
Inúmeras vezes eu apresento o Enterprise Application Log e instantaneamente aparece alguém tentando “defender” o Application Insights, como se de alguma forma eu estivesse cometendo uma heresia ao propor qualquer outra coisa.
O mais curioso é que essa comparação é superficial e infundada.
Hoje vamos entender a estratégia por trás do Enterprise Application Log, vamos entender porque Application Insights não foi chamado para a festa.
Presumo que você já conheça o Application Insights do Azure, portanto não vou defini-lo, vou apenas expor as comparações que preciso, e principalmente, entregando o contexto no qual eu aplico.
Senão, eu convido você a pesquisar sobre os posts e lives do Renato Groffe. Ele fala bastante do Application Insights.
A ignorante comparação entre Enterprise Application Log e Application Insights
O principal ponto a respeito dessa comparação descabida não está em nenhum dos dois produtos.
O elemento mais importante é totalmente negligenciado, trata-se da estratégia:
- Quando logar?
- Quais dados precisam estar presentes em uma mesma entrada de log?
- Quais dados técnicos?
- Quais dados de negócio?
- Quais são nossos objetivos com esse log?
- Uma vez produzido o log, como ele será visualizado?
- Quem visualizará?
- Quais visões simplificadas podemos entregar para esses interessados que darão mais clareza e transparência sobre o dia-a-dia?
- Quais visões tem poder de influenciar o roadmap do produto?
Presumir que enviar uma string “Enviando email para {email}” ou “Passei por aqui” é logar, é quase uma heresia! Note que estamos falando de elementos que vão muito mais além do produto que escolhemos. A questão é que essas perguntas vão direcionando nossas respostas ao ponto de descartarmos produtos que impeçam ou dificultem a realização dos nossos interesses.
Para isso, precisamos saber o que queremos! E isso vou deixar para o final.
A escolha da ferramenta é uma decisão secundária, decorrente das implicações da estratégia.
Algumas dessas respostas irão exigir outra solução que não o Application Insights. Mas não se apresse em achar que estamos “jogando fora” o Application Insights, ou que vamos removê-lo da solução por causa do Enterprise Application Log.
São coisas diferentes, propostas diferentes.
Nossa estratégia está mais interessada em negócio e tecnologia enquanto o Application Insights tem foco no Desenvolvimento e DevOps, segundo a documentação oficial.
O que é o Enterprise Application Log?
Enterprise Application Log é um stack que montei para a centralização de logs. Ele parte do ELK stack (ElasticSearch, LogStash e Kibana), com a adição do RabbitMQ.
Na superfície é isso que ele é, um centralizador, consolidador, agregador de logs; Chame como quiser!
A estratégia por trás do seu uso prevê que seja mesclado em uma única entrada de log, dados de negócio (id’s, nomes, tipos, valores) com dados técnicos (cluster, nó, pod, container, processo, método, tempo de processamento, data, transaction id, bytes, versão da aplicação etc).
Uma única entrada de log, contendo informações de negócio e dados técnicos.
A maioria dos desenvolvedores que já tiveram contato com a solução sequer fazem ideia do que é possível. Muitos implantaram em seus projetos há anos. E ainda não extraem absolutamente nada dela.
A parte tecnológica, o produto em si, é legalzinho. Nos dá potencial de irmos muito longe e muito alto. Mas é a estratégia que move a engrenagem.
É a estratégia que dá vida ao projeto e justifica a adoção.
É o que podemos fazer com a ferramenta.
É o que podemos fazer a partir desses dados.
A escolha do ELK Stack se deu por ser prático, por eu conseguir empacotar a solução em um docker-compose simples de subir e conseguir entregar toda a parte tecnológica da coisa de forma fácil e prática.
A intenção é que você possa experimentar em casa, só você e computador.
Mas poderia ser qualquer solução que permitisse endereçar esses pontos. Acredito que deva existir mais umas 40 soluções que se encaixariam perfeitmente nesse papel. Application Insights não é uma delas, porque não é flexível o suficiente. Acredito que somado ao Power BI talvez dê para fazer pelo menos mais próximo do ideal.
