
Parece sopa de letrinhas aleatórias né? Mas isso fez algum sentido para você, e achou legal, deixa eu te contar o que fizemos aqui do lado de dentro.
Uma das demandas que tenho no curso de RabbitMQ para Aplicações .NET, é trazer conforto e clareza sobre o desenvolvimento de fluxos assíncronos com mensageria. É primordial para desenvolver um bom trabalho, compreender como cada detalhe se comporta, e quais são os impactos de cada decisão. Porque não basta mandar uma mensagem e delegar a culpa para o client, o provider, a abstração ou até mesmo o RabbitMQ.
Isso não funciona.
No fim do dia, quando algo errado acontece, é você quem tem de descobrir o que aconteceu, é você quem tem de dar uma solução. E como tem muita gente tendo sucesso com as mesmíssimas tecnologias, fica óbvio que o problema não é a ferramenta, mas algo entre a cadeira e o teclado 😳.
Quando eu faço minhas considerações sobre as abstrações para RabbitMQ e Mensageria em geral, estou me referindo a detalhes nos:
- publishers
- exchanges
- filas
- consumers
que impactam:
- na resiliência
- na velocidade com que conseguimos atender mensagens
- no comportamento do client
Então você precisa apertar 2 parafusos para conseguir ter resiliência no armazenamento. Outros 2 parafusos para obter resiliência no consumo. Outros 2 para ter resiliência na publicação. Outro para ter a garantia de roteamento.
Cada parâmetro afeta em uma parte diferente. Seja no consumer, no publisher, nas filas e exchanges.
Seria ótimo se pudéssemos simplesmente ignorar essa complexidade, o outro escondido está exatamente nesses detalhes.
Com tantas possibilidades qualquer abstração que não permita a escolha da estratégia, está nos privando de tomar a decisão.
É exatamente aqui que mora o perigo.
RabbitMQ Professional Consumer
Nessa jornada de clareza, eu produzo alguns projetos que ficam hospedados em um ORG do GitHub exclusivo. E no início de 2021 eu criei um projeto chamado RabbitMQProfessionalConsumer porque eu havia identificado que a galera estava achando que o código que usava nas demonstrações parecia simples demais. Ledo engano.
Eu percebi que no dia-a-dia a galera estava complicando demais as coisas, e quando eu olhava código encontrava complexidade desnecessária, acoplamentos desnecessários. E pior: nenhuma separação entre código de infraestrutura e código de negócio.
Ou seja: Eles não estavam criando suas abstrações. E portanto estavam tendo muito mais trabalho do que de fato deveriam.
Eu percebi esse fenômeno em alguns poucos casos, mas foi o suficiente para pensar:
Bom, se eles estão passando por isso e sequer estão expressando essa dificuldade, então descobrimos um canto cego. Eles nem sabem que podem fazer diferente.
E porque abstrações são tão importantes?
Porque cada projeto tem demandas diferentes. Enquanto usar uma library que não te dá a opção de definir as estratégias é algo limitador para a adoção em uma empresa, já a abstração é feita sob medida para o projeto, atendendo aos interesses do projeto. O que permite fazer otimização específica para o projeto.
Depois tem toda aquela história de promover abstrações locais para regionais, depois para globais, isso é papo para outro dia.
Aqui eu aproveitei o RabbitMQ Professional Consumer para fazer esse trabalho de demonstrar o uso mais profissional, simulando contextos de negócio. No dia 9/FEV eu concluí a migração para .NET 6. E desde então tenho trabalhado em cases de performance e observabilidade.
Observabilidade
O ponto mais crucial de um serviço é expor para seus mantenedores o que está acontecendo. O ponto é que quando você tem um fluxo que se baseia em múltiplas chamadas, encadeadas serviço-a-serviço, em um fluxo muito grande. Isso se torna bem complexo de se lidar. Afinal, e agora? Onde foi parar essa mensagem? E o que ela demandou para os outros serviços?
Como eu estou às vésperas da produção do nosso conteúdo sobre Event Driven Architecture, é importantíssimo estar com esse projeto complexo para que eu possa usá-lo como pano de fundo.
As abstrações que vemos ali consolidam trabalho de semanas, e o resultado é que em alguns poucos minutos transformamos um serviço comum em um consumidor de filas, sem modificar nada no serviço. Tem algumas premissas para isso. Mas se você já trabalha com agnostic services, é exatamente isso mesmo: Zero mudança.
