
Abstrações são desenhadas para resolver problemas e abstrair um ou mais aspectos de uma implementação. Uma abstração pode entregar redução de complexidade, maior coesão, configuração facilitada, adaptação e até mesmo suprimir aquilo que não nos é relevante quando um novo padrão emerge do seu próprio uso.
Hoje o debate é sobre o EasyNetQ, uma abstração de muito sucesso aqui na comunidade .NET. Conta hoje com 8.6 milhões de downloads no nuget.org (link), enquanto o provider nativo RabbitMQ.Client possui seus 53 milhões (link). É um número surpreendente, visto que a abstração depende do provider nativo.
Embora eu prefira tratar desse assunto “dentro de casa” com alunos, evitando assim a exposição da crítica, e principalmente a taxação de estar “cagando regra” por aí. Acho que é importante trazer o tema para a pauta aqui no gaGO.io.
Entenda, “dentro de casa”, a discussão fica mais fácil, eu consigo demonstrar claramente questões internas e cases de insucesso e misconception causados pela falta de experiência com o RabbitMQ.Client e com RabbitMQ em si, que passam a ganhar proporções maiores quando o primeiro e único contato com o RabbitMQ acontece via uma abstração.
Não há nada de errado com o uso de abstrações. Mas não podemos desconsiderar que uma abstração é uma releitura da tecnologia.
Como qualquer releitura possui o viés que o autor resolveu dar ao projeto.
Exclusivo para Alunos
RECOMENDAÇÃO
Público:
- Alunos do Docker Definitivo
- Alunos da Masterclass RabbitMQ para aplicações .NET
Se é seu primeiro contato com RabbitMQ, não use absolutamente nenhuma abstração. Use o provider nativo, só. Até você se sentir familiar com RabbitMQ use apenas o provider padrão, não use abstrações.
Não importa se você precisa de SAGA ou qualquer outro pattern entregue por uma abstração.
Se você precisa de algo avançado, como SAGA, você já deveria estar confortável com RabbitMQ e o provider nativo primeiro, portanto, não use RabbitMQ agora nessa demanda porque você não está confortável e portanto corre sérios riscos. Suas primeiras implementações devem ser necessariamente com o provider nativo em cenários que te darão conforto. Não pule etapas.
As abstrações são nocivas ao aprendizado
Abstrações são boas, desde que você saiba o que está fazendo. Desde que você concorde com a abstração. E é aqui que os novatos pecam. Ter o primeiro contato com uma tecnologia via uma abstração, em um momento em que ainda não se tem muita certeza e confiança sobre a tecnologia, sobre como as coisas funcionam, tem enorme potencial de gerar entendimentos errados e confusão.
O que parecia simplificar, sacaneia todo o entendimento de como as coisas de fato funcionam. São expectativas frustradas, seja porque a abstração faz algo a mais, algo a menos ou simplesmente diferente.
Até suas pesquisas no google são ineficientes se você aprende termos que não são os corretos. Inclusive acredito que possa escrever só sobre isso. Tem muita coisa a respeito de estratégia de estudo que faz sentido trazer sobre isso.
Mas como essa discussão apareceu? Deixa eu pontua 2 eventos que me trouxeram até aqui para essa discussão.
Exemplos
Não faz nem 1 mês que um aluno recém chegado à masterclass de RabbitMQ comentou:
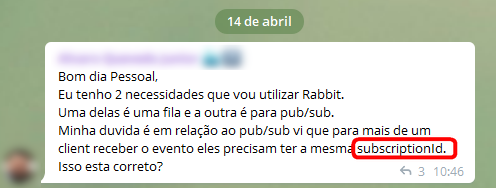
Esse questionamento parece normal, no entanto o problema é que no RabbitMQ não existe SubscriptionId. Para consumir uma fila, basta um model conectado no RabbitMQ e o nome da fila.
