
Service Discovery é a capacidade que trata da descoberta de serviços em uma rede. É um elemento fundamental no dia-a-dia de quem trabalha com MicroServices, mas também pode ser usado por qualquer um que precise de algum dinamismo na descoberta de serviços. Além do Consul, que abordarei hoje, temos etcd, ZooKeeper. Mas escolhi falar um pouco sobre o Consul por causa do seu DNS interno, e o que vou apresentar hoje utiliza basicamente essa implementação, por ser algo simples, e retrocompatível.
O que faremos e falaremos?
A dinâmica que usaremos aqui é a seguinte: Vou dar um overview sobre o Consul, mas vou explorar seu DNS em um exemplo super legal. As demais features eu deixo deixo a cargo da documentação, e já adianto: Tem muita coisa legal e merece pelo menos uma visita, para conhecer.
Overview
A descoberta de serviços é um recurso interessante em ambientes distribuídos pois adiciona um repositório que armazena informações sobre onde estão seus serviços. Assim você tem um ponto central para registar cada novo endpoint, evitando o caos da gestão e ciclo de vida desse tipo de configuração configuração. Em contrapartida, você precisa consultá-lo, ou ser notificado sobre mudanças, tudo vai depender das features do Service Discovery que você escolheu. Essas mudanças ocorrem quando novos workers nascem ou morrem, e esse processo pode se dar por diversos motivos, desde aumento de escala de processamento até simples demandas de atualização de versão de produto. Há motivos para criar e eliminar instâncias dos seus serviços, mas garantir que esse processo aconteça sem gerar indisponibilidade é um dos desafios que um service discovery pode ajudar.
Novos tempos, velhos problemas
O Consul é uma implementação de Service Discovery desenvolvido pela HashiCorp. Assim como as principais implementações de mercado, é um NoSQL database baseado em chave/valor, desenvolvido para alta disponibilidade e confiabilidade. No entanto o Consul tem uma feature que me chama a atenção e preciso voltar no tempo para falar sobre decisões tomadas quando possivelmente você sequer era nascido(a).
Embora service discovery possa parecer um termo novo, esse é um problema muito, mas muito antigo. Mais precisamente da década de 80. Naquela época os hosts já eram endereçados por IP’s e as tabelas de hosts eram necessárias, em cada terminal, para determinar nomes amigáveis para os IP’s conhecidos. Somente em 1984 nasce o DNS ou Domain Name System, um banco de dados distribuído dedicado ao armazenamento de domínios e IP’s com um protocolo de resolução extremamente simples. Uma forma inteligente de resolver a questão, usada mundialmente desde então, e hoje é alicerce da internet que conhecemos. Já chega à metade de sua terceira década, sem depreciar-se com o tempo. Nesse desenho, servidores encadeados possuem autoridade sobre nós de uma hierarquia de nomes. Proprietários desses nós podem gerenciar somente nomes sob o seu domínio e assim suscetivamente temos uma cadeia de hierarquia e responsabilidades, consultável por qualquer dispositivo. Esse modelo é usado na internet e em empresas e continuará sendo usado por muitos anos.
As nossas demandas por service discovery se assemelham muito com as questões que levaram à criação do DNS, principalmente se isolarmos o prisma funcional sob a questão. E justamente essa é uma feature diferencial no Consul sob os demais concorrentes: seu DNS interno. Essa capacidade é fantástica pois você pode usar a tecnologia presente em qualquer dispositivo, presente na internet, consolidada por mais de 30 anos, em seu ambiente, já, com pouco esforço para o setup do serviço, pouco (ou nenhum) esforço de configuração dos clientes e nenhum esforço de codificação.
Vale lembrar que o DNS é apenas uma das features do Consul, há muito mais a abordar.
Hands On
Vamos subir uma instância do Consul usando Docker. Será uma instância standalone, com Web UI e DNS. O DNS será configurado para não somente responder pelos endereços *.consul, mas também para ser proxy para o DNS do google. Assim, vamos subir um segundo container e fazer algumas queries para obter informações de domínios nossos e hospedados pelo google.
