
Talvez se lhe perguntarem como você anda de bicicleta ou como dirige possa lhe deixar constrangido(a). Pode até parecer uma pergunta quase impossível de se responder. Fato é que quanto mais habituados com a forma de lidar com alguma situação, menos pensamos sobre o processo que naturalmente realizamos. Uns chamam esse fenômeno de masterização, já literaturas sobre aprendizado citam esse fenômeno como um estágio chamado inconscientemente competente.
Isso também acontece atrás do teclado, ou simplesmente tomando decisões técnicas. E como preciso lidar com alguns dilemas, inclusive ser capaz de passar a diante o processo que uso para tomar decisões, usei um projeto novo para criar esse diário de bordo. Nele vou abordar tradeoffs e todo o round de decisões e por onde minhas preocupações passaram e principalmente, qual foi o pipeline que me ajudou a tomar decisões.
Como estamos falando de um exemplo real, preciso deixar claro o contexto para que possamos caminhar juntos.
Codiname Poltys
Esse projeto endereça as capacidades de um WebCrawler de nível corporativo. A primeira versão dele eu entreguei faz um ou dois anos, e trabalhava sob uma arquitetura de uma PoC. Serviu ao seu propósito, e agora sim, entra em fase de estruturação pra virar um projeto de fato escalável.
Na primeira versão, o que havia sido entregue era um Crawler que trabalhada do lado do Webserver, no mesmo servidor, abrindo janelas, e criando uma lambança só. Era uma PoC, e lembra o que eu disse sobre PoC’s em Uma PoC de Sucesso?
Ele serviu ao seu propósito, conquistou o cliente, mas agora precisa virar produto. E nesse projeto temos 2 escopos bem distintos.
Seus 2 escopos
A divisão de responsabilidades é simples, tenho 2 escopos quase que independentes.
CRUD
O primeiro escopo trata da gestão e manutenção de cadastros, eles dão vida ao projeto (pesquisas, dados a serem consultados, apresentação, etc) enfim, toda a burocracia de gerenciamento e apresentação de dados. Eu tenho poucas preocupações sobre essa parte.
Na UI a única coisa que me preocupa é o Designer e UX de quem cria esses scripts. Vou abordar a seguir.
CRAWLER
Sob a perspectiva de negócio
Sob a perspectiva de negócio é o crawler precisa ser operável por pessoas com pouco conhecimento de programação, por isso precisa ser intuitivo. Eu imagino interfaces de criaçào de scripts bem parecida como o diagrama abaixo. Imagino que cada caixinha dessas é uma ação:
- Navigate to Url
- Click
- Send Text
- Get Text
Embora eu não tenha detalhado, a versão anterior já tinha adapters para que o schema fosse um XML (um xml Oragon.Spring) com os steps. Mas diferente dessa nova implementação onde trabalharemos sob uma UI efetivamente drag-and-drop, na versão anterior quem operava a PoC para criar scripts, fazia-se com base em um editor de XML.
Já nessa nova versão será possível realizar debug, passo-a-passo nessa UI.
Nesse momento eu não sei como fazer isso, mas já pesquisei, e pesquisei por diversas vezes componentes que me ajudassem a construir interfaces assim. Entupir a cabeça com outros aspectos do projeto ajuda a ficar alerta sobre os problemas que uma decisão aqui, pode trazer lá na frente. É contra intuitivo pensar que quanto maior o flood na cabeça melhor.
Sim, estamos ativando o mesmo mecanismo que você usa quando quer trocar de carro, escolhe um modelo e pimba: Agora você passa a enxergar, magicamente aquele carro 6, 10 vezes mais do que até o dia anterior. Esse fenômeno é comum, e nada mudou, seu cérebro que passou a deixar de filtrar aquilo que você deliberadamente trouxe para a lista de relevância.
Com um problema técnico, o processo é o mesmo, traga a maior quantidade de elementos para a mesa, e para isso, faça o exercício de buscar um pouco sobre cada assunto, de forma a não se aprofundar muito em nenhum ( Assunto 1, Assunto 2, Assunto 3, Assunto 4). De forma cíclica, faça essas pesquisas, dê tempo para você mesmo assimilar como as coisas funcionam, como essas tecnologias se conectam. Não se afobe, não estamos buscando uma solução, estamos aqui, nessa fase, buscando possibilidades.
Esse processo te ajudará inclusive a melhorar suas pesquisas no google, e melhorará tua relação com o assunto. É um processo que exige dias, portanto nada de sair desesperado(a).
