
Uma das ferramentas que mudou minha carreira foi sem dúvidas o RabbitMQ.
RabbitMQ, embora tenha Coelho no nome, se comporta mais como um cavalo selvagem e arisco.
Mensageria, Aplicações assíncronas e Aplicações distribuídas são mais complexas, mas dão um poder que poucos no mercado conseguem compreender, e hoje quero trazer um pouco dessa experiência acumulada ao longo de uma década usando RabbitMQ em produção em projetos de todos os tamanhos.
Hoje é dia de falarmos de RabbitMQ.
O que são aplicações assíncronas?
Pense em uma chamada telefônica como uma operação síncrona.
Quando você faz uma ligação, a pessoa do outro lado precisa atender o telefone para a comunicação acontecer. Ambas as partes precisam estar disponíveis ao mesmo tempo, e entrar na conversa imediatamente. Se a pessoa que você está chamando não atender, a chamada falha e você tem que tentar novamente mais tarde.
Nesse cenário, você está bloqueado, esperando a resposta da outra pessoa. Isso é semelhante a como as operações síncronas funcionam na computação. Quando um pedido é feito, o sistema espera a resposta antes de seguir em frente.
Agora, vamos comparar isso com um SMS ou uma mensagem no Telegram, WhatsApp ou qualquer outro aplicativo de mensagens instantâneas. Quando você envia uma mensagem, não precisa esperar que a outra pessoa esteja disponível e responda imediatamente. Você pode continuar fazendo outras coisas e a pessoa pode responder à mensagem em seu próprio tempo. Se a pessoa não estiver disponível, a mensagem será entregue quando ela estiver. Isso é semelhante à maneira como as operações assíncronas funcionam. A requisição é enviada e o sistema continua a fazer outras coisas sem esperar pela resposta. Quando a resposta chega, ela é processada.
No contexto do RabbitMQ e mensageria, isso é como colocar uma mensagem na fila. Quando um serviço coloca uma mensagem na fila, ele não precisa esperar que o serviço de recebimento esteja pronto para processar a mensagem. Isso permite que o serviço de envio continue fazendo outras coisas. O serviço de recebimento pode pegar a mensagem da fila e processá-la quando estiver pronto.
Então, em resumo, uma chamada telefônica é como uma operação síncrona – você precisa de ambas as partes presentes e engajadas ao mesmo tempo. Um SMS ou uma mensagem em um aplicativo de mensagens instantâneas é como uma operação assíncrona – a mensagem pode ser enviada e a resposta pode vir depois, permitindo que ambas as partes operem em seu próprio ritmo.
O óbvio precisa ser dito
Essa analogia é óbvia e natural para a maioria.
Entretanto, esse desenho, permite que a aplicação que recebe a mensagem tenha a liberdade para estar offline. Completamente fora de operação.
Downtime Upgrade
Imagine que haja necessidade de upgrade de infra, ou troca de servidores, ou upgrade de um banco de dados. Ou ainda que seja um mero update da aplicação, onde o desenho escolhido seja o de paralisação completa, para em seguida aplicar o update.
Embora possa ser abominável para alguns, esse é o desenho mais simples e fácil, com o menor custo operacional e para o dia-a-dia dos times.
Portanto, esse é um desenho desejável, sempre que possível. Mas para ser possível, é necessário ter mecanismos assíncronos para conseguir fazer com que esse downtime não represente perdas para o negócio.
Rolling Upgrade
Imagine que você queira que sua aplicação ou serviço tenha zero downtime. Rolling Upgrade é o caminho natural para essa abordagem, onde a atualização é realizada gradualmente, sem interromper completamente a aplicação. Nesse caso, as instâncias da aplicação são atualizadas sequencialmente, uma por uma, enquanto as outras instâncias permanecem em funcionamento e atendendo aos usuários. Dessa forma, a aplicação fica disponível durante todo o processo de atualização, e o tempo de inatividade é minimizado ou até mesmo eliminado.
Ao conversar com times e gestores, essa parece ser
a estratégia óbvia
para deployment
Mas como tudo na vida, a imaturidade e falta de clareza faz com que queiram o não são capazes de entregar.
