
Você já nos viu falando de Proxy Reverso, em geral usamos NGINX nessa tarefa, mas afinal? Pra quê isso? Por que “isso” é necessário?
Para que fique claro, precisamos voltar no tempo e revisitar alguns assuntos. Vou dar uma pincelada em assuntos como DHCP, DNS, e alocação de portas.
É fundamental para conseguirmos chegar no ponto exato onde os Proxies Reversos fazem sentido.
Fundamentos
DHCP
Quando teu computador se conecta à uma rede, ocorre um handshake (apertar de mãos) para registrar-se e obter as configurações da rede. Dessa negociação algumas informações são trocadas, 2 delas são: o IP que seu computador usará nessa rede, e endereços de servidores DNS.
Desse assunto, o que tem de estar claro é que sua rede informa quais os endereços dos servidores DNS’s, o servidor DHCP é quem entrega essa informação, mas você também pode sobrescrever isso para cada interface de rede.
Se você usa hyper-v ou virtualbox, verá interfaces de rede virtuais adicionais. Se você possuir uma placa de rede WIFI, terá outra interface física também.
DNS
DNS, Domain Name Server é um protocolo de resolução de nomes.
O DNS traduz nome em IP
E note, ele só traduz nomes em ip’s.
Não é do escopo do DNS tratar portas.
Anota isso que é tão óbvio, quanto importante.
Quantas e quantas vezes vejo gente perdendo tempo buscando como configurar porta de roteamento no DNS. Isso simplesmente não existe. DNS não lida com portas.
O pipeline de uma requisição HTTP
Quando, por linha de comando, executamos curl portal.azure.com ou mesmo usamos o browser para acessar o mesmo link. Algumas tarefas são realizadas.
Decompondo a URI
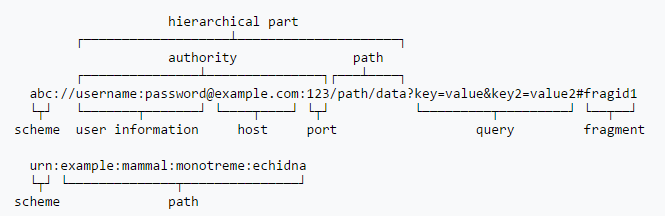
O primeiro passo é decompor a URI usada. Essa uri sempre segue a sentença acima.
Pontos de atenção:
- Schema
- Host
- Porta
Outras regras estão ligadas ao schema vs porta. Alguns schemas possuem portas padrão. Como HTTP refere-se à porta 80, enquanto HTTPS refere-se à 443 ou rtmp referindo-se à porta 1935.
Embora possamos, explicitamente, definir a porta, quando não fazemos, a porta default é usada, caso haja.
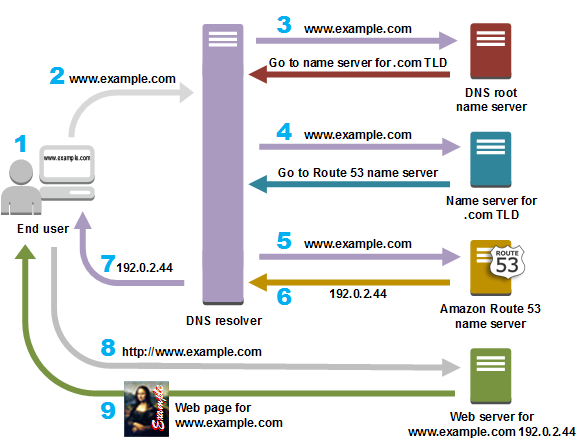
Assim, quando acessamos portal.azure.com, a biblioteca base de rede (possivelmente do SO ou da tecnologia) faz o trabalho sujo de usar a infra de DNS para descobrir o IP em questão, recorrendo às buscas pelas autoridades de .com e .azure.com, e por fim pergunta pra .azure.com quem é o portal.azure.com. Recebemos um ou vários IP’s como resposta.
Fazendo uma requisição
Uma vez de posse do IP, é hora de enviar os pacotes pela rede. Mas para enviar esse pacote, precisamos especificar a porta de destino. Lembra daquelas regras que citei acima? Elas se aplicam aqui! É assim que a porta é descoberta. Usa-se preferencialmente a porta explicitamente declarada na URI, caso não haja, avalia-se a porta padrão do schema. Caso não haja, erro! Simples assim!
Por isso algumas implementações de acesso à rede possuem mais schemas/padrões que outras e isso faz com que eventualmente possamos ver comportamentos diferentes aqui ou acolá.