Já pelo aspecto técnico
O segundo escopo diz respeito crawler. O mecanismo em si. De cara, esse é o maior desafio para o projeto, é quem oferece maiores riscos e é preciso ter clareza sobre as possibilidades o quanto antes. Essa foi a parte que comecei atacando, pois precisava mitigar seus riscos e evitar que inviabilidade técnica acabasse com o projeto.
Entenda, não basta rodar o Chrome WebDriver junto com a aplicação web. A primeira versão fazia isso, mas era uma prova de conceito, seu papel era demonstrar a capacidade, sem preocupação com escalabilidade.
Essa abordagem em produção levaria menos de 1 dia para o do servidor IP ser bloqueado, portanto é preciso ter uma estratégia mais inteligente para realizar essa tarefa.
É preciso pensar em uma solução que entregue flexibilidade para que o projeto possa ser executado em qualquer nuvem, em qualquer player, inclusive e principalmente nos Data Centers menores.
Então desses pensamentos surgiu a ideia de rodar o Chrome WebDriver no Docker, como um container. Com uma aplicação .NET Core, como sidecar controlando tudo. Docker endereça o melhor dos mundos em portabilidade. Uma imagem/container roda em qualquer vendor, tanto CaaS, como PaaS e se precisar IaaS.
Outra decisão que eu já estava direcionado a tomar era evitar o Selenium Grid, e assim eu também conseguiria não somente impor novas políticas de segurança, mas possivelmente a capacidade de usar protocolos que me entreguem resiliência e flexibilidade, além da possibilidade de instrumentar o processo e coletar métricas e feedbacks de forma muito mais precisa do que com Selenium Grid.
Uma boa ideia, mas com impactos
Muito legal esse desenho de solução, onde eu entrego mais flexibilidade consigo endereçar diversos requisitos, mas agora eu acabo de aumentar o escopo do projeto. Esse desenho é muito flexível, mas eu não sou capaz de pré-determinar a quantidade de workers. Trabalhar com pré-alocação não é somente antiquado, como implica em consumir muito mais recursos do que de fato é necessário e talvez exija até intervenção humana. Assim concluí que essa flexibilidade tem um custo, a necessidade de um Controller/Scheduler/Manager que fizesse o meio de campo na criação de Workers.
Assim eu teria um Controller/Scheduler/Manager em cada nó de um cluster docker, ou no caso de implantações com orquestradores como Docker Swarm e Kubernetes, um para todo o cluster.
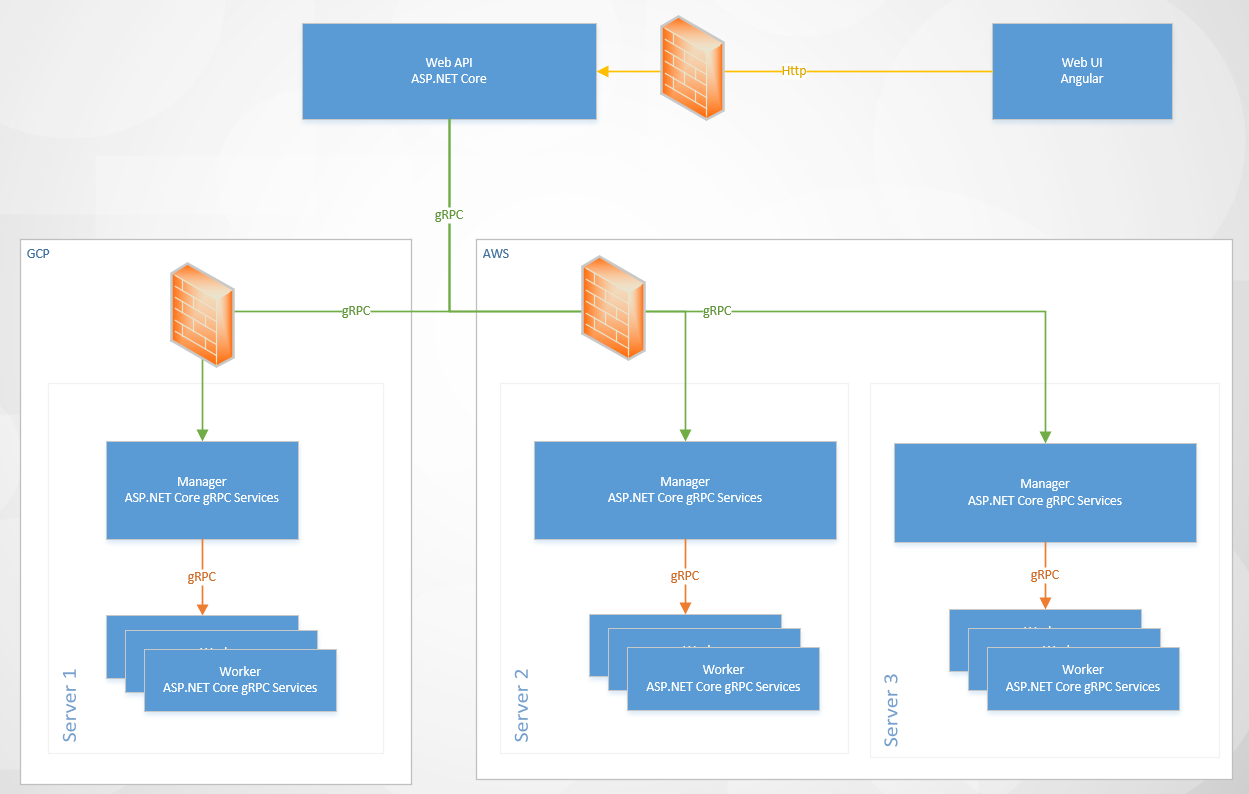
Ao primeiro olhar me senti desconfortável, mas como já havia trabalhado com a criação execução e descarte dinâmico de containers nos testes do Oragon Context (onde subo todos os principais SGDB’s como Oracle, PostgreSQL, MySQL e SQL Server em containers para testar minha integração com Docker, NHibernate, FluentNHibernate e Oragon), vislumbrei mais benefícios do que o aumento de escopo, principalmente por poder subir um worker, não somente como um container local, mas como um container CaaS, o que reduziria ainda mais os custos.
Uma solução nasce sem código algum
