
No finalzinho de 2017 eu falei de um projeto chamado youtube downloader, um projeto de exemplo, experimental, que emprega o uso de filas para fazer todo o processo de download e encoding de mídias, a partir do youtube. Mesmo tendo o propósito de exclusivamente falar de RabbitMQ em um pipeline de processamento, natural desse tipo de tarefa, a temática de download do youtube é controversa e possui implicações em direitos autorais. Enfim a proposta do projeto não é infringir regras, leis ou direitos autorais, apenas exemplificar em um cenário clean, como otimizar o uso de filas com pipelines.
Para entender o projeto, é preciso lembrar que:
- Download de mídias é um processo lento, pode levar segundos, minutos ou até horas, dependendo do tamanho, e formato do arquivo.
- O processo de encoding (transformar de um formato em outro) é um processamento lento e leva também muito tempo para processar, se comparado a um simples insert em banco.
- Com processamentos lentos (citados acima) atender a uma grande quantidade de requisições é uma tarefa complexa, pois além de throttling, geramos contenção de processamento.
- Precisamos escalar horizontalmente nossos workers para garantir processamento de tudo o que está sendo solicitado.
- Quando a capacidade de processamento alcança seu limite, é necessário ainda ter uma interface responsiva que consiga receber as requisições e os pedidos de download.
Essas são as características que fazem desse projeto um excelente playground para empregarmos mensageria e muitas outras tecnologias.
Arquitetura, topologia e responsabilidades
É importante ressaltar que esse projeto não tem a ambição de der um seed project para suas implementações de mensageria. Para isso embarquei um subset do Oragon Architecture (somente o pipeline de processamento com RabbitMQ) nele, fazendo customizações para eliminar algumas dependências adicionais e simplificar a entrega. A intenção é entregar 100% do código para que não haja algo escondido em um pacotes nuget externos. O projeto tem o objetivo de entregar o processamento necessário para baixar e encodar mídia. Como resultado da entregar downloads de vídeo e audio, e a capacidade de reproduzir os vídeos direto em sua interface.
UI
Uma interface web, baseada em angular 1, contendo apenas 1 página (não é um SPA, é uma aplicação de 1 página mesmo pode chamar de UPA – Unique page application).
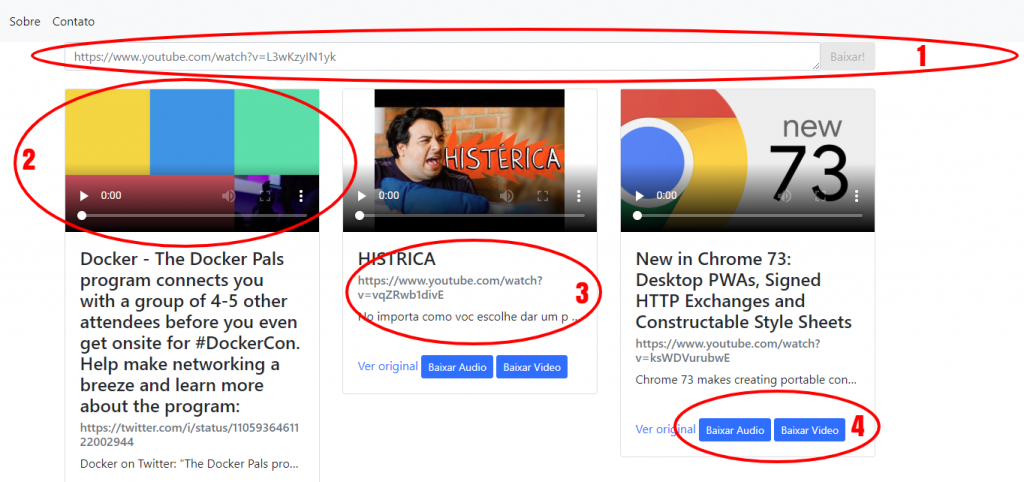
Essa UI tem 4 objetivos claros:
- Permitir informar novas urls de vídeo para que os downloads possam ser processados, suporta Twitter, Facebook e Youtube.
- Permitir a visualização do vídeo depois de processado, enquanto não, exibir sua capa.
- Exibir os metadados básicos do vídeo.
- Permitir download de audio e vídeo.
- Disponibilizar tudo isso em uma galeria simples.
Consiste em:
- Um projeto ASP.NET Core usando MVC (com Razor) e angular 1.
