
A Digital Ocean é um Cloud Provider famoso e muito usado no mundo todo, mas nem por isso deixaram de cometer o amadorismo de usar bancos de dados como filas. E pior, para atender um throughput pífio! Conclusão: Mesmo sendo owners de infraestrutura, ou seja, com dinheiro infinito para infra, sentiram na pele a dor de ter de aguentar um banco de dados com 15 mil conexões. Com RabbitMQ, não passou de 100!
Esse é mais uma demonstração que em casa de ferreiro o espeto é de pau.
Eles sentiram a dor, mesmo com dinheiro infinito para infra. Agora imagina você, ou melhor, seu projeto, que está avaliando custo de cloud semana-a-semana?
A D.O. fez um post, e vamos narrar o que descobrimos com essa implantação incrível de RabbitMQ.
Quem é a Digital Ocean?
A Digital Ocean é um cloud provider que fornece droplets, VPS sobre KVM. Agora com uma pegada mais PaaS, mas a ideia é ser um meio termo enter o Heroku e um grande Cloud Provider.
Segundo a datanyze, esses são os competidores e a quantidade de sites públicos hospedados/catalogados em cada um.
- GoDaddy 2.575.281
- AWS 1.688.808
- Google 1.261.009
- 1&1 Hosting 936.171
- Hostgator 823.770
- BlueHost 531.122
- Hetzner 393.102
- DigitalOcean 349,154
- Liquidweb 341.977
https://www.datanyze.com/market-share/web-hosting–22/digitalocean-market-share
Isso dá a entender a dimensão da Digital Ocean. Mas também não podemos seguir piamente, porque não encontramos Azure entre os concorrentes, o que me parece esquisito. Então fica como uma informação adicional sem muita relevância estatística.
O case
Em uma publicação de Janeiro de 2020 encontramos o título (traduzido) “De 15.000 conexões de banco de dados para menos de 100: o conto da dívida tecnológica da DigitalOcean”.
O post narra que eles cuidam dos próprios servidores e infra, e narra também que “A DigitalOcean é obcecada pela simplicidade desde o início” e continua “É um dos nossos valores fundamentais: Buscar soluções simples e elegantes . Isso se aplica não apenas aos nossos produtos, mas também às nossas decisões técnicas.”.
Pois bem, a gente vai ver mais à frente no texto que eles adotaram uma fila em banco de dados. Ou seja, ignoraram RabbitMQ e qualquer tipo profissional de mensageria e optaram pelo achavam ser o feijão com arroz, sem saber que era na verdade um belo prato de bosta.
Em resumo, eles tinham um banco MySQL que servia de controle de estado e controle de processamento compartilhado. Alguém fazia um insert aqui, outro fazia pooling acolá e pronto, o fluxo andava.
Esse desenho é um desenho super comum em empresas pequenas. Desenvolvedores no início de carreira são muito propensos a desenhar soluções assim. Isso é justificável pela ausência de cases mais robustos e pela falta de necessidade de algo mais estruturado.
Muitas empresas perduram com esse desenho e todo o seu time simplesmente acha que aumentar o custo com infraestrutura é a única solução.
Na maioria das vezes soluções como RabbitMQ são vistas como paliativas ou quebra-galho, ou ainda que não resolve esse tipo de cenário. Aqui no Brasil, todas as vezes em que eu trouxe RabbitMQ para projetos .NET, não houve sequer 1 caso em que eu não encontrasse objeções gigantescas sobre a necessidade de uma ferramenta além do ASP.NET e do Banco de Dados.
Redis e RabbitMQ, que é a dobradinha mais comum aqui nos meus cases de restruturação, sempre fizeram desenvolvedores .NET se revirarem em suas cadeiras! Pode parecer birra, ou preconceito dos caras, mas não é. Na verdade o mundo pela ótica deles só tem essas duas coisas, aplicação e banco. É muito comum você conseguir passar muitos anos só vendo isso. E nesse contexto tudo se resolve com mais infra (vertical) e muito pouco se pensa em horizontalizar uma arquitetura.
