
Qual é o throughput médio de minha API? Será que essa nova implementação está consumindo mais ou menos recursos? Há algum memory leak? Bom, algumas informações só podem ser vistas quando você roda um tipo específico de testes, o teste de carga. Artillery te ajuda a executar cargas de trabalho intensivas em sua API, e isso pode ser feito na sua máquina, sem muito esforço, você só precisa ler esse post e executar alguns poucos passos! .
Chegando até aqui
Voltando ao Wbot
Vou conta a história que me fez chegar até aqui: No final de 2016 comecei pela Ebix uma plataforma de bots chamada Wbot. Precisava ser algo escalável e extremamente confiável. Meu foco era o mercado corporativo, oferecendo maturidade e governança, elementos que facilmente nos diferenciaria dos demais “desenvolvedores de bots”. O projeto consiste em um middleware gerenciável projetado para a implementação de bots de alta escala. Vamos pular isso, pois tem mais um monte de features legais que explico no final de a anatomia de um chatbot.
O débito técnico
Fato é que com um dos componentes da solução estava listado com um débito técnico que precisava ser tratado. Eu havia criado um High Availability Proxy (não confunda com o HAProxy), um mediador HTTP que publica tudo que recebe via HTTP em filas AMQP no RabbitMQ, ele também contava com um worker. O responsável por processar aquilo que havia sido enviado para as filas. Embora funcionasse bem, seu design me incomodava, principalmente porque eu queria reutilizar a infraestrutura de controllers do ASP.NET Core para processar as mensagens: No worker! Não serviria para tudo, mas facilitaria muito a criação de webhooks, bots e uma série de outros tipos de projetos (se pareceu muito estranho, leia AMQP vs HTTPEN de Federico Sánchez).
Why?
Em vez de você conhecer sobre filas, trabalhar com um consumidor de filas, eu queria entregar a mesma experiência de quem trabalha com ASP.NET Core, substituindo HTTP por AMQP e assim usar todos1 os recursos do ASP.NET Core de forma transparente como: rotas avançadas, model binder, serialização, injeção de dependência, segurança2 e muito mais. Esse era o objetivo inicial que só consegui resolver agora. Na prática, até então tinha uma estrutura de roteamento rudimentar, e reimplementei algumas coisas. Como resultado a versão que eu tinha até ontem não estava legal. Funcionava, não demandava mudanças, mas nem de longe era algo que eu pudesse me orgulhar, e bater no peito dizendo: Ficou foda! Não ficou, estava com toda a cara de uma gambiarra que reinventava a roda.
A chance de resolver a questão
Os tempo passou e me vejo novamente com algumas demandas no WBOT o que me fez repensar nesse assunto e como disse em Como definir a Arquitetura de um Software, Uma gambiarra é igual a uma mentira. Sempre precisará de novas para justificar a primeira e se você me acompanha há algum tempo, sabe que não gosto de débitos técnicos, (falo sobre isso em em Por onde andei, andei frustrado), afinal eles precisam morrer! Enfim tive a oportunidade de voltar ao assunto e embora tenha conseguido executar toda a estratégia técnica (todas as features), a implementação não ainda está entregando a performance que eu almejava. E como cheguei a essa conclusão? É aí que o artillery entra!
Métricas
Um dos testes mais interessantes para esse tipo de projeto é o teste de carga, onde submetemos o mecanismo a uma grande carga de trabalho para entender como ele se comporta. As métricas relevantes são:
- Throughput: Quantidade de Requisições por segundo
- Memória: Perfil de consumo de memória, crescimento, alocação e devolução de memória ao final da carga de trabalho.
- CPU: Consumo de CPU para entregar um determinado throughput
- Confiabilidade
- Tolerância a Falhas / Recuperação de Falhas
Levando em conta que funcionalmente o projeto atende aos requisitos, o próximo passo é entender se os requisitos não funcionais também estão sendo atendidos. E medindo vou determinar se essa versão pode ou não ser usada. Caso positivo, também determinarei se há ou não novos débitos técnicos já conhecidos. As diversas decisões decorrentes desses números são:
- Está tudo ótimo, não precisamos mais olhar para esse mecanismo.
- Está bom, mas poderia ficar melhor, merece uma refatoração no futuro, mas já pode ser usado.
- Está bom, razoável ou até ruim e precisa de refatoração agora, para poder pensar em usar isso no mundo real.
- Está péssimo e precisa ser refeito do zero.