Essas diferenças se traduzem nos seguintes comportamentos:
Em uma solução A você precisa informar a porta, mesmo que informe o schema.
Enquanto em uma solução B basta usar o schema que a porta é magicamente inferida.
Uma vez que sabemos IP e porta é hora de montar a requisição. Parte dessa mensagem é o cabeçalho, que, é conhecido por nós, são os cabeçalhos do HTTP. Aquela informação que usamos para determinar protocolo, host, ip do host e porta, são enviados no cabeçalho.
É agora que começa a mágica do lado do servidor, é aqui que precisamos de um proxy reverso. Sim, eu levei toda essa explicação para conseguir chegar até aqui.
Escutando uma porta
Nos sistemas operacionais que conhecemos e estão no nosso cotidiano, podemos escutar portas.
Isso é, criar um programa que recebe o tráfego de rede de uma ou mais portas.
Mas uma coisa precisa estar muito, mas muito clara. 2 processos não podem escutar a mesma porta! Seja no windows1 ou no linux2 escutar uma porta é uma tarefa exclusiva* para somente 1 processo.
1) No Windows, temos o port sharing como uma features que cria um serviço de escuta tcp, distribuidor de requisições. É uma feature exclusiva para produtos da própria Microsoft, como WCF, pois ao estar ativo, internamente os serviços que tentariam consumir a porta, passam a usar protocolos alternativos de comunicação entre processos para realizar a comunicação com o proxy.
2) Desde o kernel 3.9 o linux o primeiro chamador a abrir o socket de escuta, pode informar um parâmetro adicional para que a porta possa ser compartilhada. Pesquise sobre SO_REUSEPORT em SOCKET Linux Programmer’s Manual.
Os modelos de escuta compartilhada de portas nascem para viabilizar a utilização de todos os cores do sistema para atender às escutas de rede. Isso permite que você tenha uma instância principal de gestão e diversos processos-filho escutando a mesma porta, mas processando em um core diferente. Mas isso não permite que você tenha 2 serviços ou sequer 2 instancias DISTINTAS. Pois a distribuição de carga geraria um caos.
Dessa forma, não conseguimos lidar com um apache e um nginx, ambos escutando a mesma porta 80 na mesma interface de rede. Precisamos de um mediador para isso. É aí que entra o proxy reverso.
Proxy Reverso
Um proxy reverso vem resolver essa questão. E ao longo do tempo essa categoria de aplicações foi se especializando, ganhando funcionalidades e se subdividindo em diversas categorias.
Um forward proxy, ou simplesmente proxy, fica entre sua máquina e a internet, fazendo seu trabalho mediando o tráfego que está saindo do seu computador rumo à internet.
Um proxy reverso fica entre a internet e seu servidor, fazendo seu trabalho com o tráfego que está chegando.
Hoje em dia, um proxy reverso pode ter algumas responsabilidades comuns:
- Comuns
- Roteamento
- Distribuição de Carga
- Tolerância a indisponibilidade
- Cache
- Segurança (SSL)
- Log
- Monitoramento
- API Gateways
- Todos os elementos comuns
- Autenticação
- Autorização
- Métrica de Consumo
- Estrangulamento de tráfego excedente (por métricas por API)
- WAF – Web Application Firewall
- Todos os elementos comuns
- Análise de tráfego
- Análise de conteúdo trafegado
API Gateways podem ser considerados proxies reversos? De certa forma, sim, mas eles são classificados de forma diferente: eles têm uma visão um pouco diferente dos Proxies Reversos comuns.
API Gateways são especialistas em API’s. Um proxy reverso, é mais generalista.
Um proxy reverso consegue limitar sua quantidade de requests a X por minuto. Mas não é muito eficiente ao determinar que você só pode consultar um determinado serviço, X vezes por mês. Os dados do proxy reverso em geral são mantidos em memória, enquanto nos api gateways são necessários bancos de dados para armazenar essas métricas e impor essas políticas.
Eu não vou entrar em detalhes a respeito disso, mas alguns proxies reversos, ou plugins para proxy reverso são usados inclusive para otimizar o conteúdo entregue. Alguns são especializados em HTML e conseguem fazer mágicas como, otimizar seu output html de diversas formas, lidando com coisas complexas como substituir suas referências para PNG’s, e ao mesmo tempo mapear esses PNG’s e substituílos por formatos mais otimizados como WebP. Isso de fato é insano, e convido a ler sobre Google PageSpeed Module.