- Ao solicitar o download, enviar uma mensagem para o ponto de partida de um pipeline de filas.
- Ler a cada X segundos, dados do Redis para exibir a galeria.
Worker
Console .NET Core, que:
- Hospeda os serviços declarados no spring de forma dinâmica.
Serviços
Divididos em Serviços e Contratos (interfaces e DTO’s) responsáveis pelo processamento.
Data Service
O Data Service encapsula as operações que interagem com o MongoDB e Redis, como inserts e updates no MongoDB, e repopular o cache do Redis.
O processamento das mensagens foi dividida em etapas de um pipeline:
EntryPointRegisterPipelineActivity
É o primeiro step do pipeline, ele recebe a mensagem de solicitação, aplica uma validação básica e toma a decisão se descarta a mensagem ou não.
Ao conseguir realizar sua tarefa, chama o Data Service para realizar o insert no MongoDB.
MetadataDiscoveryPipelineActivity
Realiza o download dos metadados, realizando 4 chamadas ao youtube-dl.
Ao conseguir realizar sua tarefa, chama o Data Service para realizar o update no MongoDB.
MediaDownloaderPipelineActivity
Realiza o download/encoding dos 2 formatos (audio e vídeo) em um path temporário.
Ao conseguir realizar sua tarefa, chama o Data Service para realizar o update no MongoDB.
S3MediaUploaderPipelineActivity
Realiza o upload das duas mídias para um bucket fake do S3 hospedado no docker com Minio.
Ao conseguir realizar sua tarefa, chama o Data Service para realizar o update no MongoDB.
CleanupPipelineActivity
Remove os arquivos temporários do file system (somente os arquivos pertinentes a uma mensagem).
Pipeline Activities
Cada pipeline activity, não interage com RabbitMQ, seu papel é receber uma mensagem, se precisar enriquecê-la, e solicitar a alteração no MongoDB. A cada insert ou update no MongoDB, uma chamada ao método de rebuild do cache é realizada para atualizar o Redis.
A infraestrutura de pipelines permite encadear diversos steps, configurando a quantidade de threads em cada um dos steps do pipeline. Viabilizando ainda a escala não só no processo, mas em diversos processos.
O pipeline é responsável por conectar seu método de negócio à fila, evitando a necessidade de escrever esse conector. Regras e convenções são determinadas para que esse modelo funcione.
- O pipeline é definido por uma lista de steps
- Cada step possui:
- conexão com RabbitMQ
- Nome
- Nome da exchange, e nomes de filas
- Uma instância de um objeto qualquer (quem executará a tarefa de negócio)
- E uma string que informa o nome do método que realizará o processamento de negócio.
- Uma instância de um controlador de concorrência (tem o papel de definir quantos workers são necessários)
- Ao iniciar o mecanismo, o próprio mecanismo se encarrega de criar todas as filas e exchanges.
- Para cada step do pipeline são criados workers que processarão as mensagens das filas:
- O worker consome uma mensagem
- Com AutoAck desabilitado
- Entrega a mensagem para a instância de negócio, no método informado.
- Essa entrega acontece dentro de um try/catch.
- Caso o resultado seja de sucesso, envia a mensagem para a próxima etapa (fila do próximo step) e confirma a exclusão da mensagem com o ack manual.
- Caso dê erro, ele envia a mensagem para uma fila de erro (isso é configurável).
- Aguarda próxima mensagem em sua fila.
O pipeline é melhor descrito no post abaixo:
Pra que isso tudo?
Esse é um exemplo de 5 steps, há exemplos com muitos mais passos, e implantações com diversos pipelines.
Configurar isso manualmente tende a ser uma tarefa lenta que depende de atenção demais e possui muitas chances e oportunidades para erro humano. A automação me garante que a configuração está sendo aplicada corretamente.
O pipeline me permite não me preocupar com aspectos não funcionais e me dando liberdade para que meu step não tenha responsabilidades demais.
Embora aqui vejamos o pipeline embarcado em um projeto, como código de infraestrutura, na prática é parte de uma library referenciada via nuget. Isso de fato simplifica a vida. No dia-a-dia, consiste em adicionar um pacote nuget, e realizar as configurações para plugar meu método em uma fila, como membro de um pipeline mais complexo. Isso reduz muito o escopo de desenvolvimento e me dá flexibilidade para tomar decisões o mais tarde possível.
