
Pipelines Elásticos quebram processamentos em pipes que por sua vez podem ser escalados individualmente. Atuando com grandes cargas de trabalho, oferece flexibilidade, melhor consumo de recursos e melhora no tempo de resposta com o aumento de paralelismo.
A dinâmica peculiar aos processos de longa duração exige sempre algum tipo de reengenharia e algum nível de inventividade. São cenários em que o mais simples nem sempre traz os resultados esperados. Escalar processos de longa duração pode não ser tão trivial quando parece. A dificuldade mora na razão entre paralelismo e produtividade, depreciados pela natureza desse tipo de processamento.
Aqui hoje vou trazer um exemplo que nasceu em 2013 e que pouco trabalhei em sua evolução desde então, mas ao criar o projeto/narrativa do Youtube Downloader, no hangout .NET Core: Continous Integration e Continous Delivery com Jenkins, vi oportunidades de discussão a respeito de diversos temas, que vão desde o quanto componentes/mecanismos de infraestrutura podem influenciar o design de uma solução, até questões mais objetivas, como quebrar um processamento de longa duração em um pipeline dinamicamente escalável.
Para entendermos do que estou falando com esse último ponto, é necessário compreender o contexto no qual aplicamos esse mecanismo.
Contexto
O mercado vem experimentado auto scaling ao longo da última década, seja usando IaaS ou PaaS, auto scaling é uma feature esperada em qualquer cloud. Mas por que não é esperada nos nossos serviços? O que fazer quando não estamos usando Azure ou Amazon? Quando você tem poucos recursos, esse pode ser um dilema que você precise tratar, ou simplesmente jogar a toalha e dizer que não dá. A falta de recursos nos faz encontrar alternativas para otimizar seu consumo, e auto scaling pode, eventualmente, ajudá-lo(a) a alcançar esse objetivo. Com docker, podemos escalar containers, que na prática são processos com seu conjunto de bibliotecas e runtime isolados em uma sandbox, rodando sobre um kernel compartilhado, mas:
- Quanto cada instância do seu container consome de rede, memória, cpu e disco, apenas para estar up, sem processar absolutamente nada?
- Qual o mínimo de consumo de recursos necessário para rodar sua app, sem que ela processe sequer uma atividade de negócio?
- Supondo que com problemas, relacionados a falta de escalabilidade, você passe a usar um Message Broker AMQP, como RabbitMQ, por exemplo: Será que optar por um único Consumer, single thread, por processo é uma boa estratégia?
Para quem trabalha com recursos limitados, há chance dos recursos disponíveis se esgotarem antes de conseguir atender a carga de trabalho, nesse caso, você tem aumento de latência, e seu throughput cai. No youtube downloader vemos isso acontecer já na primeira versão.
Exemplo – Youtube Downloader
Em dezembro comecei esse projeto hipotético chamado Youtube Downloader, que consiste em um serviço online que permite fazer download de áudio e vídeo do youtube. Um projeto não trivial cheio de coisas interessantes discutido nos posts que antecederam este. Esse projeto foi hospedado no scaleway, e serviu de ponto central para discussões em dezembro/2017, janeiro/2018 e finaliza sua jornada agora em fevereiro/2018. Sem mais delongas, para começar, desenhei um pipeline de processamento semelhante à imagem abaixo, composto por 7 etapas:

Etapas:
1) Onde recebemos uma solicitação de download.
2) Insert no MongoDB, onde obtemos um ID único para cada vídeo do youtube, sem duplicações. Passo-a-passo, esse ID é utilizado para que updates no documento possam ser realizados.
3) Download dos metadados, como capa do vídeo, e informações como título e descrição.
4) Download do MP4, usando Youtube-dl, uma cli, instalada durante o build da imagem docker.
5) O MP3 é gerado com auxílio do FFMPEG, onde geramos o MP3 a partir do MP4.
6) Enviamos os arquivos para o Minio, implementação do S3.
7) Por fim excluímos os arquivos temporários utilizados nesse processo.