Entre Go e NoGo há aspectos como confiabilidade, segurança, performance e escalabilidade nos quais preciso me preocupar, afinal o mecanismo é pilar de uma infraestrutura de High Availability. Mas afinal onde entra o Artillery? O artillery é usado para empurrar uma enxurrada de requisições na API, de forma coordenada. Com uma alta carga de trabalho por um bom tempo, é possível entender como o projeto se comporta, qual o throughput, o perfil de consumo de recursos, sua confiabilidade, enfim, diagnosticar tudo que preciso para tomar minhas decisões e fazer minhas anotações.
Artillery
Como esse texto é sobre o artillery vou me ater a ele a partir daqui! Ok? Outro dia eu publico esse projeto com calma no github e comento aqui.
Como instalar o Artillery?
npm install -g artillery
Como executar o Artillery?
Após instalado como pacote global, está disponível no console.
#Método 1 - quick
$ artillery quick -h
Usage: quick [options] <target>
Run a quick test without writing a test script
Options:
-h, --help output usage information
-r, --rate <number> New arrivals per second
-c, --count <number> Fixed number of arrivals
-d, --duration <seconds> Duration of the arrival phase
-n, --num <number> Number of requests each new arrival will send
-t, --content-type <string> Set content-type (defaults to application/json],
-p, --payload <path> Set payload file (CSV)
-o, --output <path> Set file to write stats to (will output to stdout by default)
-k, --insecure Allow insecure TLS connections, e.g. with a self-signed cert
-q, --quiet Do not print anything to stdout
#Exemplo 1
artillery quick -r 10 -n 200 -d 600 https://localhost:5000/api/values
#Exemplo 2
artillery quick --count 10 -n 20 https://artillery.io/
O comando quick do artillery permite configurar tudo inline, direto no bash. Já o comando run é mais completo pois depende de um arquivo yaml para realizar as configurações da carga de trabalho.
No exemplo 1 temos:
- 10 novos usuários/segundo (-r)
- realizando 200 requisições cada um (-n)
- durante um período de 10 minutos (-d)
No exemplo 2 temos:
- 10 novos usuários (–count)
- realizando 20 requisições cada um (-n)
Caso optasse pela versão yml, teríamos algo assim:
config:
target: 'https://artillery.io'
phases:
- duration: 60
arrivalRate: 20
defaults:
headers:
x-my-service-auth: '987401838271002188298567'
scenarios:
- flow:
- get:
url: "/docs"
para executar seria assim:
artillery run hello.yml
O resultado é assim
Report @ 00:41:42(-0300) 2018-06-23
Scenarios launched: 100
Scenarios completed: 2
Requests completed: 49383
RPS sent: 4952.95
Request latency:
min: 193.5
max: 923.7
median: 242.7
p95: 341.4
p99: 488.8
Codes:
200: 49383
Para monitorar consumo de recursos usei o Sysinternal Process Explorer e o próprio Visual Studio com o diagnóstic tools do visual studio.O process explorer é mais eficiente quando estamos rodando algo fora do visual studio. Nos meus testes o resultado foi um sucesso exceto pelo consumo de memória e progressão desse consumo. Há memory leaks, isso significa que tenho trabalho para o final de semana.
Resultados:
A imagem abaixo mostra meu throughput, com o High Availability Proxy publicando no RabbitMQ 7096 mensagens por segundo. Neste caso, não havia das mensagens pois estou simulando com workers offline, usando FireAndForget.
No bash à direita, vemos o artillery trabalhando, estou usando 2 abas pra rodá-lo, portanto essa métrica que você vê aí é parcial.
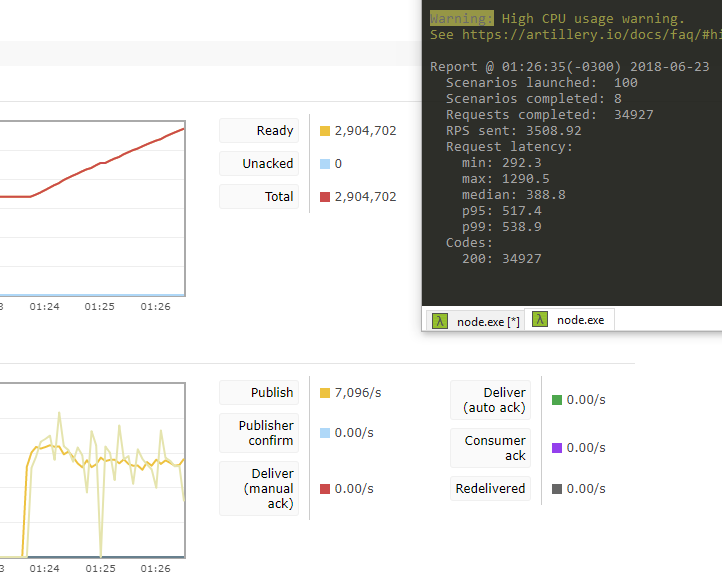
Esses números me atendem, mas poderiam ser melhores. Mas abaixo temos um problema grande, o consumo de memória e sua crescente mostra claramente que há um problema no consumo de memória e preciso trabalhar nisso. No visual studio temos ferramentas para gerar dumps de memória e compará-las (com seus objetos etc).