Tudo pronto? Vamos precisar de algum bash, pode ser o do git mesmo.
Abra um instância do bash e execute:
docker run \ --rm \ --name=consul \ -p 8500:8500 \ -p 8300:8300 \ -p 53:53 \ --privileged \ -e 'CONSUL_ALLOW_PRIVILEGED_PORTS=' \ consul \ agent -dev -ui -client=0.0.0.0 -dns-port=53 -recursor=8.8.8.8
Agora temos uma instância do Consul configurada para rodar em modo standalone, ela está com o DNS respondendo na porta 53 (porta padrão), e também faz propagação com os DNS’s do Google, possibilitando que esse dns entregue qualquer domínio, inclusive os que estão fora do escopo do Consul.
Em uma segunda janela do bash, obtenha o IP do Consul executando o seguinte comando:
docker inspect consul --format '{{ .NetworkSettings.IPAddress }}'
O resultado será um IP, provavelmente 172.17.0.XX.
Agora usando essa mesma janela do bash, execute o seguinte comando:
docker run --rm -it --link=consul:dns --dns=<ip do consul> busybox
Agora acabamos de criar uma instância do busybox, configurada para usar o DNS que disponibilizamos através do Consul no primeiro passo.
As duas instâncias do bash continuarão presas, cada uma com um container. A primeira com o consul enquanto a segunda está alocada com o busybox.
Quando usamos o parâmetro -ui na criação do Consul, estamos pedindo para que ele também inicialize a interface de administração. Essa interface fica disponível por padrão na porta 8500.
Abra o browser em http://localhost:8500/ui/ você verá algo semelhante à imagem abaixo:
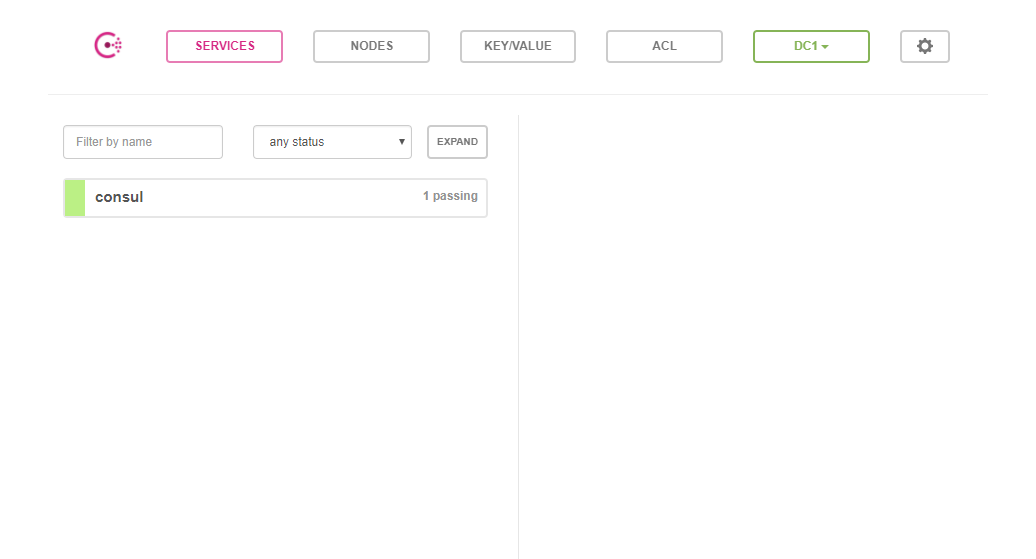
Agora vamos enviar um request HTTP para a API do Consul para registrar um novo serviço (use uma terceira janela do bash):
curl -i -X PUT \
-H "Content-Type:application/json" \
-d \
'{
"Datacenter": "dc1",
"Node": "app2",
"Address": "microsoft.com",
"Service": {
"Service": "oragon",
"Port": 80
}
}' \
'http://127.0.0.1:8500/v1/catalog/register'
Os elementos necessários para configuração são simples:
- Node: Destinado ao nome único da instância que você está criando.
