
A Microsoft sem sombra de dúvidas é uma empresa com um foco incrível no desenvolvedor. Diariamente recebemos algum tipo de update, feature, novo produto ou projeto para ajudar no nosso dia-a-dia.
O Visual Studio é uma dessas IDE’s incríveis, que fazem tudo por você. E se você já me viu criando um projeto com Docker Compose e .NET Core, viu o quanto que é de fato simples e fácil.
Um dos recursos adoráveis para quem está começando é o publish. O Visual Studio dá suporte à diversos perfís de publicação que por sua vez podem fazer milhares de coisas diferentes.
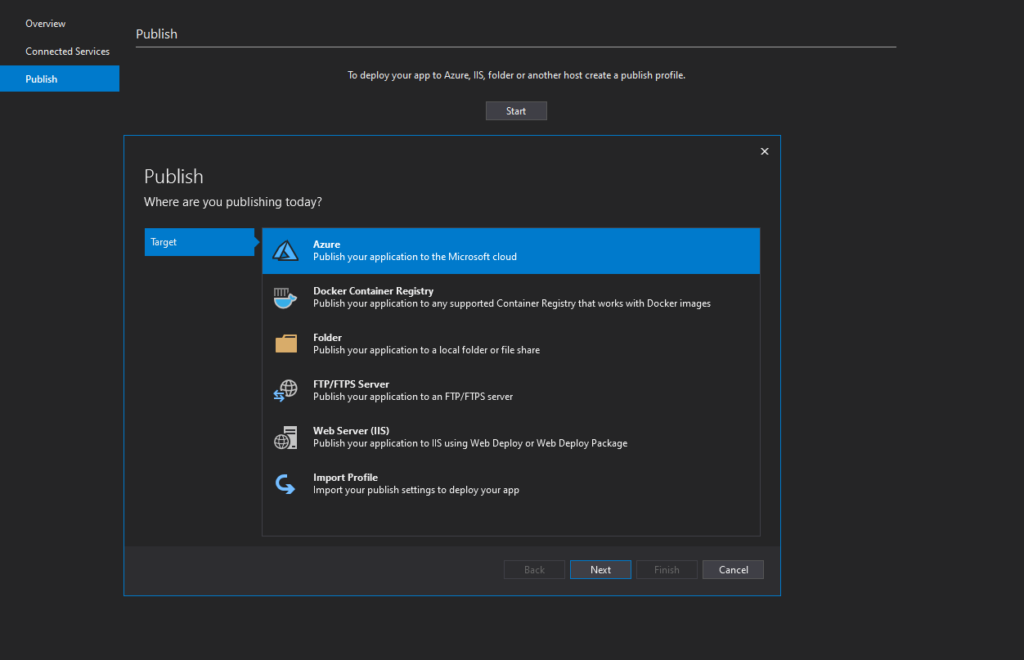
E isso é bom? Funciona?
Sim, definitivamente o Visual Studio é uma IDE fantástica e sim, esse processo de build e publish funciona perfeitamente. Com ele você consegue com alguns clicks fazer o deployment de sua aplicação nos mais variados locais e lugares.
Entendendo a Microsoft
A Microsoft gasta muita energia em reduzir a fricção para a adoção de suas tecnologias. Ou seja, ela investe pesado em tornar o mais simples e mais fácil possível.
Um dos fundamentos da Microsoft é o foco no Desenvolvedor, empoderando-o. E sim, esse é o tipo de coisa que definitivamente dá poder ao desenvolvedor.
Há uma redução enorme da curva de aprendizado para se colocar uma aplicação em produção. São poucos clicks e voilà, temos uma aplicação em produção.
E isso é tudo?
Óbvio que não.
Não podemos nos esquecer que sempre que não tomamos decisões que precisam ser tomadas, alguém as toma por nós.
Nem de longe qualquer estratégia que parta do Publish do Visual Studio é uma estratégia profissional ou recomendada para cenários enterprise.
Não é hoje, e nunca foi.
Amador? Como assim?
A primeira vez que eu vi um pipeline, chamávamos de esteira, e isso era em meados de 2002, ou seja 19 anos atrás.
Mas o que esse “pipeline/esteira” tem de diferente que faz o Publish do Visual Studio ser algo amador?
Quando eu penso em uma PoC ou teste, em geral a proposta é validar uma ideia ou uma tecnologia. E se o publish não é objetivo do estudo, ele só será feito de forma profissional, se aquilo me trouxer benefício imediato. Ou seja, se poupar tempo.
Então em cenários assim, eu até poderia usar o publish do visual studio, mas no meu caso, com .NET, docker e jenkins já está tão prático copiar um pipeline completo e trazer para o meu projeto que, sinceramente, eu prefiro fazer certo, com mostrei algumas vezes em lives. Mas nesse caso de PoC ou teste, sim é opcional, só uso para ganhar tempo.
E esses desenhos não levam nem de longe a preocupação com versionamento e longevidade do projeto. Embora eu versione sim.
Mas a grande diferença entre o Publish do Visual Studio e um pipeline no Azure DevOps ou Jenkins está nos requisitos para que a publicação aconteça.
Na sua máquina, o Visual Studio não se preocupa se o projeto está versionado, se os testes estão rodando, se a cobertura de testes está ok, nem realiza passos avançados de produção de métricas. Sequer se preocupa com a branch que você está trabalhando. Ele olha para a solution/projeto aberta e só.
Esse modelo não assegura nada, e por isso é um modelo frágil que depende das pessoas, de quem está operando o visual studio. Ao mesmo passo que toma tempo do desenvolvimento, e pior, tempo adicional. Pois a não ser que você esteja trabalhando SEM VERSIONAMENTO NENHUM, que é um erro vezes maior, o commit não é opcional, mas o deployment pela IDE, sim.