Esse pipeline possui algumas convenções. Elas não suportam TODOS os cenários de uso, mas suportam vários como:
- Todo step recebe um objeto que está na fila, já como uma instância de um DTO.
- Quando um step retorna algo diferente de void, temos:
- Se for uma lista, cada elemento da lista é publicado no próximo step (Ex: recebeu pedido, quebrou em itens do pedido)
- Quando o retorno não é uma lista, então essa nova instância é usada como mensagem para a próxima etapa (Ex: Entra pedido, sai ordem de compra)
- Se o retorno for void, então a mesma mensagem que foi processada pelo step atual será usada no próximo step.
- Quando um step falha, posso enviar a mensagem para a fila de erro, e não processar mais, posso reprocessar a mensagem por x vezes ou ainda posso devolver para a fila para que outro worker pegue-a.
Nesse caso, eliminei algumas implementações desses padrões para simplificar o entendimento, mas no projeto original esses comportamentos estão presentes.
O que não suporta e já sabemos que seria importante suportar: Desvios de fluxo e omissão de etapa. Não há infraestrutura de regras para isso, o pipeline é linear. Sequencial, sem desvios de fluxo ou supressão de algum step.
Esse tipo de abstração pode ser extensivamente testado de forma a garantir qualidade e resiliência em sua demanda de gerenciar esse ciclo de vida. Embora eu ainda esteja poluindo meu código com o update no MongoDB, como pode ver abaixo, não há gestão de filas, não há criação de workers, nada disso visível aos olhos. Essa implementação está na minha camada de infraestrutura e eu simplesmente conecto ao negócio. Isso me dá a flexibilidade de ser completamente agnóstico enquanto estou escrevendo meus serviços.
Além disso, permite, com extrema confiabilidade, que um step seja criado apenas com a classe abaixo.
Essa é uma classe real, 100% do arquivo está aqui.
using Minio;
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading.Tasks;
namespace DevWeek.Services.Downloader
{
public class S3MediaUploaderPipelineActivity : IPipelineActivity
{
private readonly MinioClient minio;
private readonly DataService dataService;
public string AudioBucketName { get; set; }
public string VideoBucketName { get; set; }
public S3MediaUploaderPipelineActivity(MinioClient minio, DataService dataService)
{
this.dataService = dataService;
this.minio = minio;
}
public async Task ExecuteAsync(DownloadContext context)
{
string audioFileName = System.IO.Path.GetFileName(context.AudioOutputFilePath);
await minio.PutObjectAsync(this.AudioBucketName, audioFileName, context.AudioOutputFilePath);
string videoFileName = System.IO.Path.GetFileName(context.VideoOutputFilePath);
await minio.PutObjectAsync(this.VideoBucketName, videoFileName, context.VideoOutputFilePath);
await this.dataService.Update(context.Download.Id, (update) =>
update.Combine(new[] {
update.Set(it => it.AudioDownloadUrl, $"/api/media/{this.AudioBucketName}/download/{audioFileName}"),
update.Set(it => it.VideoDownloadUrl, $"/api/media/{this.VideoBucketName}/download/{videoFileName}"),
update.Set(it => it.PlayUrl, $"/api/media/{this.VideoBucketName}/stream/{videoFileName}"),
update.Set(it => it.Finished, DateTime.Now)
})
);
}
}
}
Note que relevante, de fato, temos o método ExecuteAsync, com 12 linhas.