O preço a se pagar pelo Zero Downtime é maior do que uma configuração no pipeline.
Imagine que um banco de dados precisa ser alterado, e uma coluna nullable, passa a ser not null. Ou uma tabela precisa ser alterada em outro nível.
Você tem 10 instâncias da sua aplicação no ar, então começamos o rollout.
Temos 1 instância na versão 2 e 10 instancias na versão 1.
Essa nova versão faz as alterações em banco que mudam a estrutura de banco, de tal forma que a versão 1 é incompatível com o banco da versão 2.
Pronto, o resultado disso são 10 instâncias com algum tipo de falha, que não conhecem completamente a nova estrutura de banco, quebrando todos ou apenas um percentual dos requests, enquanto aquela nova instância é a única que sabe lidar com o novo estado do banco.
Uma solução? talvez adotar “Feature Toggle Deployment” ou “Feature Flag Deployment”.
Nessa abordagem, o deployment é dividido em duas etapas, cada uma habilitando uma parte específica da funcionalidade usando feature flags. Aqui está como funciona:
- Primeiro Deployment: Nessa fase, uma versão inicial da aplicação é implantada. No entanto, a nova funcionalidade é desabilitada por meio de uma feature flag. A feature flag é basicamente uma configuração que permite habilitar ou desabilitar uma funcionalidade específica em tempo de execução.
- Ativação da Feature Flag: Após a conclusão do primeiro deployment, a equipe de desenvolvimento pode ativar a feature flag, habilitando a nova funcionalidade apenas para um conjunto específico de usuários, como um grupo de testes ou uma parcela limitada da base de usuários.
- Testes e Monitoramento: Com a nova funcionalidade ativada para um subconjunto de usuários, é possível coletar feedback, realizar testes de desempenho e monitorar o comportamento da aplicação. Isso permite validar a funcionalidade em um ambiente de produção real, mas com um impacto limitado.
- Segundo Deployment: Após a fase de testes e validação, a equipe de desenvolvimento pode prosseguir com o segundo deployment, que consiste em implantar a funcionalidade para todos os usuários, com a feature flag ativada globalmente.
A principal vantagem dessa abordagem é permitir um lançamento gradual e controlado da funcionalidade, com a possibilidade de desativá-la rapidamente caso ocorra algum problema ou comportamento indesejado. Além disso, as feature flags também oferecem flexibilidade para ativar ou desativar a funcionalidade de forma granular, permitindo ajustes e experimentação contínua.
Essa estratégia é frequentemente usada para minimizar riscos e garantir que a nova funcionalidade seja lançada de forma segura, permitindo uma resposta ágil caso problemas sejam identificados.
Seu time tem maturidade para fazer isso? De alguma dessas formas?
Normalmente a resposta que tenho é um singelo e triste: não!
Então comece com Downtime Upgrade,
dê início ao uso de Feature Flags e
evolua seu nível de maturidade
para alcançar o tão sonhado
zero downtime.
Mensageiria vai te ajudar com falhas que possam ocorrer, RabbitMQ permitirá que você tenha filas de deadletter, de forma que erros no processamento podem ser corrigidos e reprocessados.
Isso é resiliência!
RabbitMQ é só para aplicações grandes? Bullshit!
Outra coisa que aprendi sobre RabbitMQ é que ele atende bem aplicações pequenas e médias. O exemplo acima trata exclusivamente o assunto resiliência.
Então o tamanho da aplicação não é relevante, mas nesse contexto caso, criticidade é.
Se a aplicação não é crítica, resiliência não é um problema tão grande.
Esse é o maior diferencial entre RabbitMQ e Kafka.
RabbitMQ se adéqua bem também em aplicações pequenas, é justificável, tem um deployment simples, e consegue fazer milagres sem cluster, semelhante ao seu banco de dados que também não é um cluster.
Exemplo do WebHook
Um tipo de aplicação super enxuta, porém crítica, são aplicações que recebem webhooks. Dependendo do serviço que envia os hooks, não é possível reenviar a mensagem.