Claro que cada controle desse precisa estar presente no pipeline, mas a mágica é que qualquer controle que você queira, basta adicionar ao pipeline e automaticamente qualquer envolvido no projeto passa a herdá-lo. Mas a garantia mais básica e mais simples de todas, já está assegurada:
Código não comitado, não chega a lugar algum.
A governança agradece!
Ou seja, temos a garantia de que:
- o que quer que esteja sendo implantado, está versionado no git.
- o que quer que esteja no git, ao menos está compilando.
- novas dependências continuam deixando o projeto compilar e produzir o publish.
- e o output de build não possui novas dependências exclusivas da máquina de desenvolvimento.
Quando fazemos o Publish com o Visual Studio, não temos meios de dar essas garantias. Nenhuma delas.
Isso acontece porque você pode simplesmente alterar 2 linhas do código-fonte e publicar o projeto. Basta ter algo que compile e pronto.
Diferente de um pipeline de CI/CD pode aplicar as mais variadas validações nessa aplicação. Dá para:
- Rodar testes
- unitários
- integrados
- stress
- load
- Rodar analisadores de código
Independente do tamanho ou complexidade do seu pipeline, os pontos mais importantes são:
- Assegurar que todo deployment nasceu de um código versionado
- Assegurar que para o build e execução da aplicação, não há dependências não mapeadas.
O Visual Studio é capaz de te ajudar na construção do pipeline, com Azure DevOps. Fazer os commits, mas o publish da IDE não possui as garantias que precisamos em ambientes profissionais.
Qualquer nova instalação ou dependência/referência local que faça seu desktop de desenvolvimento ter algo a mais que o servidor de build ou deployment, tem a oportunidade de afetar sua aplicação de modo a ela só funcionar em seu desktop. Realizar builds e publicações a partir de servidores de CI/CD assegura o devido mapeamento dessas dependências.
Em um ambiente temos:
- GitHub Actions
- Azure DevOps
- Jenkins
- TeamCity
Ou qualquer outra infra de automação. A escolha da ferramenta fica a seu critério. Eu não vou sugerir. Não importa tanto qual ferramenta é usada, o que importa é garantir que:
- Servidores nunca recebam publicações direto da máquina do desenvolvedor.
- Servidores nunca recebam publicações cujo código-fonte possa não estar versionado.
Mas isso parece coisa de exército, muito burocrático! Qual o fundamento disso?
- Na máquina de desenvolvimento você tem um conjunto de ferramentas, libraries, setups que são diferentes dos de um servidor.
- Você tem SDK, em geral servidores possuem apenas Runtime.
- Você pode ter usado um SDK diferente e incompatível com o Runtime do servidor.
- Você tem instalações adicionais,
- Você pode ter feito referências a projetos não versionados, defasados ou referências a binários que estão no disco. Nada disso é compatível com o servidor.
- Código não versionado pode ser perdido.
- Código não versionado pode ser alterado antes de ser versionado, portanto pode não representar o que está em produção.
- Não necessariamente o código que gerou o deployment foi produzido contendo a última versão. Ou seja, ele pode ser incompatível, pode reintroduzir bugs que já foram corrigidos, ou apagar features que já foram entregues, ou ainda quebrar features que estavam funcionando.
Eu fiz um vídeo detalhando isso:
Abaixo deixo um depoimento em um comentário do vídeo lá no youtube.
Já aconteceu na empresa de uma dev matar a versão do outro em produção com essa coisa de deploy da própria máquina, pois o dev que fez a publicação anterior não fez commit.
Outra situação que ocorreu foi de um dev pegar uma lib que era do framework da empresa, alterar na própria máquina e mandar para produção e não avisar o time responsável por essa lib e dias depois, houve o mesmo problema de matar a versão do servidor de produção.
Estou tentando implantar o Jenkins na empresa, mas os gestores acham que o dev ter acesso direto ao servidor dá mais “agilidade” e não “burocratiza” o processo.
Tenho fé que um dia chegarei lá
abraços e desculpe se me alonguei
Alexandre Lopes (Comentário do Youtube)
Conclusão
Regras de ouro podem te ajudar:
- Servidores não devem receber, nunca, publicações direto da máquina do desenvolvedor.
- Servidores não devem receber, nunca, publicações cujo código-fonte possa, eventualmente, não estar commitado.
- As regras acima precisam ser claras, comunicadas e asseguradas por políticas de acesso.
Não existem muitas formas de assegurar que esses problemas relatados aqui não aconteçam, se suas políticas de acesso e autonomia não ajudarem.
Se algo de ruim ou inesperado acontecer, você tem a capacidade de olhar para o fonte que produziu aquilo e corrigir. Ou ainda voltar para a versão anterior. Mas o mais importante é não produzir o tipo de instabilidade que código não versionado produz: Erro em produção que é impossível de reproduzir pois o código de produção só existe no deployment e não existe no repositório git.
Bonus
Não sei se vocês repararam durante as lives, mas eu faço minhas automações logo nos primeiros momentos do projeto, bem antes dele estar pronto. Isso me assegura muitas coisas, inclusive me permite ter o histórico evolutivo e conseguir implantar a qualquer momento.
Essas decisões (as regras) e a decisão de começar o projeto já com automações, economizam muito tempo no curto, médio e longo prazos. Você agora não precisa ficar apertando botão e esperando a publicação chegar a produção, basta fazer o commit e continuar o trabalho.
Afinal não estamos aqui para apertar botão.
Sobre a capa, fica a provocação:
Não seja você o cavalo de Troia, o Visual Studio só está ali para tornar esse processo simples. Não ter um pipeline, ou uma automação é um problema da sua empresa, da seu equipe ou do seu projeto.





0 comentários