Na classe DownloadPipeline temos uma lista, com instâncias que implementam a interface IPipelineActivity, uma interface que possui um método ExecuteAsync(DownloadContext). Esse projeto já foi concebido pensando em usar um pipeline simples, em hard code, e um consumidor da fila do RabbitMQ rudimentar, utilizando apenas 1 consumer para processar todo o pipeline. O objetivo é apresentar resultados insatisfatórios na primeira release mesmo utilizando filas, caching, nosql, e mostrar que não basta usar tecnologias da hora, se você não entender os aspectos que envolvem o consumo de recursos de sua aplicação ou serviço. Em seguida a dinâmica passa a mostrar uma das inúmeras formas para sanar essas questões, fazendo a aplicação realmente alcançar throughput e performance satisfatórios, mesmo operando com processamento intenso. Para criar uma restrição e mostrar que dá para trabalhar com pouco, criei um cluster docker swarm com as seguintes características:
- DEV | 8GB RAM | ATOM || Master
- PRD | 2GB RAM | ATOM || Worker
- PRD | 2GB RAM | ATOM || Worker
- PRD | 2GB RAM | ATOM || Worker
Vale lembrar, para quem não viu a solução, que temos:
- RabbitMQ
- Redis
- MongoDB
- Minio (implementação on premise baseada no protocolo do Amazon S3)
- Worker – Console .NET Core (dedicado ao processamento desse pipeline)
- WebApp – ASP.NET Core (UI e exibição dos vídeos)
Na infraestrutura que contratei para essa demonstração, o nó DEV possui todos os recursos, enquanto os 3 nós de PRD distribuíam recursos de produção. Em adição, DEV também possuía Jenkins instalado no host. Com essa disposição de infraestrutura e aplicação, mesmo com o uso de filas, escalar não é uma tarefa fácil. Na prática o pipeline que vemos no DownloadPipeline e o consumidor da fila do RabbitMQ simplesmente não foram concebidos para escalar no mesmo processo, demandando novas instâncias do processo inteiro para conseguir algum paralelismo. A imagem à direita mostra nossas capacidades de paralelismo nessa versão do projeto. Encontramos duas oportunidades claras de aumentar a escala, escalando o processo como um todo ou o pipeline inteiro. Levando em conta que o container do Worker, responsável pelo consumo das filas, consome até 200MB de RAM, dá para chegar a conclusão fatídica que cada nó de produção, se dedicado exclusivamente para a aplicação, só suportaria apenas 10 processos, respectivamente 10 consumidores, ou 10 threads, atendendo apenas 10 requisições simultâneas de download, sem que deixasse solicitações enfileirando. Isso com a configuração e estratégia que utilizei, claro. Isso sem contar que, na prática, 10 era o número total de instância de containers do tipo worker em produção, já que existiam outros recursos a serem alocados nesses mesmas máquinas.
Pipelines & Auto Scalling
A dinâmica apresentada no cenário acima mostra um exemplo de uma arquitetura interessante, mas ainda ineficiente. Nesse caso, vemos apenas 2 possibilidades de paralelismo para o processamento de vídeos e músicas, algo muito ruim com o cenário restritivo que tínhamos. Na prática, existem técnicas e padrões para se aumentar throughput em cenários assim, garantindo maior paralelismo e escalabilidade, eu escolhi para esse projeto, um Pipeline Elástico, que consiste em um orquestrador de pipeline que possui a capacidade de escalar dinamicamente cada step do pipeline, individualmente, usando threads de consumo de filas AMQP (RabbitMQ). Toda a nova configuração está detalhada no arquivo Container.Config.xml. Isolando a configuração de um único step vemos:
<object type="DevWeek.Architecture.Workflow.QueuedWorkFlow.QueuedTransition, DevWeek.Services">
<property name="Origin" value="MetadataDownloaded" />
<property name="Destination" value="MediaDownloaded" />
<property name="LogicalQueueName" value="MediaDownloader" />
<property name="ExchangeName" ref="CONFIG:DevWeek:RabbitMQ:DownloadPipeline:Exchange" />
<property name="ConsumerCountManager" >
<object type="DevWeek.Architecture.MessageQueuing.ConsumerCountManager, DevWeek.Services">
<property name="MinConcurrentConsumers" value="1" />
<property name="MaxConcurrentConsumers" value="10" />
<property name="AutoscaleFrequency" value="00:01:00" />
<property name="MessagesPerConsumerWorkerRatio" value="1" />
</object>
</property>
<property name="ServiceMethod" value="ExecuteAsync" />
<property name="Service">
<object type="DevWeek.Services.Downloader.MediaDownloaderPipelineActivity, DevWeek.Services" autowire="constructor"></object>
</property>
<property name="ErrorFlowStrategy" value="SendToErrorQueue" />
</object>
Nessa configuração conectamos um QueuedTransaction, MediaDownloaderPipelineActivity, fazendo com que ele orquestre a chamada do método ExecuteAsync, utilizando RabbitMQ. Em adição temos o ConsumerCountManager configurado para escalar a quantidade de threads na razão de 1 por mensagem na fila, com limites compreendidos entre 1 e 10 threads, refazendo o check a cada 1 minuto.