Isso tudo foi pensado sem colocar a mão no código. Começa com o estudo do WebDriver, depois entender se conseguimos usar WebDriver com .NET no Docker, e por aí vai, mentalmente cada tijolo de papelão, passa a ganhar solidez, mas ainda falta colocar a mão na massa para validar as partes mais complexas desse quebra-cabeça.
Todo o esforço de abstração e identificação de soluções e ofensores, ajuda a consolidar a solução, mesmo que ainda sem escrever uma linha de código. A tentativa de argumentar sobre outras possibilidades, como o uso de Kubernetes, ou Swarm ou algum orquestrador qualquer por exemplo. Ótimo, viável, no entanto me impossibilita realizar um deploy em IaaS ou ainda on premise, visto que a oferta mais viável para implantações de nível corporativo com Kubernetes ainda são lideradas pela Red Hat com o OpenShift e custa caro, muito caro!
Além disso tudo, eu precisava achar um protocolo eficiente para essa comunicação, então gRPC me pareceu adequado para essa empreitada, mas trazia também uma nova variável: desconhecimento prático.
O primeiro estágio de solidificação da solução acontece na sua cabeça
Então aos poucos, a ideia de ter um controlador criando e gerenciando workers deixou de ser algo complexo, para se tornar algo necessário para o escopo. E de cara, essa abordagem traz outros benefícios adjacentes, como a capacidade de entregar outros facilitadores como a configuração dinâmica de proxies (que não precisa estar presente na primeira versão) mas que pode se mostrar necessária mais à frente em um segundo roadmap de features para o projeto.
Viabilidade técnica
Eu não vejo problemas em soluções que são concebidas mentalmente apenas, sem nenhuma linha de código. Mas para isso quem o fez precisa conhecer com certo nível de profundidade cada elemento que irá compor a solução, bem como a forma como se comportam e se conectam uns nos outros. Precisa não só ter visto, lido em um livro ou assistido em um vídeo: Precisa ter feito, usado, vivenciado aquilo. Poucos são os conteúdos que mostram as dificuldades e instabilidades do dia-a-dia, eles só mostram o caminho feliz e precisamos lidar com realidades mais complexas no nosso dia-a-dia de projeto, portanto conhecimento prático é necessário.
Olhando para essa solução, alguns desses caminhos eu não havia percorrido ainda em minha jornada técnica. Então era hora de listar tudo que precisa ser testado para assegurar a viabilidade do que planejava.
Para entregar minha parte era necessário:
- ✅ Gerenciar Docker Dinamicamente
- ✅ Criar Redes dinamicamente
- ✅ Criar Containers com base em imagens pré-definidas
- ✅ Executar containers e monitorá-los
- ✅ Conectar aos containers
- ✅ Parar e Eliminar o container
- ❓ Rodar Selenium WebDriver no Docker
- ✅ .NET Core
- ✅ .NET Core + Docker
- ✅ .NET Core + Selenium
- ❓ .NET Core + Selenium + Docker
- ❓ Chrome Headless
- ❓ gRPC
- ❓ Hospedar serviços
- ❓ Consumir serviços
- ❓ Lidar com ciclo de vida dos serviços
- ❓ Impor segurança
✅ tudo que eu já havia feito, e ❓ o que eu ainda não havia feito.