Quando é possível, em geral, vemos e temos acesso a uma interface que sintetiza a implementação do pattern outbox.
Para entregar resiliência no recebimento de webhooks, você precisa assegurar algumas coisas. A primeira é que tudo para trás de sua aplicação pode capotar, estar offline, mas uma mínima infraestrutura nunca estará indisponível.
Com RabbitMQ e .NET, 2 coisas nunca estão indisponíveis nos meus webhooks:
- Aplicação .NET que recebe o Webhook
- RabbitMQ
Isso quer dizer que essa aplicação que recebe o webhook:
- Não tem e nem deveria ter nenhuma regra de negócio.
- Não sabe do que se trata o dado recebido, não é sequer capaz de avaliar se é válido.
- Não acessa banco de dados,
- Não possui código de negócio nem se conecta ao core do negócio.
As credenciais e autenticações são processadas pelo Kong. Pela natureza de Webhook, API KEY é sempre a opção mais viável, embora insegura.
Aliás, adotar API KEY não é uma escolha minha, a maioria dos serviços que enviam hooks não possuem configuração adicional para um fluxo de autenticação. A maioria só tem uma caixa de texto para você colar uma url. Assim, a API Key muitas vezes será enviada na QueryString.
Conviva com isso, você não tem escolha. É o típico: Aceita que dói menos.
Meus webhooks aqui sofrem alteração 1 vez a cada 2 anos. O papel da aplicação web é receber um request HTTP já autenticado, e colocar em uma fila, com muitas informações do request, e obviamente o body da requisição. Sequer o formato do dado é tratado no webhook. Se for enviado um formato inválido, não há absolutamente nenhuma trava para isso.
Não acessar bancos de dados, não validar as estruturas, só receber e colocar em uma fila, me permite ter um serviço com estabilidade infinita, e manutenção mínima. Isso me dá segurança para manter um serviço sem necessidade de manutenção por 2, 3, 5, talvez até 10 anos… Adicionando novos webhooks pelo caminho, mas não precisando reimplantar a aplicação para isso.
A chave para o dinamismo está no uso do path da chamada, como routing key. Isso permite que novas integrações por webhook sejam criadas precisando apenas:
- No Kong
- Gerar uma nova API KEY para a nova integração.
- No RabbitMQ
- Adicionar uma fila que receberá o novo dado.
- Adicionar um bind entre a exchange do webhook e essa fila
- No banco de dados
- Nada
- Na aplicação que recebe o webhook
- Nada
- Outras necessidades
- Com base na engenharia reversa, descobrir a URL que produz a routing key exata que quero receber a mensagem para a nova integração.
- Configurar essa url com a API KEY certa no parceiro de integração.
A estabilidade dessa solução depende da falta de acoplamento entre essa aplicação e o core de negócio. Não realizar sequer uma pequena consulta em banco me dá capacidade computacional alta, e estabilidade que beira o infinito.
O rota no Kong depende da aplicação web, a aplicação web só depende do RabbitMQ, FIM.
Estamos falando de 1 endpoint genérico em 1 Controller Web API (que na próxima revisão se tornará minimal API)
Conhece muitos projetos menores que esse?
Esse é mais um caso:
absurdamente pequeno,
e incrivelmente crítico!
Single node ou Cluster? IaaS ou PaaS?
RabbitMQ nasceu sem a possibilidade de clustering. A maioria dos deployments que conheço não são clusterizados.
Mas fato que isso gera um single point of failure, e como arquiteto não podemos deixar isso acontecer certo?
Errado!
Se estamos falando de aplicações de todos os níveis de maturidade, de todos os tamanhos, vamos esbarrar em cenários onde a empresa não tem maturidade para lidar com clusters anyway.
O que descobri é que muita gente quer usar o RabbitMQ em cluster, enquanto sequer seu banco de dados está em cluster.
Isso significa não haver ninguém na empresa com experiência em administrar clusters. E trazer esse ônus, logo para o RabbitMQ, é uma forma excelente de começar com “os dois pés esquerdos”.
