
Você já deve ter visto que o RabbitMQ é usado para entregar resiliência, disponibilidade e confiabilidade.
Eu já mostrei isso algumas vezes nos últimos anos.
Talvez já tenha descoberto como pode reduzir a pressão de um volume intenso de trabalho sob seus sistemas, sua infra e seu banco, fazendo com que seja possível tolerar cargas de trabalho vezes maiores do que de fato seu parque consegue tolerar, sem precisar escalar seus sistemas.
Mas afinal, e se o RabbitMQ falhar? O que acontece? Como lidar com isso caso aconteça? Como contornar?
Essa série de posts RabbitMQ Clustering – Publish & Consumer Recovery aborda a criação de clusters, seus principais comportamentos e como aplicações .NET podem se recuperar de falhas com pouco ou nenhum esforço.
Usamos Docker e Docker Compose em exemplos de código que são feitos com C# e .NET 7. Divirta-se.
É comum delegarmos muitas responsabilidades vitais dos nossos sistemas para o RabbitMQ.
A ideia de ter um portador confiável para nossas mensagens, é incrível.
Alguém para assegurar que mesmo em caso de queda dos sistemas, dos bancos, ele vai cuidar e salvaguardar nossas mensagens até que os envolvidos voltem a operar.
Quando você tem soluções dessa natureza em seu parque, você pode usá-lo para diversas finalidades.
Em busca de Disponibilidade
O segredo da alta disponibilidade é estar disponível até quando não se está disponível. Confuso?
Imagine que você é um sistema de pagamentos, que por ventura caiu. Mas continua recebendo mensagens, e enfileirando e acumulando mensagens na fila, enquanto está fora do ar.
Do ponto de vista de quem precisa enviar ordens de pagamento, seu sistema não está de fato offline. Embora dentro da sua infra, da porta pra dentro, esteja. Mesmo que momentaneamente.
Imagine que a demanda é realizar um deploy. Implantar uma nova versão urgente, porque um bug foi identificado. Mas esse bug afeta apenas uma fração dos seus clientes.
Em um cenário sem mensageria, você teria dificuldade e usaria outras técnicas de engenharia para contornar isso.
Imagine que esse bug para ser corrigido demanda a alteração uma tabela em um banco de dados. Aí suas estratégias sem mensageria vão ficando cada vez mais escassas.
Em algum momento vai dar tanto trabalho, que ou você abraça a indisponibilidade e fica de fato indisponível, ou você começa a acumular alterações para realizar em janelas de tempo muito específicas.
Tudo isso atrasa o negócio.
Em busca de Resiliência
Imagine que do outro lado, consumindo esse sistema de pagamentos que não usa mensageria, tem você e seu sistema que precisa enviar ordens de pagamento.
Imagina qualquer indisponibilidade do serviço de pagamento, faz o seu sistema quebrar.
Com mensageria, enquanto não conseguir de fato enviar a ordem de pagamento, a mensagem continua em uma fila.
No mundo perfeito, ambos, cliente do pagamento e serviço de pagamento, usam mensageria dentro das suas fronteiras.
Na prática, há muitos casos assim.
Mas o que queremos, nesse cenário, é que uma dependência, interna ou externa, não afete nossas aplicações. Mesmo que a comunicação nossa para com esse serviço seja via HTTP ou outro protocolo qualquer.
Queremos paz para lidar com essas cargas de trabalho.
Em busca de Confiabilidade
Se aumentamos a resiliência e a disponibilidade, automaticamente estamos criando um sistema mais confiável. Mas, além disso, podemos trabalhar com logs, métricas, e outras coisas importantes que podem facilitadas depois que você já tem uma solução de mensageria no seu projeto.
É possível fazer com que uma mesma mensagem vá para um consumidor que trabalhe com ela, e outro que armazene, criando um meio de auditar tudo que chegou ou que saiu.
Tudo isso contribui para um projeto que esboça e esbanja confiabilidade.
Em busca de Eficiência
Imagine por um instante que você tenha um sistema responsável pelos pagamentos de um pequeno e-commerce. Esse e-commerce possui demanda moderada. Nada muito absurdo, mesmo nas datas quentes como Black Friday, dia dos pais, dia das mães, Dia dos Namorados ou Natal.