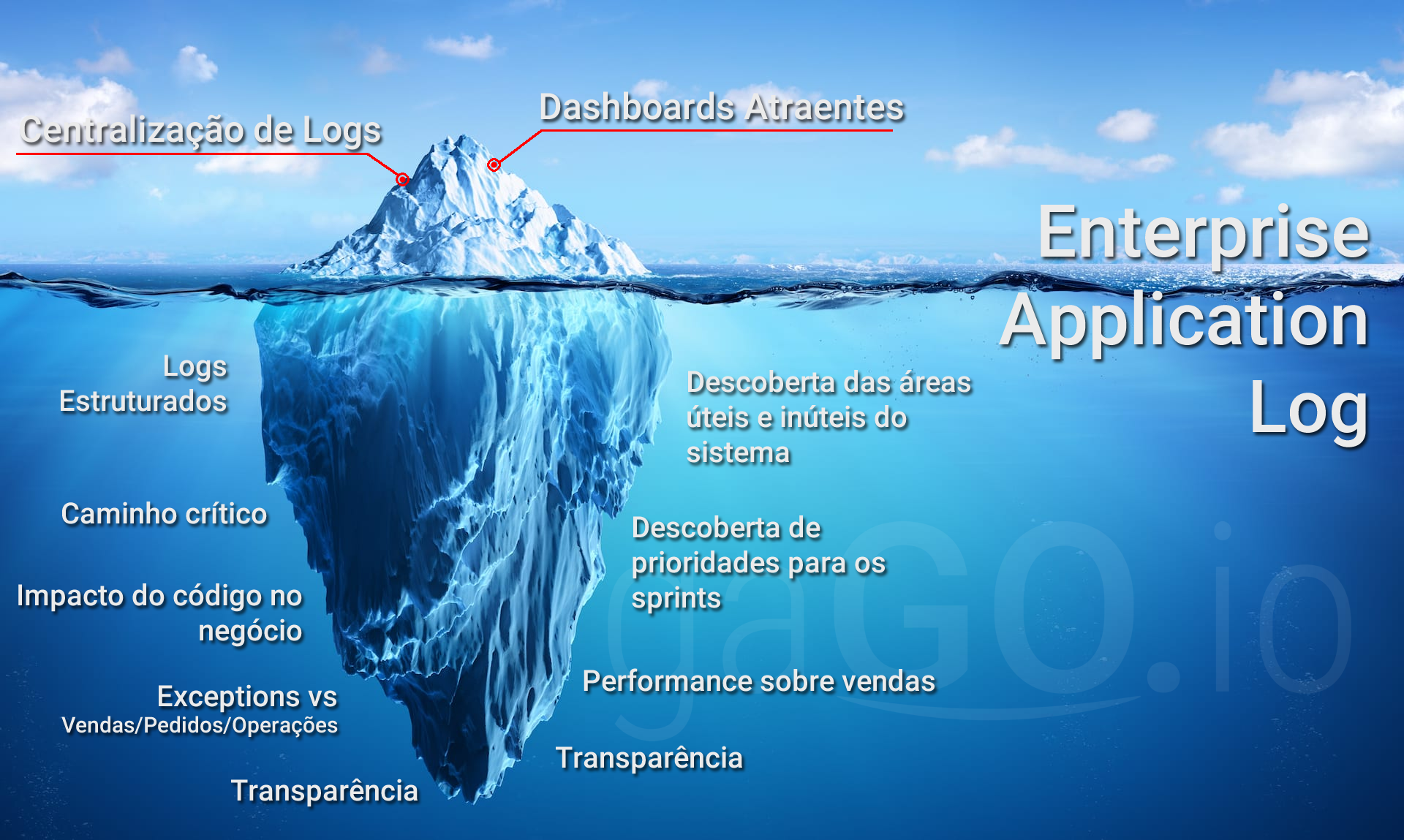
A imagem acima ilustra o que as pessoas querem enxergar e o que elas de fato têm.
A história
Em 2013 eu estava em uma restruturação. Dessa vez eu tinha autonomia, mas precisava a todo custo remover o acesso aos servidores de produção. Primeiro pelo ponto de vista de cultura. Era normal o time de desenvolvimento se pendurar no servidor para ver logs, para rodar aplicações (sim, com Visual Studio e tudo).
Como não havia gestão e nenhuma política, era um show de horrores. Projeto em que o fonte só existia no tal servidor, longe do SVN, na época.
Centralizar logs é interessante pois permite que o time trabalhe de forma proativa, recebendo e tratando os erros antes que eles virem problemas.
O comportamento humano diante de erros sistêmicos
Algo muito importante a se ressaltar, é que você toma erros em aplicações e aplicativos algumas vezes por ano. Mas dificilmente abre algum tipo de chamado, ticket, issue para a empresa do qual o aplicativo causou problemas.