Se eu resolvesse essas pendências, a solução deixaria de ser uma ideia para se tornar algo sólido, palpável, viável. Eu teria percorrido todos os caminhos desconhecidos e não só, mas adicionaria esse skill à minha bagagem, bem como demonstraria que aquilo que estava pensando era possível e viável.
Meu, novo, micro roadmap consistia em:
- ❓ Rodar Selenium WebDriver no Docker
- ❓ .NET Core + Selenium + Docker
- ❓ Chrome Headless
- ❓ gRPC
- ❓ Hospedar serviços
- ❓ Consumir serviços
- ❓ Lidar com ciclo de vida dos serviços
- ❓ Impor segurança
Como o gRPC seria usado para operar o Selenium Grid, eu comecei seguindo exatamente essa ordem, primeiro criando um console com o selenium, colocando em uma imagem docker, e subindo, programaticamente um fluxo simples.
O processo de criação dessa PoC seguiu o seguinte princípio:
- Criar o repositório no github e cloná-lo.
- Criar um projeto console chamado Playground, no qual eu pudesse fazer qualquer lambança em ambiente controlado.
- No projeto Playground implementei meio que de qualquer maneira a integração do .NET Core com o Selenium.
- Adicionei o suporte a docker, e revalidei.
Uma vez ok, era hora de sair da sandbox que era o projeto Playground.
Com um pouco mais de clareza sobre como essa integração funcionava, foi mais fácil vislumbrar como as coisas poderiam tomar forma.
- Criei um novo projeto, agora chamado de Worker, e esse sim, deveria ter o código adequado para a tarefa. E nesse projeto comecei a estruturar nosso acesso ao webdriver, agora de forma consistente e usando padrões onde fazia sentido. Como no caso da criação do webdriver, onde se fez necessário usar um factory.
- Ao passo que o que antes estava funcionando de forma rudimentar, agora estava funcionando de forma estruturada e no projeto adequado, havia espaço para algumas otimizações, mas optei para fazê-las mais tarde, pois ainda tinha o desafio de unir essa implementação com gRPC. A otimização era simples, eu queria que a imagem base já tivesse o chrome driver, já que é algo pesadinhho para levar em todo build.
- Assim, comecei a programar o primeiro serviço gRPC. Foi fácil, o novo template e o novo host gRPC sob o Kestrel tornam as coisas do jeitão Microsoft, fácil de usar.
- Do outro lado fui criando um cliente gRPC em outro console que chamei de ConsoleTest.
E assim passo a passo foi criando os primeiros contratos, e as primeiras chamadas remotas, e como num passe de mágica, sem nenhuma dor de cabeça as coisas funcionaram. gRPC + .NET Core + Selenium Drive + Chrome Headless.
E o serviço gRPC do worker que havia acabado de ser criado, foi ganhando implementações, esbarrei na necessidade de realizar Screenshots full page, descobri que o Chrome WebDriver não suporta plugins, mas consegui realizar o que queria com uma library (Noksa.WebDriver.ScreenshotsExtensions) com uma que um rapaz fez para .NET Framework, que em alguns minutos forkei o projeto e fiz um port para .NET Standard e publiquei no nuget.org. Sem crise, eu já abri o PR! Mas eu precisava do pacote publicado para continuar.
Nesse processo de trazer printscreens de páginas inteiras, foi necessário aumentar os limite de envio (do server) e de recebimento (do client), o que demandou fuçar o código-fonte do gRPC para entender como configurar algumas coisas. Disso acabei enviando o pull request PR12483 (que mais tarde virou PR12539) para Doc Microsoft.
Então ao final disso tudo, temos um Worker funcional e quase completo. E antes de nascer já sofreu alguns ciclos de refactoring. Sim, eu gosto de lapidar meu código na medida que as mudanças estruturais vão acabando, e elimino decisões ruins.
Decisões Ruins
Uma das decisões ruins que tomei, é relacionada a gRPC, onde eu queria aproveitar a infraestrutura de stream (algo praticamente único no nosso universo .NET) para entregar printscreens periódicos, mediante configuração no Request. Não obtive sucesso por conta do ciclo de vida dos serviços.