Ao mesmo tempo, temos empresas mais maduras, onde o banco de dados é PaaS ou mesmo que seja implantado com IaaS, possui cluster. Como lidar com isso? Com um único server? nunca!!!!
Para conseguir atender esses 2 extremos, minha recomendação para alunos do Mensageria .NET (meu curso de RabbitMQ para desenvolvedores .NET) é:
Mimetize o banco de dados.
Se o banco de dados é uma única instância em um servidor compartilhado com outras coisas, você pode fazer o mesmo com RabbitMQ, é isso que esperam de você.
Se o banco de dados é uma única instância em um servidor dedicado, também busque um servidor dedicado para colocar uma única instância.
Se o banco de dados é PaaS, busque uma oferta PaaS (mesmo que não seja exatamente o RabbitMQ, pode ser o Azure Service Bus, ele é diferente, algumas decisões atrapalham, mas será uma boa escolha). Pode ser o CloudAMQP, se exchanegs forem muito importantes para você.
Se o banco de dados é um cluster IaaS, faça o mesmo, monte um cluster IaaS com RabbitMQ.
A quantidade de nós de um cluster de banco não interfere na escolha da quantidade de nós do RabbitMQ. Minha escolhe por copiar a estratégia de banco para no fato de haver ou não um cluster, haver ou não isolamento.
Olhar para o banco de dados entregará de bandeja o nível de maturidade da TI da empresa. E esse nível de maturidade é fundamental para conseguir projetar sob medida.
O risco de projetar um cluster para uma empresa que não tem ninguém com experiência em cluster, é que uma hora ou outra, vão fazer tudo parar, sem skill para sequer entender o que está ocorrendo.
Como resultado: vão culpar você e/ou o RabbitMQ.
O risco de projetar um single node para uma empresa cujo banco de dados está em cluster é entregar um single point of failure, e assim seu trabalho é depreciado porque você adicionou um ponto único de falha em um ambiente redundante.
O risco de subir um RabbitMQ com IaaS em uma empresa que adota como padrão bancos de dados PaaS, é dar a ela um passivo (a infra) que ela não quer ter.
Então minha receita de bolo é: copie a estratégia usada para banco de dados!
Nunca será demais, nunca será de menos.
Dia 2: Seja claro e transparente sobre sua intenção de sugerir A, B ou C. Explique o motivo que levou a adotar tal estratégia. Compartilhe essa decisão e explique o argumento para tal escolha. Caso haja alguma divergência nas expectativas, é nessa hora que o feedback será dado.
Obs: Se RabbitMQ for empregado para resiliência, ele tem tanta importância quanto o banco de dados.
Se você quer escala, esteja disposto a pagar por ela
O sonho de muitos desenvolvedores é que seu software escale.
Meu deus, é tudo que eu não quero.
Atrás, do lado e às vezes até na frente da escala, vem o custo.
É claro que quero que meu software consiga escalar,
se necessário,
mas quero que não precise escalar.
Vamos, a partir dessa imagem, trabalhar em um exemplo.
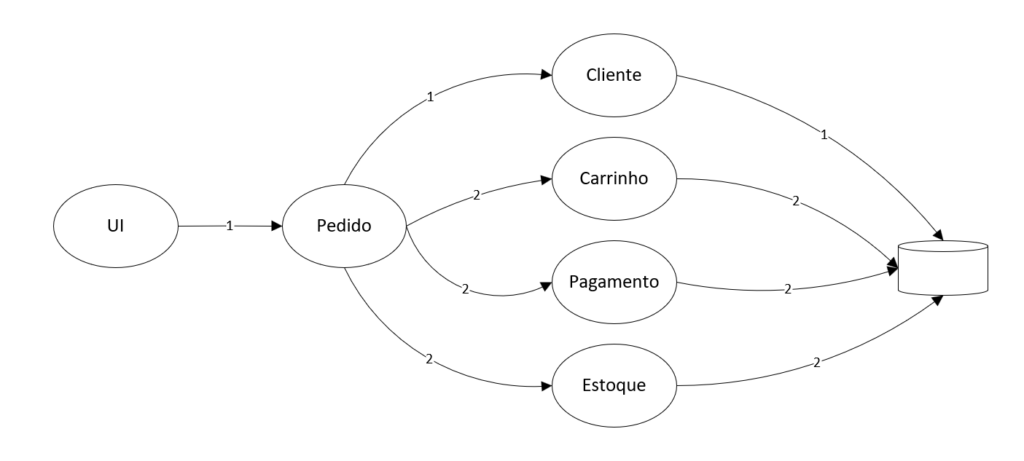
Proponho um exemplo minimalista, onde para cada pedido, temos 7 chamadas de API, onde cada chamada de API realiza 1 operação em banco. Assim, a cada pedido também realizamos 7 operações em banco.