Eu, você, e a maioria das pessoas que eu conheço ignoram e tentam novamente instantes depois, sob um contexto diferente ou deixam para mais tarde ou outro dia.
Pois bem, os chamados que recebemos em geral ocorrem depois de um usuário estar muito chateado, comumente por precisar muito daquele serviço ou atividade, ao ponto de gerar algum nível de dependência.
Um mesmo erro, não percebido, por muito tempo, tende a gerar evasão quando não há essa relação de dependência.
No ambiente corporativo, o processo é diferente: Tudo começa com o boca-a-boca falando mal do sistema com problemas. Logo logo isso via um problema político. Um belo dia, o gerente do usuário entra em contato com TI para abrir um chamado, e quando isso acontece… o caldo já está derramado.
Esse tipo de coisa gera stress e tensão desnecessários, e boa parte das tarefas que atropelam nosso dia-a-dia, vêm desse tipo de situação. Só que em vez de ser algo em que você conseguiria planejar e dar tempo adequado, agora é uma emergência com restrição de tempo e mal dá para “dar um tapa” em vez de solucionar de fato o problema.
A importância do monitoramento proativo
Monitorar seu log de forma proativa, buscando erros de maior incidência, é uma parte importante do processo de maturidade de qualquer software com uma base significativa de usuários. Ou que pelo menos se importe com eles.
Mas como ser proativo se seu log está em um servidor, dentro de um arquivo texto, que você pode fazer buscas mas no final das contas não diz nada?
Eu não sei o que é pior:
- Estar inacessível
- Estar em texto simples
- Não dizer nada relevante
É nessa ferida que estratégias de centralização de log atuam. E é aqui em especial que a minha visão sobre logs de uma parte do mercado. Só uma parte.
Voltando à história
Eu pude perceber o efeito nocivo das reclamações e bugs simples, que pareciam elefantes na sala. Da mesma forma como vivenciei situações em que, uma coisa simples, que levaria um ou dois dias para ser corrigido de forma eficaz e eficiente, agora tinha de ser solucionado em 2 ou 3 horas no máximo. Óbvio penalizando qualidade e qualquer estratégia de design.
É Go Horse o nome disso? hehehe
E não me venha falando em testes! Vou enfiar os testes na tua orelha! Nada tinha testes naquele momento. E pra falar a verdade havia muito ainda que sequer versionado estava. Era início da minha jornada na empresa.
Entender esse fenômeno, que na prática só se repetia, me fez entender que era necessário ser proativo. Afinal se quando chegava aqui, a batata já estava assando e parte do stress era por conta dessas interrupções.
Arquitetura é estratégia!
E se eu pudesse, hipoteticamente, ser proativo?
Ou e se de repente o problema parasse de acontecer, sem que ele sequer precisasse abrir um chamado?
Será que eu não teria clientes mais satisfeitos?
Será que não reduziria a pressão sob minha equipe?
Será que eu não conquistaria o sponsor assim?
Será que com uma simples adoção de uma ferramenta de centralização de logs, open source, gratuita, não seria possível alcançar isso?
E seu eu pudesse analisar um log, pudesse achar um erro, resolvê-lo, e se valesse a pena, ligasse para o cliente no dia seguinte avisando que o problema de ontem foi corrigido? Sem que ele precisasse comunicar que passou por um problema.
Sim, a resposta para todas as perguntas é: SIM!
Agora é hora de tangibilizar essa ideia.
O problema é que proatividade é algo subjetivo. Nós não somos proativos por natureza. Alguns de nós foram doutrinados para serem proativos, para tentar prever e tomar ações prévias. Outros não!
Assim eu concluí que precisava adicionar dados que pudessem correlacionar eventos de um sistema com os impactos no negócio. Simplesmente porque eu conseguiria mostrar um dashboard com nossos problemas. Eu transformaria proatividade em uma lista de tarefas. Algo humanamente mais fácil de ser solucionado. Nós adoramos listas.
Outro aspecto é trazer transparência para o negócio. Uma métrica importante para nós, nessa primeira implantação, era quantidade de músicas importadas. Por mês, por semana, por dia. O log de resultado de sucesso de um método específico da aplicação era suficiente para produzir esse número.
A quantidade de logs desse método, em produção, era a quantidade de músicas importadas. E eu conseguia determinar quanto tempo o processo levou.
Na segunda implantação que fiz, na Líder, como se tratava de uma restruturação de performance, saber evoluímos versão-a-versão era importante, portanto o log passou a levar consigo a versão da aplicação.