Claro que com o tempo e principalmente com o mercado amadurecendo e vendo o poder dessas soluções, essas ferramentas passam a ser menos “disruptivas” , e ficam cada vez mais familiares, deixando de ser bicho-papão para fazerem parte do dia-a-dia.
O ponto principal é que App e Banco parece à prova de overengineering e na verdade o que vemos é que em boa parte dos casos se traduz em:
- Custos desnecessários
- Desperdício de processamento
- Ineficiência operacional
Ou seja, se gasta mais para fazer menos.
Aqui nesse post da Digital Ocean vemos exatamente esse estereótipo que, no caso deles foi sanado com o RabbitMQ.
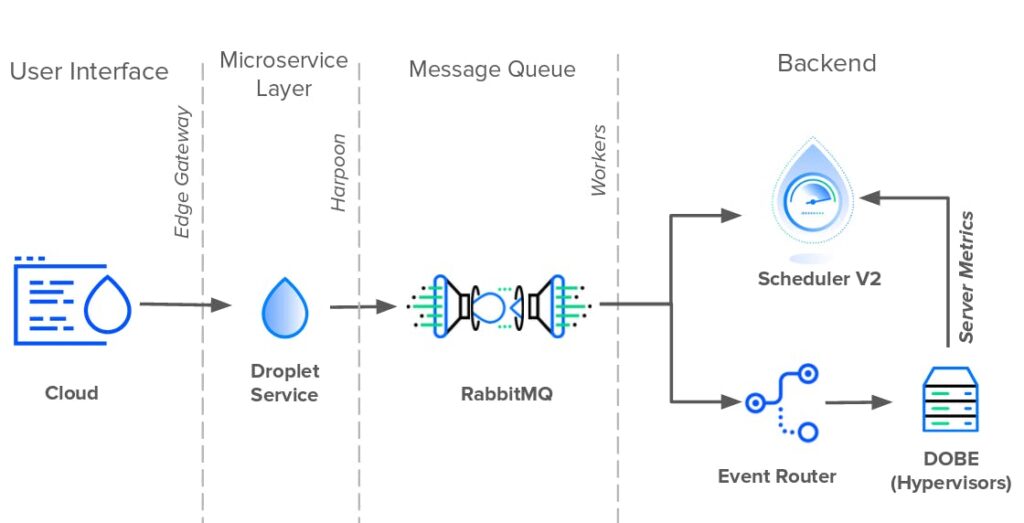
Eles relatam que fizeram diversos movimentos com Microsserviço, gRPC, trocaram perl por golang mas segundo palavras deles: “No entanto, todos os caminhos ainda levavam a esse banco de dados MySQL”.
Para acompanhar o aumento da demanda do Droplet, estávamos adicionando mais e mais servidores para lidar com o tráfego. Cada novo hypervisor significava outra conexão persistente com o banco de dados. No início de 2016, o banco de dados tinha mais de 15.000 conexões diretas, cada uma consultando novos eventos a cada um a cinco segundos.
Se isso não bastasse, a consulta SQL que cada hipervisor usava para buscar novos eventos de Droplet também cresceu em complexidade. Tornou-se um colosso com mais de 150 linhas e se juntou em 18 mesas.
Era tão impressionante quanto precário e difícil de manter.
A solução
Com esse cenário eles definiram o que era necessário ser realizado.
Sem surpresa, foi por volta desse período que as rachaduras começaram a aparecer. Um único ponto de falha com milhares de dependências agarrando recursos compartilhados inevitavelmente levou a períodos de caos. Bloqueios de tabela e backlogs de consulta levaram a interrupções e quedas de desempenho.
E devido ao acoplamento apertado no sistema, não havia uma solução clara ou simples para resolver os problemas. Cloud, Scheduler e DOBE serviram como gargalos. A correção de apenas um ou dois componentes apenas transferiria a carga para os gargalos restantes. Então, depois de muita deliberação, a equipe de engenharia apresentou um plano de três frentes para corrigir a situação:
Diminua o número de conexões diretas no banco de dados
Refatorar o algoritmo de classificação do Scheduler para melhorar a disponibilidade
Absolver o banco de dados de suas responsabilidades na fila de mensagens
O problema que eles relatam não está relacionado a ser um grande player ou um grande fornecedor, dá para ver pela lista e como ele está posicionado que ele é mediano. Nem um pequenininho, mas também está longe de ser um top player do seu mercado.