Isso se traduz na seguinte tabela

Esse é um exemplo de pedido, mas poderia ser outro assunto qualquer.
Agora imagine que estamos falando de 100 operações por segundo, como na faixa azul da tabela abaixo.

Para atender 100 pedidos por segundo, minha infra precisa suportar 700 chamadas de API por segundo, e 700 operações em banco por segundo.
Esse volume gera 360.000 pedidos por hora, e um total de 2.5 milhões de operações no banco.
Se quer entender onde isso pode chegar, a tabela abaixo pode te dar uma noção.
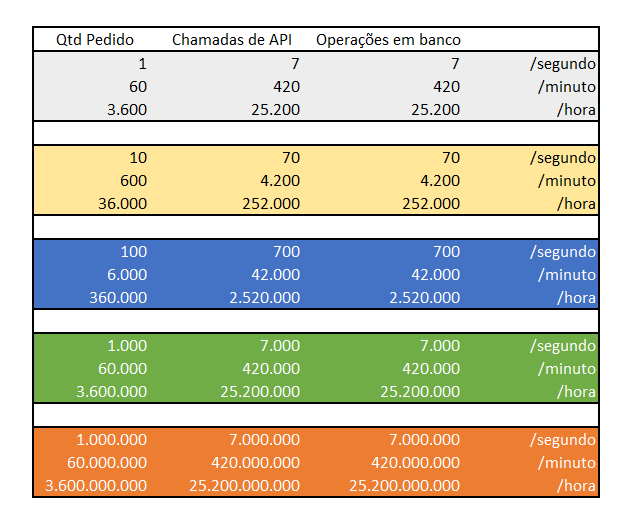
Embora esse número pareça absurdo para pedidos, é a realidade de algumas empresas.
A VTEX, hoje unicórnio, da qual trabalhei lá quando ainda era uma pequena startup, planejava atender 1000 pedidos por minuto em 2020, para um único cliente do seu SaaS.
Mil pedidos por minuto: planejamento e arquitetura de pico no varejo
Os dois primeiros dias livres de impostos ocorreram em 19 de junho e 3 de julho de 2020. Os pedidos e sessões do Grupo Éxito dispararam, atingindo mais de mil pedidos por minuto. Acomodar uma quantidade sem precedentes de transações em tão curto prazo representou um desafio para o varejista médio da Colômbia. Uma das principais preocupações de todo varejista online durante eventos de alto tráfego é a capacidade da plataforma e seu tempo de recuperação em caso de falhas.
O site do Éxito é alimentado pelo VTEX IO, a plataforma de desenvolvimento sem servidor da VTEX, que por sua vez é construído na AWS. Este esquema de interdependências, no qual a AWS fornece à VTEX os recursos em nuvem certos para responder às demandas de negócios online do Éxito, fez com que o processo de preparação e vendas durante o evento fosse tranquilo e sem falhas. A chave para essa conquista foi a escalabilidade.
https://aws.amazon.com/pt/blogs/aws-brasil/mil-pedidos-por-minuto-planejamento-e-arquitetura-de-pico-no-varejo/
Estamos falando de apenas 1 cliente.
O problema da escala é que
a demanda cresce de forma linear,
enquanto o custo cresce de forma exponencial.
O gráfico abaixo mostra é uma ilustração para o assunto.