Com:
2 chamadas ao S3
1 chamada ao Data Service
O pipeline inteiro é descrito por esse XML
<object name="IngestionPipeline" type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedStateMachine, DevWeek.Services" >
<property name="QueueClient" ref="Local:RabbitMQClient" />
<property name="CreateZombieQueues" value="true" />
<property name="MessageRejectionHandler" >
<object type="DevWeek.Architecture.MessageQueuing.MessageDeserializationRejectionHandler, DevWeek.Services">
<property name="RabbitMQClient" ref="Local:RabbitMQClient"/>
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="RejectionRoutingKey" value="MessageRejected" />
</object>
</property>
<property name="Transitions">
<list element-type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="DownloadRequest" />
<property name="Destination" value="RequestStored" />
<property name="LogicalQueueName" value="RequestStore" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service" >
<object type="DevWeek.Services.Downloader.EntryPointRegisterPipelineActivity, DevWeek.Services" autowire="constructor"></object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="RequestStored" />
<property name="Destination" value="MetadataDownloaded" />
<property name="LogicalQueueName" value="MetadataDownloader" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service">
<object type="DevWeek.Services.Downloader.MetadataDiscoveryPipelineActivity, DevWeek.Services" autowire="constructor"></object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="MetadataDownloaded" />
<property name="Destination" value="MediaDownloaded" />
<property name="LogicalQueueName" value="MediaDownloader" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service">
<object type="DevWeek.Services.Downloader.MediaDownloaderPipelineActivity, DevWeek.Services" autowire="constructor">
<property name="SharedPath" value="/shared/" />
<property name="MetadataExtractors">
<list element-type="DevWeek.Services.Downloader.MediaDownloader.IMetadataExtractor, DevWeek.Services">
<object type="DevWeek.Services.Downloader.MediaDownloader.GenericOutputMetadataExtractor, DevWeek.Services">
<property name="StartsWith" value="[download] " />
<property name="EndsWith" value=" has already been downloaded and merged" />
</object>
<object type="DevWeek.Services.Downloader.MediaDownloader.GenericOutputMetadataExtractor, DevWeek.Services">
<property name="StartsWith">
<value><![CDATA[[ffmpeg] Merging formats into "]]></value>
</property>
<property name="EndsWith">
<value><![CDATA["]]></value>
</property>
</object>
<object type="DevWeek.Services.Downloader.MediaDownloader.GenericOutputMetadataExtractor, DevWeek.Services">
<property name="StartsWith" value="[ffmpeg] Merging formats into" />
<property name="EndsWith">
<value><![CDATA[(["'])(?:(?=(\?))2.)*?1]]></value>
</property>
</object>
</list>
</property>
</object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="MediaDownloaded" />
<property name="Destination" value="MediaStored" />
<property name="LogicalQueueName" value="MediaStore" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service">
<object type="DevWeek.Services.Downloader.S3MediaUploaderPipelineActivity, DevWeek.Services" autowire="constructor">
<property name="AudioBucketName" ref="CONFIG:DevWeek:S3:AudioBucketName" />
<property name="VideoBucketName" ref="CONFIG:DevWeek:S3:VideoBucketName" />
</object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="MediaStored" />
<property name="Destination" value="Finished" />
<property name="LogicalQueueName" value="Cleanup" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service">
<object type="DevWeek.Services.Downloader.CleanupPipelineActivity, DevWeek.Services" autowire="constructor"></object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
</list>
</property>
</object>
Pode parecer complexo por ser extenso e muito verboso, mas note o as configurações de 1 step:
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="MediaDownloaded" />
<property name="Destination" value="MediaStored" />
<property name="LogicalQueueName" value="MediaStore" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service">
<object type="DevWeek.Services.Downloader.S3MediaUploaderPipelineActivity, DevWeek.Services" autowire="constructor">
<property name="AudioBucketName" ref="CONFIG:DevWeek:S3:AudioBucketName" />
<property name="VideoBucketName" ref="CONFIG:DevWeek:S3:VideoBucketName" />
</object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
- A transição narra a transição de MediaDownloaded para MediaStored.
- O nome lógico da fila é MediaStore, a exchange vem da configuração.
- O consumer count manager (quem gerencia e entrega uma número mágico que representa a quantidade de workers necessários) está definido com mínimo de 1 worker e máximo de 10, avaliando o load do RabbitMQ a cada 1 minuto, e para sua conta ele espera que tenha 1 mensagem por worker (é o ratio para que ele decida quantos workers são necessários).
- O service é o nosso S3MediaUploaderPipelineActivity (tem código dele aqui no post, acima) com suas configurações.
- O método do S3MediaUploaderPipelineActivity que processará a mensagem que vem da fila é o método ExecuteAsync .
- A estratégia de gerenciamento de exceções é SendToErrorQueue.
Embora tenhamos muita informação, temos também muito poder nas mãos. Basta realizar essa configuração para que a mágica aconteça.
Note que como resultado, temos um código extremamente limpo,, autônomo. E nesse caso aqui ainda fazendo 2 coisas, como realizar a tarefa e solicitar a escrita chamando o Data Service.
Afinal, cadê esse projeto?
Perdão, o post estava pronto para ser publicado exceto pelo detalhe de que não havia compartilhado o link do repositório do github, nem havia compartilhado os posts a respeito do projeto.
https://github.com/luizcarlosfaria/youtube-downloader
Aqui nasce o projeto, mas tomei um strike do youtube sob o apelo de pirataria.