O ponto é que a natureza desse tipo de solução, usando banco de dados para essa finalidade, esgarça a capacidade de oferecer um bom serviço.
O resultado é enxugar gelo, tentar resolver o que na verdade precisa ser rearquitetado.
Aumentar o poder de processamento das instâncias de banco é viável quando se é um cloud provider, mas até nesses casos, de dinheiro infinito, há um limite. O limite aqui não é o custo, mas o transtorno e o fato de injetar mais dinheiro não ser o suficiente para evitar as crises.
400.000 novos registros por dia e 20 atualizações por segundo
Esse número pífio era o tamanho do problema que demandara tanto esforço. Erros simples de corrigir, erros simples em um desenho arquitetural adequado levando em conta as 3 premissas:
Pense Grande
Comece Pequeno
Evolua Rapidamente
Levou 1 ano até eles conseguirem tirar o acoplamento direto entre as aplicações e o banco de dados no quesito mensageria. Isso quer dizer que ainda usavam banco, mas haviam trocado as operações diretas e o código duplicado, por um broker, que continuava usando o banco, mas era o único mediador entre essa parte do banco e as aplicações.
Essa estratégia de estrangulamento visa centralização para depois fazer o takeover, possibilitando uma mudança, agora centralizada.
De fato aboliram as filas em banco de dados, adotando RabbitMQ como plataforma de mensageria.
Foi acertado esperar tanto?
Antes tarde do que nunca. Como eles são o próprio cloud provider, acredito que seja difícil eles dimensionarem os gastos antigos para conseguirem comparar com o novo.
Mas o principal ponto é que conseguimos consumir menos o banco, deixando ele mais livre.
Por outro lado a adoção de RabbitMQ também permite aceitar picos de demanda que não se propagam com efeito dominó. Se não tem worker para processar, a mensagem vai demorar um pouquinho mais para ser recebida porque ficará mais tempo na fila.
Se esse mesmo ambiente puder processar mais, basta plugar algum mecanismo de autoscalling definindo o limite de processamento. Esse limite é a trava de segurança para garantir que a propagação de caos não ocorra.
Por fim, não só conseguimos ser mais eficientes, conseguimos entregar paz, e tranquilidade para serviços críticos, garantindo que eles serão executados e senão… também serão!!!! hahahahah Não tem senão! Essa é a mágica da segurança da adoção de soluções eficientes.
Se eles fizeram certo em esperar tanto tempo? Olha sinceramente eu acredito que pudesse ter sido feito direito desde o início. Meu primeiro case com RabbitMQ foi em 2013, na iMusica.
Mas entendo que a mentalidade ali era de que banco + app era o suficiente e todo o resto era overengineering.
Estou começando um projeto, RabbitMQ faz sentido pra mim?
Bom Redis e RabbitMQ, aqui nos meus projetos e clientes estão na mesma categoria de Bancos de Dados. Entre maior que um simples CRUD, e menor que uma rede social: faz sentido!
O principal ponto é que conseguimos entregar 5 benefícios:
- disponibilidade
- eficiência
- resiliência
- confiabilidade
- escalabilidade
Muitas vezes eu só quero 1 desses 5 benefícios.
Em geral o primeiro que busco é disponibilidade.
Ou seja: me deixe fazer deploy qualquer hora!!! Me deixa fazer um rollout dessa instância sem dor de cabeça.
O segundo fica empatado entre resiliência, confiabilidade e eficiência.
Não é muito comum em projetos pequenos você conseguir mais do que 2 benefícios desses. Já em projetos grandes você consegue extrair todos os 5 benefícios.
Então se for maior que um CRUD e menor que uma Rede Social… muito provavelmente há como reduzir seus custos com RabbitMQ.
É por isso que eu falo tanto da solução, que eu formo profissionais que usam RabbitMQ em seus projetos.
Vou deixar aqui o case da Leo Madeiras, que usou RabbitMQ para simplificar um processo de longa duração que demandava um problema de usabilidade na solução web deles. Esse é um case de alunos daqui.






0 comentários