- Address: Endereço ou nome para resolução
- Service: Nome lógico para o serviço.
Se você atualizar a página no browser verá a seguinte mudança:
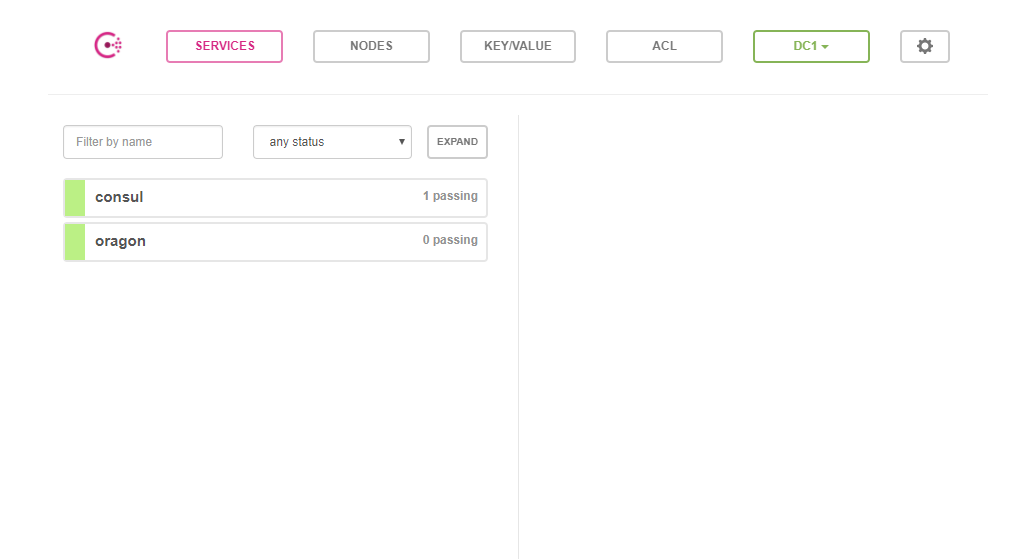
Agora você pode usar aquela segunda janela, do bash, onde executamos o busybox para fazer testes:
nslookup oragon.service.consul
A sentença é simples: <NomeServico>.service.consul
O resultado é simples, mas apresenta o potencial da solução.
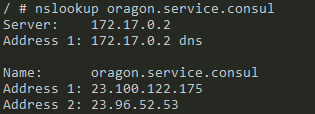
No meu exemplo, usei o domínio da Microsoft para a resolução, mas poderia ser o nome de um container na mesma rede docker. Outro ponto interessante é que se adicionarmos um segundo nó (node) para o mesmo serviço (service), teremos uma implementação de Round Robin, no DNS, algo que facilita a distribuição de carga.
Como o Consul está configurado com o IP dos DNS’s do Google (8.8.8.8) no parâmetro “recursor”, então ele é capaz de resolver nomes que não estão nas configurações internas dele. Acredito que haja alguma implicação em performance, é importante rever a documentação do produto para entender melhor isso.
Bom, além da api /v1/catalog/register, temos o /v1/catalog/deregister para o processo inverso:
curl -i -X PUT \
-H "X-Consul-Token:abcd1234a" \
-H "Content-Type:application/json" \
-d \
'{
"Datacenter": "dc1",
"Node": "app2"
}' \
'http://127.0.0.1:8500/v1/catalog/deregister'
Tem muito mais assunto pra falar sobre Consul, mas vamos deixar isso para outro momento.
Conclusão
Ainda tenho muito a desvendar sobre o Consul. Conhecer testar melhor, enfim, vivenciar a experiência de service discovery na prática. Mas com o que vi e apresentei aqui já é possível extrair ótimos resultados.






0 comentários