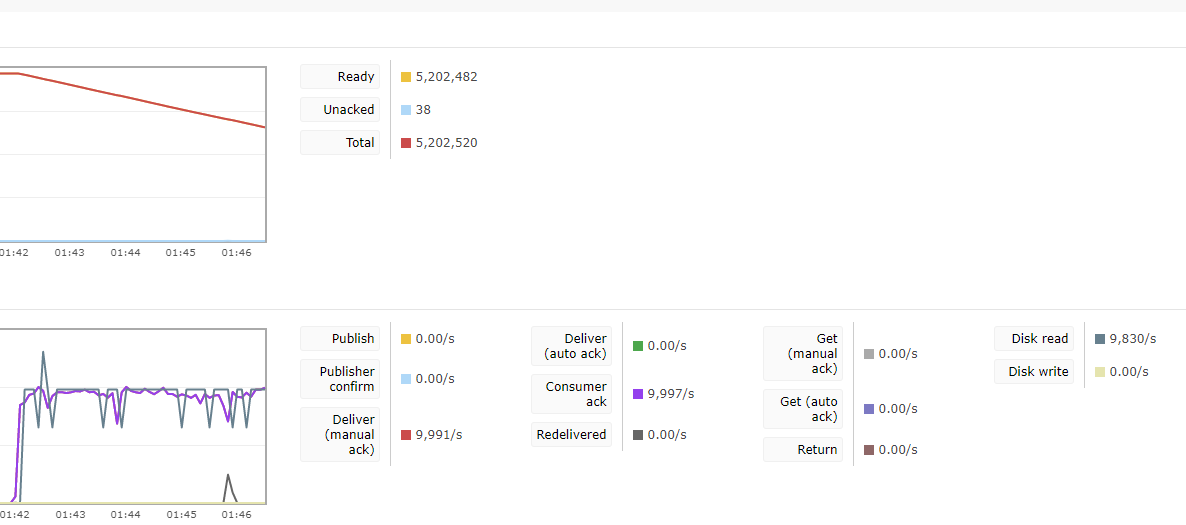
Agora é hora de fazer a mesma coisa com o Worker, a outra parte no fluxo. Note que um worker consegue atender quase 10k mensagens por segundo, o que é perfeitamente aceitável em virtude do benefício alcançado ao escolher essa estratégia para a integração com o RabbitMQ. Mas nem de longe é um número impressionante.
De fato se o consumo de memória não estivesse comprometido, daria como resolvido com algumas ressalvas (no throughput). Por hora tenho mais trabalho para otimizar isso e garantir menor consumo de memória e um consumo mais estável.
Entender esse comportamento e ter clareza sobre o que acabei de fazer são fundamentais para inspirar confiança no que está sendo entregue. Somente de posse desses números posso tomar decisões e estou fortalecido para defender o projeto, a solução em si, e apontar, antes de outros, as falhas e necessidades do meu projeto. Compreender seu próprio calcanhar de aquiles antes de ter um problema é fundamental para não ser pego com uma premissa falsa, ou equivocada. O artillery pode te ajudar a entender melhor como suas API’s se comportam sob altas cargas de trabalho, o que é incrível para antever problemas.
Bonus
Embora você tenha visto isso acontecendo no meu console, testando local, já pensou em integrar um processo de stress no seu build server? Como uma das métricas para o blue/green deployment? Bom, se gostou da ideia, comente aqui para que eu possa falar mais sobre isso.
Notas e Observações:
1 Ignorando SignalR e qualquer estratégia conectada, como WebRTC e afins.
2 O básico de segurança, com tokens pelo menos.

0 comentários