Então para dar vida ao contexto de EDA eu preciso conseguir rastrear com precisão cada passo de uma mensagem, e ver com clareza sua propagação serviço-a-serviço, já que estamos falando de baixo acoplamento, o que torna a rastreabilidade desafiadora sem ferramentas adequadas.
Vamos entender o papel de cada elemento:
Open Telemetry
É a fusão de 2 projetos (Opentracing e Opencensus) e tem o papel de uniformizar e unificar as implementações de distributed tracing. Ele é configurado no ASP .NET e a partir daí ele, junto com a infra de Diagnostics do .NET interage enviando dados para um backend que aceita o protocolo do OpenTelemetry.
Jaeger
Jaeger é esse backend especializado em Distributed Tracing, com ele visualizamos o fluxo.
RabbitMQ
esse nem preciso falar muito, é nosso Message Broker
Prometheus
Uma das coisas legais do RabbitMQ é que ele já se integra com o Prometheus, que é um metric server. O papel dele é armazenar métricas, oferecer formas de fazer consultas para definir estatísticas e com isso tomar decisões baseadas em eventos em uma janela de tempo.
Grafana
Por fim o Grafana vai mostrar os dados do prometheus, que no nosso caso representa o estado do nosso RabbitMQ, agora monitorando o RabbitMQ e não mais fazendo insert em SQL Server como era feito no exemplo do RabbitMQ-Walkthrough-v1.
Aliás aquilo de fazer insert no SQL Server ainda durante a publicação, só servia para poder produzir o dado mais tarde, durante a execução. Era apenas para conseguir gerar a métrica de tempo até a execução. Não existe aplicação no mundo real para essa abordagem. O fluxo até que sim, mas a intenção (fornecer dados em um gráfico) não.
O resultado
Tudo começa com nossa aplicação de demonstração. Um cálculo remoto, usando RPC.
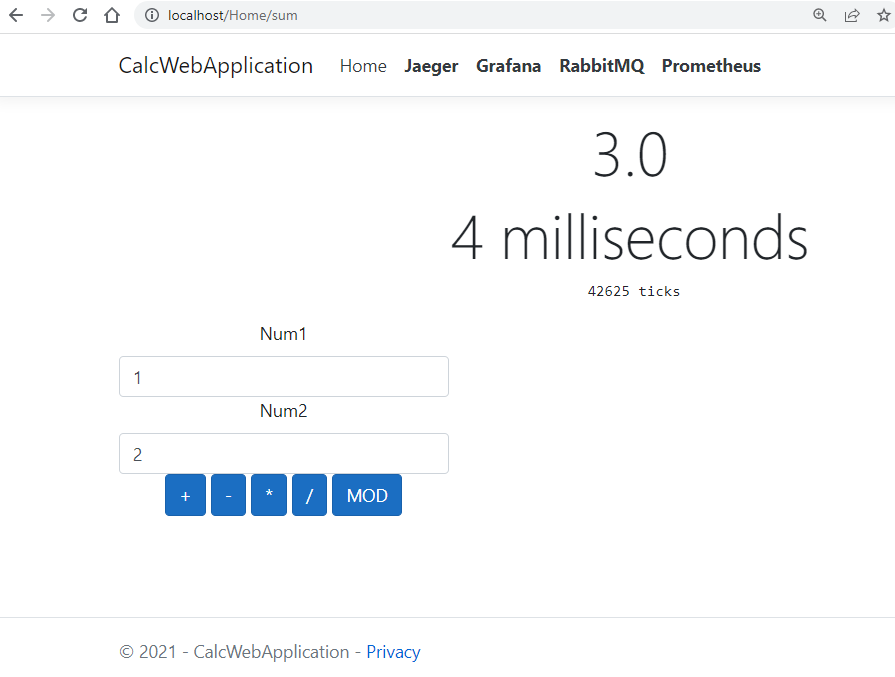
Esse foi outro assunto que percebi gerar ansiedade aqui dentro. RPC com AMQP é usado quando você não só tem uma mensagem de request, mas também precisa de um responde.
Não é aconselhado, porque você joga fora a capacidade de obter alguns benefícios, mas é o que é. Alguns precisam disso de fato.
Aqui temos o Jaeger, mostrando todas as operações realizadas.