Já nessa semana, em um grupo público do telegram:
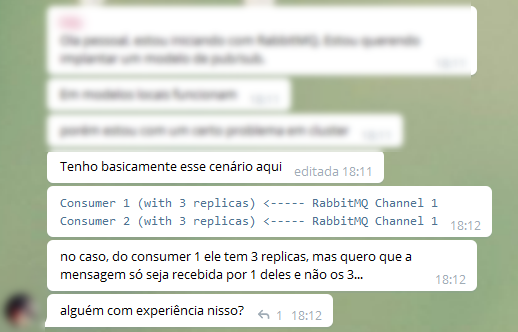
O problema é que replica para o RabbitMQ, não é um assunto relacionado ao consumo de mensagens, mas relacionando alta disponibilidade e filas que estão em diversos nós de um cluster.
O problema é deles!?
Você pode dizer: – Ah, mas o problema é deles!
Em algum nível eu até concordo, eles escolheram ir por esse caminho como primeiro contato.
Mas entendo que o óbvio também precisa ser dito e acredito que seja preciso criar esse alerta, chamar a atenção para esse padrão.
O fato é que uma pesquisa por SubscriptionId, no contexto do RabbitMQ, só trará assuntos relacionados ao EasyNetQ. E nada sobre o RabbitMQ. Porque não há esse conceito no RabbitMQ.
O problema reside quando a abstração está te empurrando em uma direção, que parece mais simples, mas carrega consigo decisões que não necessariamente você queria ou está pronto para tomar nesse primeiro contato. Nesse momento sequer dá para saber se a decisão é boa ou ruim.
Abstração: Mocinho ou Vilão
Não há uma resposta categórica: Depende do objetivo.
Se você quer aprender ASP.NET ignorando SQL, uma abstração como um ORM é bem proveitosa, pois abstrai um conhecimento periférico adicional que embora seja relevante, nas faz parte do objeto de estudo.
No entanto, se você quer ser um bom profissional, saber SQL é fundamental, e não necessariamente você deve usar ADO puro, mas eu sinceramente acredito que se seu foco for compreender melhor acesso a dados, sim faz sentido usar pelo menos algumas vezes ADO puro.
O que faz uma abstração ser boa ou ruim para o aprendizado, depende do que está sendo abstraído e do objeto de estudo.
Um ORM é nocivo para quem quer entender como usar um banco de dados, da mesma forma que o EasyNetQ é nocivo para quem quer aprender RabbitMQ.
Sobre o EasyNetQ
A respeito do RabbitMQ, qualquer abstração que suprima Exchange, Routing Key e Headers, na minha opinião, é nociva tanto ao aprendizado quanto ao uso. O EasyNetQ em diversos momentos privilegia formas de uso em que não sabemos quem são as exchanges, as routing keys e os cabeçalhos das mensagens, mesmo que ofereça mecanismos para interagir com esses objetos.
Esses mecanismos estão escondidos, tanto nas interfaces, como na documentação.
Isso acontece em algumas implementações, como a de Pub/Sub, mas não acontece, por exemplo na implementação do IAdvancedBus. O que eu tenho a ressaltar aqui é a força que a documentação faz para te jogar na direção errada. Ela privilegia o envio de objetos para o broker, ignorando os principais aspectos que citei acima.
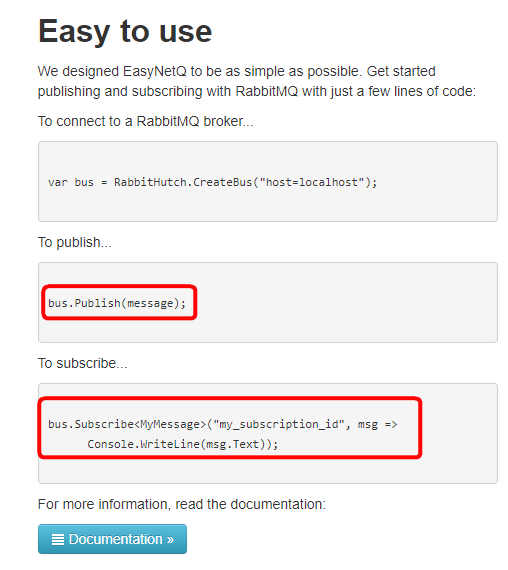
Esses 2 exemplos que marquei em vermelho, demonstram o viés usado pela implementação mais privilegiada na solução.