Por outro lado, eu estava pensando em deixar um contexto estático no program, imaginando que nosso serviço fosse ser recriado a cada chamada, mas não, ele tem um ciclo de vida longo e isso é muito interessante.
E entenda, nessa fase, as decisões não são escritas em pedras, elas são tão maleáveis quanto a distância entre pensamento e realidade. Eu trago premissas a cumprir, premissas frágeis e voláteis e premissas rígidas.
Não foi um tiro no escuro
Dois aspectos são fundamentais para dar vida à esse escopo. O primeiro ponto é que toda essa jornada não gastou mais de 32 horas. Levei mais ou menos uma semana e meia para chegar aqui.
A sorte que esteve ao meu lado, só me ajudou a ganhar tempo, ou pela assertividade ou pela facilidade de realizar coisas complexas com pouco esforço.
Eu já havia pesquisado sobre selenium rodando no Docker, o projeto Docker Selenium é um exemplo.
gRPC não era minha única opção, eu tinha a opção de usar ASP.NET Web API e RabbitMQ para isso. Inclusive teria um bom uso para o projeto Oragon.AspNetCore.Hosting.AMQP.
Conclusões
Nada disso é possível sem conhecimento, sem saber onde está se metendo. Conhecer boa parte das soluções me ajudou muito, pois o caminho para o resultado era menor, minha PoC era menor.
Outro ponto que faço muito nesses casos, é trabalhar sob lapidação de código. Uma primeira versão, para fins educativos tende a ser o mais objetivo possível em sua missão. Depois você adiciona elementos de design, entende como pode ser melhor consumido, como fica flexível, e vai trabalhando em busca do melhor desenho para o teu problema. Agora já não me envergonharia em mostrar o fonte, e embora novo, já é um código que está se mostrando estável e resiliente.
Óbvio que existem novos elementos do stack, principalmente a comunicação do worker com a API, pois essa precisa de alguns cuidados com segurança. Provavelmente chaves e id’s de controle, ou algo semelhante ao que o Swarm Master faz na sua instalação, criando uma URL que sirva para o Node se registrar no master, aqui poderia ser algo como uma url da API para que o Manager se registre na API e possa a partir de então receber demandas.
Note que já estou pensando no que é necessário para a próxima etapa.
Embora o resultado tenha sido positivo, e extremamente assertivo, isso nem sempre foi assim.
Outro ponto é que não há problema algum em você errar uma decisão mentalmente, enquanto ela está em fase embrionária, ela está aí para ser testada, colocada à prova. Eu não me envergonharia se a implementação da Microsoft para gRPC não me entregasse o que preciso ou se tivesse grandes problemas para o download do screenshot. Possivelmente eu usaria um outro recurso como um Redis, ou um Minio talvez, para entregar imagens de até 5mb, que é o caso de um screenshot de um produto específico.
Ter e conhecer recursos que farão o trabalho, de outra forma ou de forma complementar lhe ajuda a ter opções, ter flexibilidade, ajuda a lidar com as adversidades.
Ao final dessa fase eu estou seguro sobre minhas decisões, e agora temos um desenho mais consistente. Agora posso assinar com sangue!
Timeline
Faltou alguma coisa? Me conte!
Leitura recomendada
Leia mais sobre como eu tomo minhas decisões, temos o texto Como definir a Arquitetura de um Software (abaixo).

E temos também “O que eu uso” (abaixo)

Note que como esse projeto é um projeto técnico, no qual eu tenho total conhecimento sobre o domínio, de forma plena e absoluta, eu consigo tomar decisões de design das quais eu não conseguiria se estivesse imerso em um cenário de outro business, por exemplo. Assim é natural que toda a modelagem saia menos flat do que o proposto nesse texto (acima “O que eu uso”).
De acordo com a atividade é muito provável que surjam abstrações de abstrações, principalmente quando estiver modelando o backend que dará suporte ao diagrama.
Note que novamente eu estou planejando 2 etapas à frente.
Esse exercício me faz ter todas as variáveis na mesa na hora de tomar decisões, isso me permite lembrar das constraints que fazem com que algumas decisões sequer possam ser cogitadas.









Parabéns Luiz.
Como sempre trazendo conteúdos muito interessante e que despertam a forma de pensar.
O grande diferencial dos seus posts é: você não entrega a solução pronto, você ínsita o raciocínio!!!!
Obrigado Thiago!
Fico muito feliz quando recebo feedbacks de quem compreende o real sentido daquilo que produzo! Fico feliz que tenha percebido e que principalmente dê valor!
Muito obrigado!