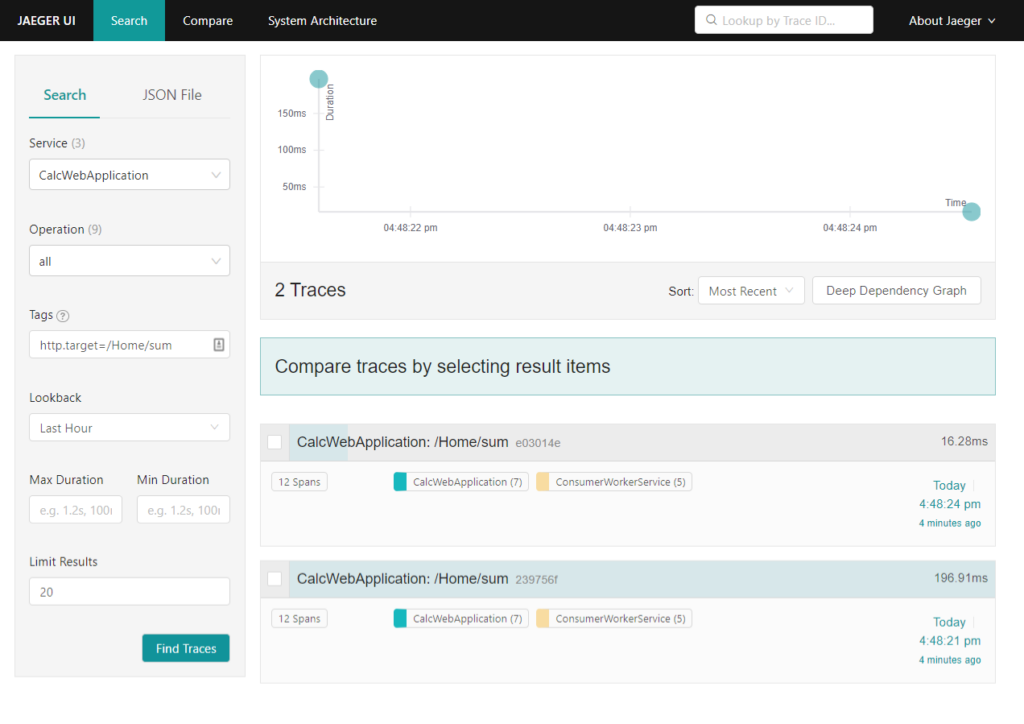
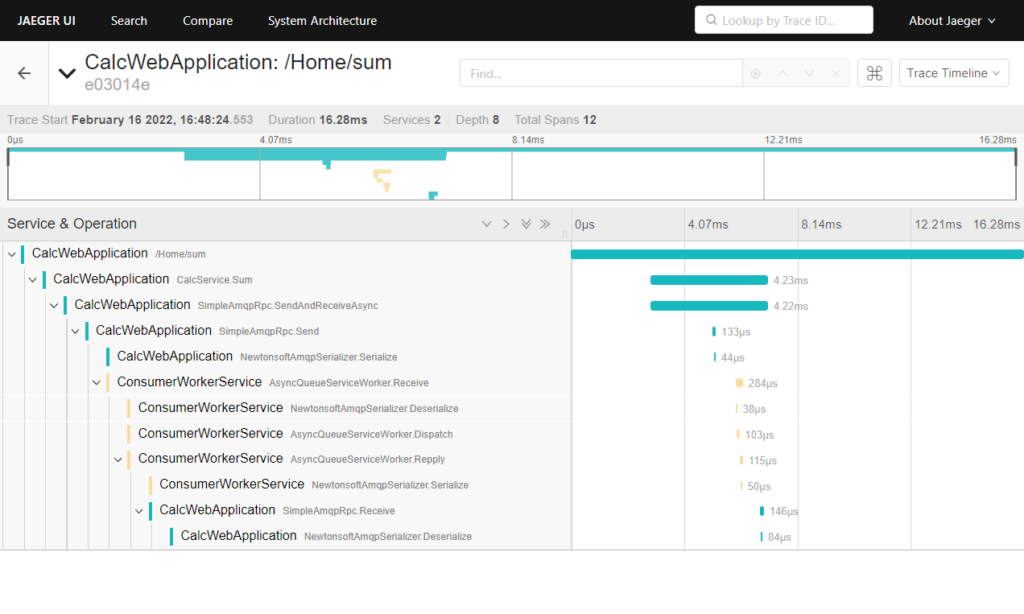
Esse fluxo, agora rastreável consegue nos dizer passo-a-passo o que aconteceu.