A publicação da mensagem deveria pelo menos ter mais 2 parâmetros: routing key e exchange, duas strings.
A forma como sua interface foi proposta faz com que ele adote convenções quando não especificamos tais detalhes. Essa é uma abordagem interessante para quem está habituado com o RabbitMQ e sabe exatamente o que precisa, mas uma estratégia ruim e nociva para o aprendizado e introdução de novos usuários. Se a interface padrão suprime dados como Routing Key, Headers e Exchange, a abstração precisa inferir e arbitrar como produzir esses dados e é aí que mora o problema. Essa abordagem padrão proposta em toda documentação do EasyNetQ, realiza a criação de filas e exchanges com base nos tipos da classe usadas como mensagem. Ele abstrai filas e exchanges.
O SubscriptionId, por exemplo, é algo que não existe no RabbitMQ, é um conceito exclusivo do EasyNetQ.
É preciso ter atenção dobrada com a terminologia, pois a documentação te empurra na direção de uma simplificação que não se traduz em simplicidade. Na meu entendimento se reflete em acoplamento e perda de funcionalidades básicas do RabbitMQ.
O que você perde ao não lidar com Exchanges?
A exchange desacopla publishers (quem publica mensagem) das filas. Ela é um mecanismo de roteamento. Cada exchange possui um tipo, e de acordo com o tipo, regras diferentes são usadas para rotear uma mensagem para uma ou mais filas.
Ignorar as exchanges
Ignorando a exchange, você não está deixando de usá-las, mas adotando uma forma que ignora suas capacidades, e a forma como é feito pelo Pub/Sub do EasyNetQ pode forçar você a:
- Ter de construir novas classes, com o único intuito de enviar o mesmo dado para diversos consumidores.
- Não conseguir realizar a distribuição de mensagens na cardinalidade de 1 x N enviando apenas 1 mensagem.
O que você perde ao não lidar com Filas?
No que diz respeito às filas, o EasyNetQ utiliza o Fully Qualified Name do tipo de mensagem como nome de fila, somado opcionalmente por uma string informada pelo usuário chamada SubscriptionId. Olha a maldita aqui.
A SubscriptionId serve para diferenciar consumer groups da mesma mensagem, pois ela é usada para diferenciar filas que recebem um mesmo tipo de mensagem.
Embora me cause estranheza, nessa parte não há muitas questões.
O que você ganha com o EasyNetQ?
- Serialização automática
- Ack Manual Automático
O que o Pub/Sub faz e como faz?
Na estratégia de Pub/Sub desse projeto, a exchange leva o Fully Qualified Name do tipo da mensagem apenas, enquanto as filas usam a mesma string somada ao SubscriptionId.
A infra de Pub/Sub produz uma exchange por Tipo de mensagem, e uma fila por Tipo de Mensagem + SubscriptionId.
Adicionalmente um bind por fila é produzido com routing key igual a #, de forma a toda mensagem daquele tipo, ser roteada para todas as filas que aceitam mensagens desse mesmo tipo.
Nessa abordagem, a razão entre Exchanges e Filas tende a ser 1 para 1, ou 1 x N onde N é cada SubscriptionId.
Conclusão
Na publicação de mensagens a documentação da abstração de pub/sub te empurra para usar exchanges do tipo topic, muitas vezes suprimindo até a routing key. As buscas por apenas publicar a mensagem, sem discriminador de exchange e routing key, tornam o entendimento do RabbitMQ frágil e passa a ser um esforço mental, lembrar dos conceitos básicos do que é uma exchange e para que serve.
O EasyNetQ usado como a documentação sugere, é um problema e um ofensor.






0 comentários