só seria lançada 2 anos depois, em 2006.
- Google GCP só nasceria em 2008
- e o Microsoft Azure só nasceria em 2010.
- Kubernetes só nasceria em 2015
Mas qual a relevância de um Circular Buffer, Ring Bufer, Object Pool em 2026?
A mesma de sempre.
O problema nunca foi resolvido.
Um pool genérico, elástico e self-healing precisa resolver, simultaneamente, problemas que parecem ortogonais mas estão entrelaçados:
- Crescimento por sinal composto:
- não basta crescer quando há um waiter.
- É preciso considerar utilização sustentada (média móvel em janela de 30s),
- p95 do tempo de espera,
- e número de waiters parados tudo isso simultaneamente,
- porque cada métrica isolada gera falsos positivos.
- Encolhimento histerético:
- encolher precisa de cooldown (não diminua imediatamente após crescer),
- threshold de baixa pressão sustentada (não confunda vale momentâneo com queda real),
- e batch size controlado (não destrua 30 conexões de uma vez).
- Health hooks em cinco estágios:
Factory(criação),BeforeUse(validação cheap antes de entregar),Check(probe periódico em background),AfterUse(validação após retorno),Release(cleanup determinístico).- Cada estágio existe porque cada um detecta uma classe diferente de falha.
- Failure policy plugável:
- o que fazer quando um recurso falha varia conforme o domínio.
- Em alguns casos, descartar e recriar.
- Em outros, quarentenar para análise.
- Em outros ainda, escalar um alerta porque a falha indica problema infraestrutural.
- Telemetria nativa:
Meter,ActivitySourceeILoggersource-generated, com tags de baixa cardinalidade, integrados ao OpenTelemetry sem configuração extra.
- Async-first e DI-first:
ValueTask<T>em todo o hot path, registro keyed emIServiceCollection, suporte aIHostApplicationLifetimepara graceful shutdown.
A maioria das implementações caseiras resolve duas ou três dessas dimensões. As que tentam resolver todas acabam virando bibliotecas internas mal mantidas, com cobertura de teste pobre, sem benchmarks de elasticidade real, e que ninguém quer tocar quando o autor original muda de empresa.
O que vem depois
Existe um padrão recorrente em sistemas .NET de grande porte: o time descobre, por tentativa e erro, que precisa de um pool genérico com elasticidade, auto-healing, hooks de ciclo de vida e telemetria.
Implementa internamente.
A implementação fica frágil. Migra para outra.
Repete o ciclo.
A pergunta relevante não é “como faço meu pool funcionar“.
É: por que esse padrão, tão central em sistemas distribuídos modernos, ainda exige reimplementação a cada projeto?
Se você está olhando para o pool de conexões da sua aplicação agora: RabbitMQ, Kafka, Redis, SQL, gRPC, HTTP e não consegue responder com precisão quantas conexões existem, há quanto tempo cada uma está ociosa, qual o p95 de tempo de espera por uma conexão livre, e o que acontece com waiters parados durante um shutdown,
você não tem um pool.
Você tem um acúmulo de objetos com sorte estatística.
E a sorte, em produção, sempre acaba às 14h de uma segunda-feira, ou às 19h da sexta.
Leitura adicional

Circular Buffer, Ring Buffer, ObjectPool e Objects Pools Elásticos
Segunda-feira, 14h. Pico de tráfego. Sua aplicação .NET começa a derreter conexões com o RabbitMQ….

Otimizando consumo de recursos em aplicações .NET com RingBuffer
Frequentemente nos deparamos com desafios relacionados ao gerenciamento eficiente de recursos limitados, como conexões de…

Ring Buffer – Antecipe, otimize e evite custos excessivos
https://github.com/luizcarlosfaria/Oragon.Common.RingBuffer
https://github.com/FRACerqueira/RingBufferPlus
Em 202, João Portela, publica a primeira versão no Nuget.org do CircularBuffer, aparentemente o projeto que nasce em 2013, mas fica de 2013 a 2018 sem commits, e só chega ao Nuget.org em 2021.
Quando começamos esse assunto em 2020, era só mato!









0 comentários