Desde da saída do CalcWebApplication até a chegada ao ConsumerWorkerService e sua volta à CalcWebApplication, em 4ms, aproximadamente de 1/250 de segundo.
E para dar vida às métricas do RabbitMQ temos um board do Grafana que é alimentado pelo Prometheus, que por sua vez é alimentado diretamente pelo RabbitMQ.
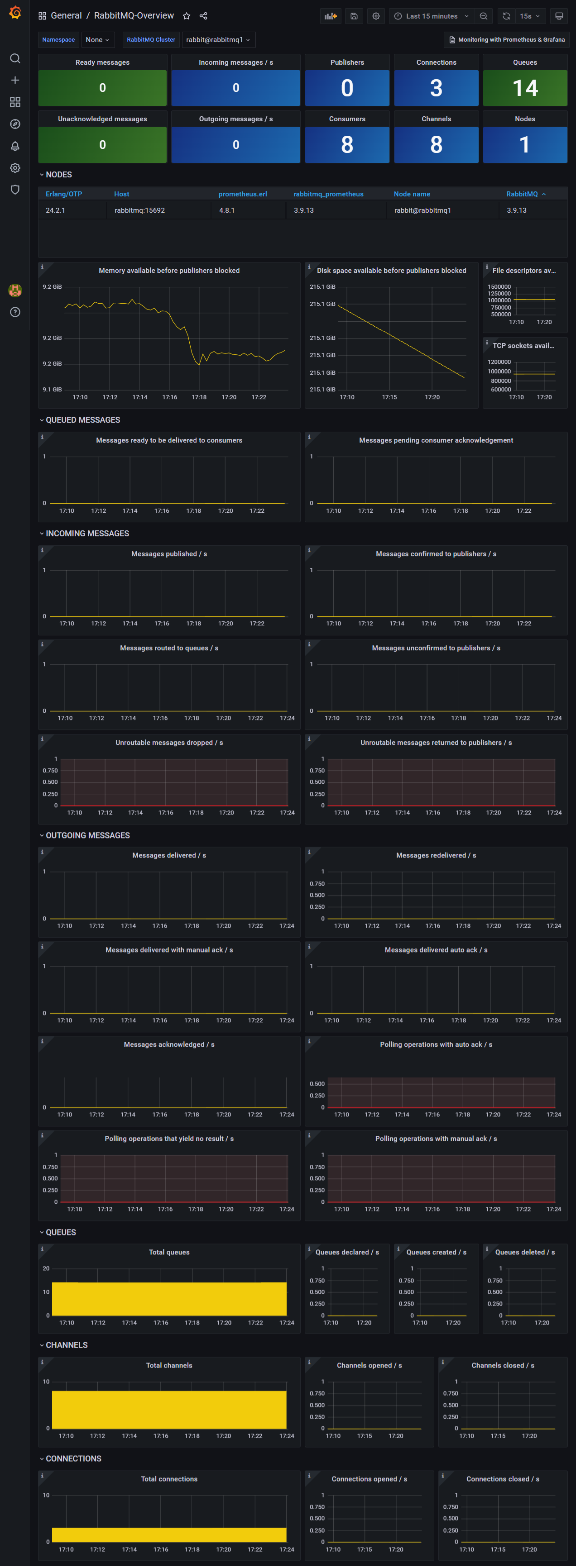
Assim fica mais fácil, correto?
E claro que aqui eu não coloquei carga nenhuma até porque eu subi esse ambiente só para gerar esses prints.
Daqui pra frente basta enriquecer os cenários, mas a visualização e toda a configuração de infraestrutura está coordenada. Aliás, instrumentar o código para fazer a correlação de requests entre microsserviços com mensageria com .NET é um conteúdo nulo. Não há.
Talvez em breve eu publique algo sobre isso. Em resumo, eu tive de fazer alguns testes e na base da tentativa-e-erro, descobrir como correlacionar esses processamentos para conseguir fazer com que pareçam parte de uma grande transação ao invés de chamadas soltas.
Como resultado conseguimos não só ver o fluxo entre serviços, bem como resposta, mas também temos exemplo de carga usando K6 em um cenário de webhooks com RingBuffer.
E assim fico por aqui.
Deixe nos comentários o que você achou e o que você quer ver no próximo post!






0 comentários