Proxy Reverso é parte fundamental da internet
Vamos supor que você tenha 2 servidores de backend. Como você faz com que um deployment não cause indisponibilidade?
O proxy reverso que consegue determinar que um dos backends está indisponível conseguiria servir todo o tráfego com o servidor que está disponível, enquanto o outro servidor ainda não está pronto. E assim vamos fazendo rollouts que geram baixo ou nenhum impacto dependendo do skill da aplicação.
Quando sua consciência desperta para a compreensão disso, você percebe que entre você e quase que 100% das aplicações que conhece, que são hospedadas na nuvem, há um proxy reverso entre vocês. Google, Globo.com, gago.io, Medium, não importa onde.
Um proxy reverso é útil por outros motivos também. Na medida que o hardware se torna mais barato, cada vez temos mais capacidade de processamento. . Em vez de termos 1 servidor para cada projeto, para cada nome. Usamos poucos servidores para hospedar diversos sites e aplicações. Um proxy reverso ajuda nessa tarefa. Permitindo distribuir a caga de trabalho de acordo com os cabeçalhos HTTP. Lembra do hostname que é passado no cabeçalho HTTP? Pois é. Ele é quem faz essa mágica.
Isso permite que seu servidor hospede diversas aplicações, que seja mais fácil lidar com SSL, distribuição de carga e todas as features que falei, a respeito de um proxy reverso.
Docker, Swarm e Kubernetes
Em workloads baseados em containers, é natural o aumentando da densidade computacional, aproveitando ociosidade dos nossos servidores.
Antes, o argumento para tantos servidores distintos e pequenos, era garantir a gestão e isolamento de forma a não permitir que aplicações causassem impacto uma nas outras.
Uma vez que essa solução (fragmentar em servidores) se torna datada com a chegada do Docker, queremos agora otimizar nossa capacidade computacional. Para isso, pré-alocamos aquilo que sabemos que é o mínimo, e alocamos dinamicamente aquilo que for necessário para atender workloads elásticos. Isso demanda clusterização.
No nosso caso, deixamos docker lidar com os IP’s de cada container. E portanto passamos a ter de lidar com resolução de nomes também dentro do cluster, para entender qual é o IP dos containers para o qual precisamos mediar a comunicação. Mas docker oferece essa feature para que você não tenha de lidar com isso.
Um exemplo real
Um request que chega aqui no gago.io começa da seguinte forma:
A autoridade responsável por meu DNS é o GoDaddy, nele eu tenho 2 apontamentos que dizem que o servidor DNS que responde por meu domínio está em no CloudFlare. O CloudFlare responde dizendo o IP (o ip de final 141, que você vê na imagem abaixo).
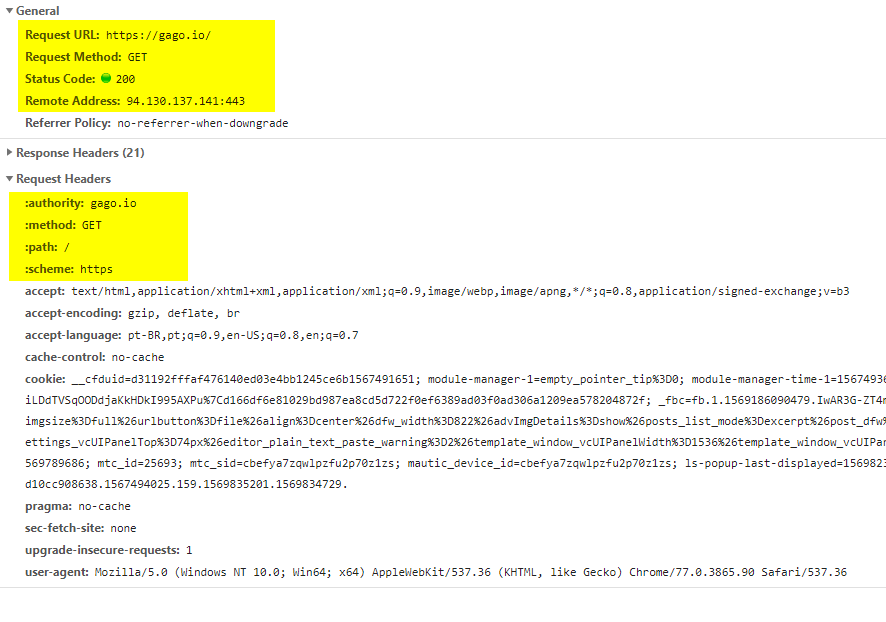
Como apresentei na live sobre NGINX, uso esse serviço como Edge da minha infraestrutura, ele recebe todas as requisições das portas 80 e 443 do meu servidor e distribui entre diversos containers.