Aqui temos o segundo post que fala sobre a evolução do projeto e decisões que tomei.
Respondendo perguntas
Durante o carnaval eu fiz um post no grupo de arquitetura do telegram dizendo que tinha tempo disponível para tirar dúvidas. Enfim, fiquem em casa, não estava na pilha de sair. E daí o Ricardo Carvalho me fez a seguinte pergunta:
Em um ambiente de mensageria por fila fom rabbitmq. Qual seria uma estratégia interessante de monitorar as mensagens que não foram tratadas de forma correta pelos workers?
https://github.com/luizcarlosfaria/carnaval/issues/2
Exemplo 1 onde a ordem não importa (ack pode ser commitado quando mensagem for tratada com sucesso, ou quando o erro for tratado): ao tratar o evento PedidoCriado, o worker que consome esse evento e envia um email causou exceção.
Possível solucao: persistir este evento em uma nova fila, com o mesmo nome mas com um prefixo de Error, e monitorar manualmente os casos que entram nessa fila, e podendo voltar para fila original ou remover da fila de error e tratar manualmente.
Exemplo 2 onde a ordem importa (ack pode ser commitado somente quando mensagem for tratada com sucesso, pois é necessário segurar a fila): o evento de NovoLance em um leilão foi disparado, e o worker que trata isso falhou.
Possível solucao: retry???
Ps: fora o dashboard do rabbit, existe algum outro? De preferência free
No seu caso, você está pensando em consumo normal, sem um pipeline. Então podemos isolar qualquer um dos steps desse pipeline para exemplificar. No meu caso, no pipeline de download de mídia, eu comprometeria o pipeline, confirmando o processamento da mensagem sem antes enviar para uma fila de erro. No caso da implementação do pipeline, eu faço manualmente (o pipeline faz automaticamente, mas quero dizer que não uso o reject do rabbitmq, eu simplesmente publico na nova fila (de erro) e faço o ack logo após). Mas sei que essa forma não é tão inteligente quanto fazer direto nas configurações do RabbitMQ como dead letter (você consegue configurar direto no rabbitmq uma fila auxiliar de outra, para que mensagens rejeitadas possam ir para essa segunda-fila.)
Por experiência, eu digo que nunca vi e não consigo imaginar algum cenário em que o ack possa ser feito antes de concluir o processamento. Ack é análogo ao commit, tem de ser feito no final, sempre. Admito que pode existir algum cenário em que isso não se aplique, mas desconheço.
O cenário de Envio de email é um cenário típico de um step que é frágil. Nesses casos eu nem penso duas vezes: jogo esse fluxo em um pipeline.
- Step 1: prepara o email (seja com uma template engine, não sei)
- Step 2: envia o email (somente faz o send, nada mais)
- Step 3: persiste informações de controle no banco ou envia notificação de email enviado.
O mais relevante é separar o que for crítico e frágil em um único step dedicado a essa tarefa. Retry no envio de email não é uma coisa muito legal. Muito SMTP de larga escala reclama e te ranqueia mal. Eu ainda criaria um filtro antes para avaliar casos de bounce. (Soft bounce, hard bounce).
Retry é sempre uma possibilidade sadia, exceto com tarefas do tipo envio de email (que se você der mole e colocar muitas responsabilidades, um erro após o send, meio a uma política de retry, faz com que você envie emails duplicados).
Gostou? Quer tirar dúvidas? Comente!
Até dia 19 ainda tenho algumas coisas para escrever e demonstrar! Participe comentando.
Convite
Você está convidado(a) a participar comigo no hangout que faremos dia 19/03, próxima terça-feira onde falarei sobre RabbitMQ.






“Realiza o download/encoding dos 2 formatos (audio e vídeo) em um path temporário.”
Creio que quando desenvolveu o projeto cada micro serviço não estava dentro de um container Docker, conforme vi você comentar em um dos seus vídeos. No entanto, caso estivesse, qual estratégia você usaria para compartilhar essa pasta com dados temporários entre diferentes micro serviços?
Usaria um block storage? Mas é possível compartilhar um volume em mais de uma instância? Usaria um S3 com minio? Mas isso não iria necessitar que todos os micro serviços soubessem como fazer download de um servidor S3?