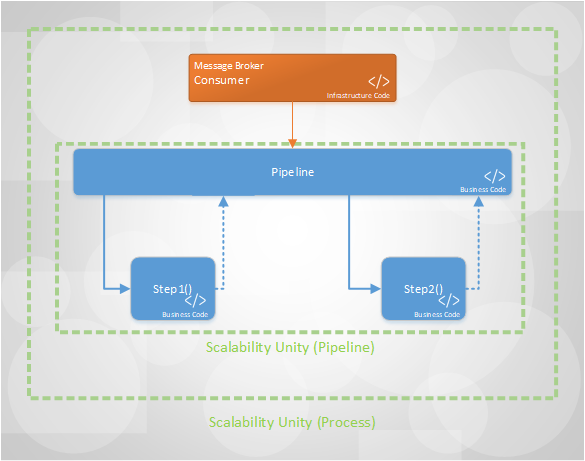
Para entender melhor a solução eu fiz o diagrama abaixo:

Nela eu apresento os artefatos lógicos, assim como feito com a imagem no início do post.
O Pipeline Workflow é uma especialização do Workflow que não possui desvios de fluxo. Este elemento, em vez de processar um pipeline inteiro na mesma thread, utiliza filas para cada uma das etapas do pipeline. Orquestrando entrada-e-saída de métodos de negócio de cada tarefa, gerenciando o encaminhamento as mensagens para para as exchanges adequadas, usando o roteamento adequado, para que a mensagem caia na fila dedicada à próxima etapa do processo. Assim sucessivamente o pipeline é processado de forma linear, cross thread, cross process, cross machine e talvez até cross cloud. Essa estratégia exige bastante configuração, como vemos no arquivo Container.Config.xml, mas o resultado é fantástico. Graças ao ConsumerCountManager, responsável por qualificar as métricas em um resultado que exprima necessidade de manter, aumentar ou reduzir a quantidade de consumidores para determinada fila, o processo ganha a capacidade de aumentar e diminuir a quantidade de threads e consumidores de fila de acordo com o workload.
Arquitetura Subliminar
Assim como uma linguagem subliminar, encoberta ao olhar desatento, entretanto explícita nas configurações, os mecanismos arquiteturais assumem muitas das responsabilidades, que naturalmente assumiríamos em código de negócio, ou em projetos dedicados à infraestrutura do projeto em questão, levando ao trade-off entre generalização e especialização. Eu sempre opto pela generalização.
É incrível hoje, 4 anos após sua implementação, conseguir reaproveitar 100% de um código que faz uma gestão relativamente complexa, sem precisar de nada mais do que configurações para conectar ao negócio à infraestrutura e permitir escalar, 1, 2, 10, 100 steps de qualquer pipeline, independente de sua complexidade. Agregar essas capacidades sem demandar refatoração, é algo que encaro com muito bons olhos, já que há um total desacoplamento entre ambos. Esse nível de generalização faz com que um componente/serviço de negócio realize apenas sua tarefa, de forma agnóstica, ficando a cargo da arquitetura o tratamento peculiar às tecnologias, A, B ou C, no nosso caro, a infraestrutura de Publisher e Consumer dessas filas. Reduzir, e nesse caso até eliminar o acoplamento ajuda a melhorar a coesão e oferecer um código mais legível. Do lado da arquitetura, encontramos cada vez mais reaproveitamento.
Conclusão
Não basta usar docker, não basta usar docker swarm, não basta usar filas, não basta usar NoSQL, tecnologias são só tecnologias, elas ajudam a alcançarmos objetivos, no entanto é necessário entender como aproveitar melhor seus recursos seja no âmbito de infraestrutura ou mesmo com linguagem e plataforma. Este não é um post para desanimar a galera mais jovem, mas para mostrar que é necessário pensar fora da caixa e compreender as restrições que são impostas pela situação. Como disse no post Como definir a Arquitetura de um Software, é necessário entender o contexto em que estamos inseridos para tomarmos decisões arquiteturais embasadas. As dificuldades que levaram à criação desse modelo são abordadas com mais detalhes post Por onde andei, andei frustrado onde apresento, inclusive, pela primeira vez, o modelo de Causa, Efeito e Reação utilizando diagramas de BPM.
Aproveito para mostrar um vídeo que me chamou bastante a atenção na medida que pontua throughput alcançado com cada tipo de cruzamento de vias(ruas, estradas etc). Seria incrível ter dados assim sobre escalabilidade!
Por fim, não poderia deixar de citar o Felipe Mayor, quem escreveu boa parte desta infra de auto scaling.






0 comentários