Isso permitia avaliar o tempo de processamento de um método por versão da aplicação. Bastava escolher um mesmo método para avaliar, agrupar por versão e entregar a média de tempo de processamento por versão.
Voltando à história
Eu já estava estudando sobre estruturação de logs e aparece a oportunidade de implantar o Sentry que se encaixou como uma luva. Uma ferramenta de Dashboard boa, uma linguagem para filtros, filtros pré estabelecidos, e a possibilidade de enviar qualquer tipo de dado estruturado para compor o log.
A implantação do sentry nos trouxe fôlego. Já era nítido ver como conseguíamos reagir mais rápido, no entanto apenas uma fração do parque usava-o.
Não levou muitos meses para ele começar a ficar lento, dar timeout e começar a virar gargalo.
Foi então que comecei a fazer testes com o Elastic.
Mas se você já chamou a API HTTP do elastic quando o índice está bem cheio, sabe que se você gravar o log junto com uma operação de negócio vai penalizar a performance do seu projeto. Você será penalizado pelo desenho síncrono e a alta latência da escrita no Elastic.
Não levou mais do que algumas semanas e um servidor bem ruim, para perceber isso.
Foi aí que eu trouxe o RabbitMQ que já estava no circuito por conta do resto do pipeline. É aqui que o RabbitMQ entra pela segunda vez.
A partir de então toda vez que eu coloco ELK Stack, minhas aplicações não falam diretamente com ele, minhas aplicações enviam os logs para o RabbitMQ.
Eu tiro o peso da aplicação de realizar a tarefa de chamada ao elastic, e ao mesmo tempo asseguro a tarefa será executada, diferente de apenas criar uma thread e enviar um request direto.
O LogStash tem o papel de tirar da fila e jogar para o Elastic, ele é parte do stack. Dessa forma, magicamente também removo a dependência do próprio Elastic. E eu tenho um método uniforme e independente do provider do Elastic.
A primeira implantação
Na primeira vez, a subida dessa infra foi assistida. Eu era praticamente cliente nesse processo. Quem fez isso foi o Fabiano Martinz, ele era cara mais próximo do Linux na empresa, era a primeira/segunda cabeça por traz da nossa infra na época. E sempre rolou um diálogo muito bom porque eu nunca tive apego algum.
Nunca me importou se o produto ou projeto era ou não feito sob a chancela do tio Bill.
É amplamente usado no mundo? Tem base sólida de usuários na comunidade Open Source? Se sim, tá valendo! Vamos estudar e entender.
A segunda implantação
Meu cliente seguinte estava um caos. O ano era 2015 e eles vinham de uma crise na hora de implantar um projeto em dezembro de 2014.
Passei entre 1 e 2 meses analisando código e não dava para chegar a uma conclusão definitiva.
Entenda, a experiência te ajuda a resolver problemas sem ver o projeto rodando. Basta olhar o código. Certas coisas são óbvias, outras não.
Nesse projeto não dava para achar claramente um código culpado, o projeto todo tinha questões que mereciam atenção, então era muito mais uma escolha por medir e priorizar.
Aqui eu não tinha acesso aos servidores. Eu precisava pedir acesso à minha gerente, que falava com o gerente do cliente que falava com o analista que agendava uma visita. Na visita abríamos o console do Windows Server, fazíamos umas queries por data e ele me mandava o arquivo de log.
Ao mesmo tempo havia uma pressão. Eu era novato no time, e estava com a incumbência de “salvar a pátria”. Eu odeio quando esse chapéu aparece!
Meu terceiro mês foi defendendo a criação do Enterprise Application Log. E meu argumento foi simples. Eu não consigo saber se está ok, ou até dizer que está melhor ou pior, sem conseguir medir.
Foi chato, tive de produzir uma documentação absurdamente chata, mas em algumas semanas o stack estava no ar nos ajudando a entender o que acontecia com a aplicação. Agora era hora de meter a mão na massa e comemorar cada milisegundo a menos!
Não foi difícil descobrir pontos com muitas exceptions.
E se você acha que a solução para as exceptions é removê-las, volte duas casas no entendimento da plataforma. A solução para as exceptions é entender porque elas estão sendo lançadas e fazer os tratamentos devidos para que isso não ocorra.
E se você pensou: Dá na mesma! Eu quero torcer teu pescoço!
Em linhas gerais, sobre exceções. Exceções são como prisões e cadeias. Você não elimina a prisão porque tem muita gente sendo presa, você faz com que os indivíduos parem de cometer crimes. Os que cometerem…
O princípio é o mesmo.