Note que o nível de acoplamento entre o NGINX e o DNS é zero. Se eu quiser fazer uma configuração no NGINX antes do DNS, é perfeitamente possível. Não vai funcionar de forma fluida, pois eu precisaria nos clientes (desktops) configurar no hosts, essa resolução de nome manualmente. O pepel do DNS é responder o IP do nome informado, enquanto o papel do proxy reverso é saber lidar com esse nome. E se não souber, vai cair no site default, só isso.
No meu NGINX, tenho duas dezenas de sites configurados.
Esse NGINX de borda, eu chamo de EntryPoint. Seu papel é exclusivamente de roteamento e log.
Nas configurações do EntryPoint, eu informo que o site gago.io usa um certificado SSL, deve ser hospedado com HTTP2, e seu backend é outro serviço HTTP hospedado na porta 80 de um host gago_io. (Atenção para gago.io vs gago_io)
Enquanto meu EntryPoint é uma container NGINX, gago_io é um container wordpress, que por sua vez é baseado em uma imagem apache.
Como ambos estão conectados à mesma rede docker que possui resolução de nomes. Quando o NGINX tenta resolver gago_io, quem responde é a infra do docker, dizendo que o endereço gago_io é na verdade o IP dinâmico do container. E essa é a mágica para que eu não precise, nem deva lidar com IP’s de containers docker.
Aliás, lidar com IP’s, forçar IP X, Y ou Z em um container é uma prática muito ruim como disse em Don’t Do That – Forçar IP’s nos Containers Docker.
É assim que essa mágica acontece.
Nesse caso, no meu site, o certificado SSL está somente no NGINX. Toda comunicação entre o NGINX e o WordPress, é feita de forma não segura.
A título de curiosidade, outros sites são resolvidos e entregues com o mesmo NGINX. É o exemplo do sonar.oragon.io, oragon.io, jenkins.oragon.io, dockerdefinitivo.com, app.gago.io, id.gago.io e outros.
Vários desses links já não estão mais disponíveis ao serem removidos/descontinuados ou movidos/substituídos.
Aliás, app.gago.io é uma aplicação angular, fruto de um multistagebuild, em que o build é feito com node, produzindo um output html/js que é empacotado em uma imagem NGINX. Portanto nesse caso eu tenho um NGINX de proxy reverso e outro NGINX servindo o conteúdo estático.
Não há nada de errado nisso, muito pelo contrário! Era de se assustar se o NGINX que é proxy reverso, tivesse a responsabilidade de hospedar esse conteúdo.
Gostou do post?



Esse é um conteúdo que tem sido usado por professores e estudantes em universidades do Brasil. É parte do conteúdo que abordamos no Cloud Native .NET.
O entendimento desses componentes ajuda a entender o comportamento da sua aplicação, entender quais são as necessidades de deployment, principalmente em um mundo containerizado. Compreender quais são as responsabilidades de DNS, proxy reverso, API gateway poupa tempo e evita discussões sem sentido.
O Cloud Native .NET é a jornada que ajuda a dar clareza sobre esses elementos e muitos outros. Você entende e aprende a usar, na prática.
Aqui está a chance de você se destacar no processo de transformação digital e migração para Cloud Native.
Conclusão
Um proxy reverso é um mediador. Há diversos motivos e argumentos para você usar esse mediador.
NGINX (pronuncia-se “engine X”) é uma solução comum e recorrente como proxy reverso, mas nem de longe é o único. Há quem goste mais de HAProxy, Traefik, Envoy entre outros.
Na internet, hoje é difícil pensar em algum site ou aplicação que não use um proxy reverso. Hospedagens compartilhadas onde o custo da hospedagem é menor que de um IP?! Esses só são viáveis com o uso de proxy reverso.
Eu só apresentei soluções baseadas em software, mas existem soluções baseadas em hardware. Não pretendo abordar por estar muito distante do escopo da maioria de nós.





Caraca! Que explicação excelente!
Obrigado Giuliana
Explicação fantástica Luiz! Didática excelente!
Obrigado Renan!
Incrível a sua explicação. Muito obrigado.
Obrigado Rafael!!!
Parabéns! Excelente explicação… Abriu muito minha mente principalmente para entender melhor como o docker resolve os IP’s de containers docker.