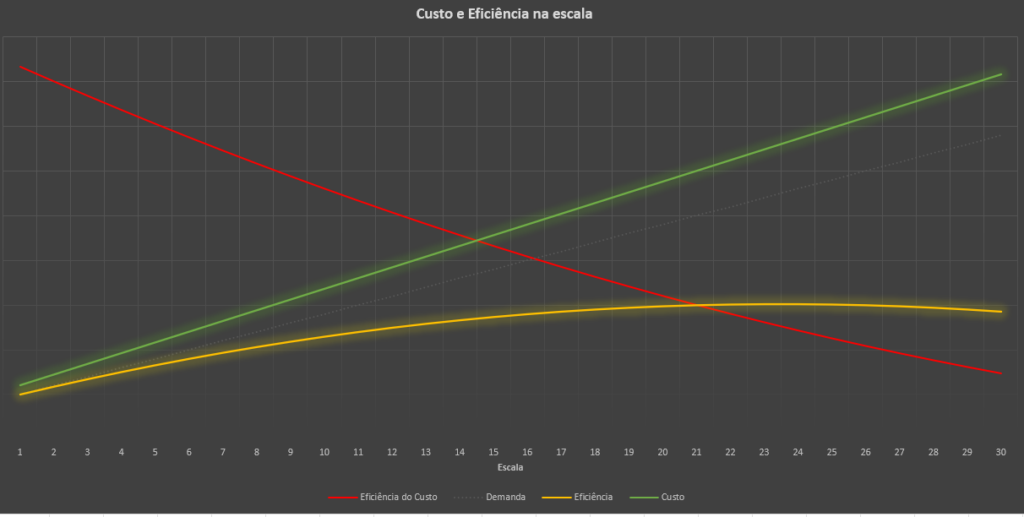
Ele descreve a relação entre eficiência e custo em cenários de escala.
Uma linha cinza, pontilhada e fraca, mostra o crescimento da demanda. A linha verde, apresenta a evolução do custo, na medida que a escala acontece.
Note que diferente do que disse na chamada em vermelho, o custo é linear. Mas calma que em breve você entenderá.
Assim, se temos X hardware, custa Y, enquanto se temos 10 X hardware, nos custa 10 Y.
Aqui mora um problema: Considerar força computacional (hardware), semelhante à capacidade de processamento.
Esse escorregão acontece quando desconsideramos saturação e sobrecarga.
Ao desprezarmos saturação e sobrecarga, ignoramos a eficiência do investimento.
A lei de Amdahl é um bom ponto de partida para entender os modelos matemáticos que tocam nesse tema. A lei aborda capacidade de paralelismo.
Mas o que eu trouxe aqui não é um modelo matemático, é um esboço do que experimentei em 10 anos de experiência com aplicações distribuídas.
O grande problema a ser considerado é a existência de um ponto de saturação. Onde uma vez alcançado, notaremos que o aumento do paralelismo, gera redução na capacidade de processamento.
Encontramos esse fenômeno escalando um único componente, ou um sistema inteiro. O grande diferencial é que ao escalarmos mais partes, reconfiguramos esse gráfico e voltamos para os pontos iniciais.
Então, ao chegarmos ao ponto de saturação do nosso serviço de Pedidos, precisamos entender quem está impactando a evolução e possivelmente precisamos escalar outros serviços, como cliente, carrinho, pagamento, ou Estoque. E provavelmente, com essa demanda, o banco de dados também.
E aí, teremos um custo exponencial.
Isso porque a eficiência do gasto é degradada pela própria escala, que afeta rede, banco, serviços auxiliares, métricas e observabilidade etc.
Então a melhor solução, é conseguir escalar e não esbarrar em limitações técnicas que impeçam a escala. Entretanto, o melhor dos mundos está em não precisar arcar com os custos da escala.
Mas tem solução?
Sim, com certeza tem solução, e é como começarei o próximo post dessa série.
Mas dessa vez conto com a sua ajuda.
Estamos com 4k inscritos no youtube e 1.4k no instagram
go.gago.io/youtube | go.gago.io/instagram
A parte 2 está pronta e eu liberarei quando alcançarmos 4.5k no youtube ou 2k no instagram.
Que comecem os jogos!






0 comentários