Também existiam alguns fluxos que eram chatos por diversos motivos. Hora pelo volume de dados, hora pelo ORM (EF) defasado, hora por configuração.
Como esse projeto não era um projeto produtivo, era um projeto em desenvolvimento, mas com muita pressão por se tratar de um projeto de consultoria onde a consultoria estava imersa dentro do cliente. Tudo ganhava proporções continentais.
Foi então que resolvemos instrumentar todas as 2 integrações e a maior parte dos fluxos web.
Isso permitiu argumentar com precisão sobre Quando, Onde havíamos recebido um dado e o que havíamos devolvido, por exemplo.
Isso foi um caos para o time do cliente. Antes dessa fase, o descrédito era grande e havia um jogo de empurra-empurra muito grande sobre problemas de integração.
Com o monitoramento preciso, ficou impossível dizer que não fez algo que de fato havia feito.
E essa maturidade ajudou os dois times.
Levou algumas muitas semanas, mas a discussão não começava com “Eu acho”, começava com “Por favor, altera isso porque eu esperava receber aquilo”. Isso ajudou a mostrar nossas próprias ineficiências. No final ajudou o cliente que era quem estava pagando a conta!
Dessa experiência algo que me recordo e que era incrível era que com um log completo e robusto, era possível fazer uns gráficos e filtros incríveis. E poderíamos também compartilhar os filtros. Boards específicos foram criados para nossa gerente de TI. A Luciana conseguia ter transparência sobre os erros que nossa equipe de teste produzia no papel de usuários, ao testar o sistema.
Tínhamos uma visão transparente para cliente, nós da consultoria, em todos os níveis.
Conseguíamos medir quantas propostas (não lembro qual era o nome do objeto) por dia com sucesso, com falha. Conseguíamos medir e entregar números como tempo de resposta por tipo de operação.
Para as exceptions tínhamos dados de negócio, que ajudavam a produzir a massa de dados identificar o problema de forma mais fácil.
Enterprise Application Log vs Application Insights
Essa comparação não é justa com nenhuma das duas soluções.
Ela só faz sentido se você colocá-los superficialmente juntos.
O que eu quero Mario Alberto?

Eu quero poder criar listas de tarefas com base no que afeta mais o negócio.
Eu quero compartilhar a mesma sensação de prioridade sobre aspectos técnicos que afetam o projeto.
Eu quero poder fazer um commit, esperar sua chegada em produção e ver uma métrica sendo alterada.
Eu quero poder abrir um board, ver um número ruim, e trabalhar em cima dele antes que meu cliente fique tão frustrado e puto ao ponto de abrir um chamado.
Eu quero poder tornar transparente o resultado dos esforços de arquitetura, performance.
Eu quero poder tornar transparente, com base em números, a ideia de que não precisamos fazer otimizações prematuras.

Eu quero poder discutir sobre objetivos que sejam mensurável.
Eu quero poder encontrar facilmente cenários específicos, onde o estado da aplicação é o único determinante para exceptions e problemas de performance. Como contas e perfis especiais em que só eles possuem problemas.
Eu quero ver gradativamente uma redução da quantidade de anomalias.
Eu quero entregara para minha gerente, meus clientes, boards que mostrem a progressão do nosso trabalho.
Eu quero poder correlacionar ganhos financeiros com a redução de bugs, maior estabilidade, ou ainda ganhos de performance.
Eu quero reduzir as interrupções por conta de bugs e problemas que poderiam ser corrigidos de forma proativa.
Eu quero poder valorizar o que não é funcional o que não é tangível aos olhos do usuário, mas continua sendo parte da nossa entrega.
Eu quero poder alertar e tornar transparente, o quanto uma decisão técnica ruim produz bugs.
Eu quero poder trabalhar sem a sensação de ser um bombeiro apagando incêndios.
Eu quero poder mostrar que dá para ser mais profissional.
E se os médicos contam com exames, nós contamos com uma boa estratégia de logs, aliada a uma “ferramenta qualquer” que dê suporte a ela.
O Enterprise Application Log é baseado no Elastic que por sua vez é capaz de lidar com estruturas dinâmicas de dados, em contrapartida o Kibana que é o visualizador, também sabe lidar bem com esse dinamismo. Eu consigo rodar essa infra no meu desktop, em servidores ou na nuvem. Em qualquer uma delas. Eu consigo entregar boards para diversos interessados, sejam eles técnicos ou não.
Só isso tudo!

0 comentários