Imagine que sem nenhum aviso, o menino Neymar faz um story no Instagram, falando de um produto dessa loja.
Em minutos, centenas de milhares de acessos no site, e naturalmente milhares de pedidos e pagamentos precisam ser processados nesse período.
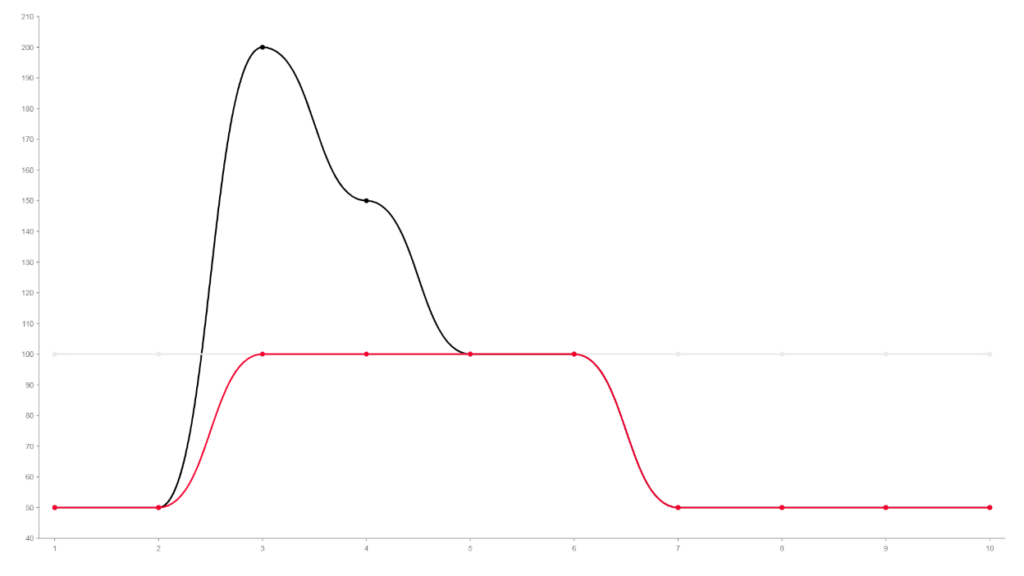
Fiz o gráfico para demonstrar o que seria o comportamento normal de uma aplicação.
A linha cinza, fixa em 100, demonstra o limite de capacidade de uma API.
Em vermelho temos a aplicação escalando e aumentando seu throughput até o limite. Mas o volume, ou seja a carga de trabalho é muito maior do que o máximo suportado por essa API.
Como foi uma divulgação espontânea, e não uma campanha de marketing, nada foi nada planejado, naturalmente você não esperava esse aumento repentino no consumo da API.
Vamos supor que esse limite de 100 seja com o autoscalling da API, mas respeitando os limites de um banco de dados e outras API’s que seu sistema use.
Talvez, pela demanda normal, sequer tenha habilitado, ou mesmo contratado um plano que permitisse escala.
Vamos dar uma colher de chá,
Mesmo escalando APi, nesse caso, seu limite é o quanto essa API ofende o resto da infraestrutura. Banco, api’s que a api principal consome, um serviço de uma operadora de cartão que tenha throttling, por exemplo.
O problema é que inevitavelmente, quanto mais complexo for esse ambiente, maiores são as limitações.
Se você escalar a API com a missão de processar tudo instantaneamente, de forma síncrona, terá inevitavelmente de propagar a decisão de escalar sua infra.
Aplicação, banco, serviços de terceiros. Isso pode incluir contratar planos de serviço muito maiores. Tudo para atender a um pico de processamento, sendo esse esporádico.
Nesse cenário, tudo que acontecer acima do limite, 100, é request não processado e descartado. Portanto, faz sentido habilitar o autoscale e gastar a grana a mais para escalar para não ter pagamento sendo recusado por falta de hardware. Isso envolver escalar o que for necessário.
Esse é o preço de processar tudo de forma síncrona.
O sincronismo exige processamento imediato.
Abaixo mostro um outro exemplo.
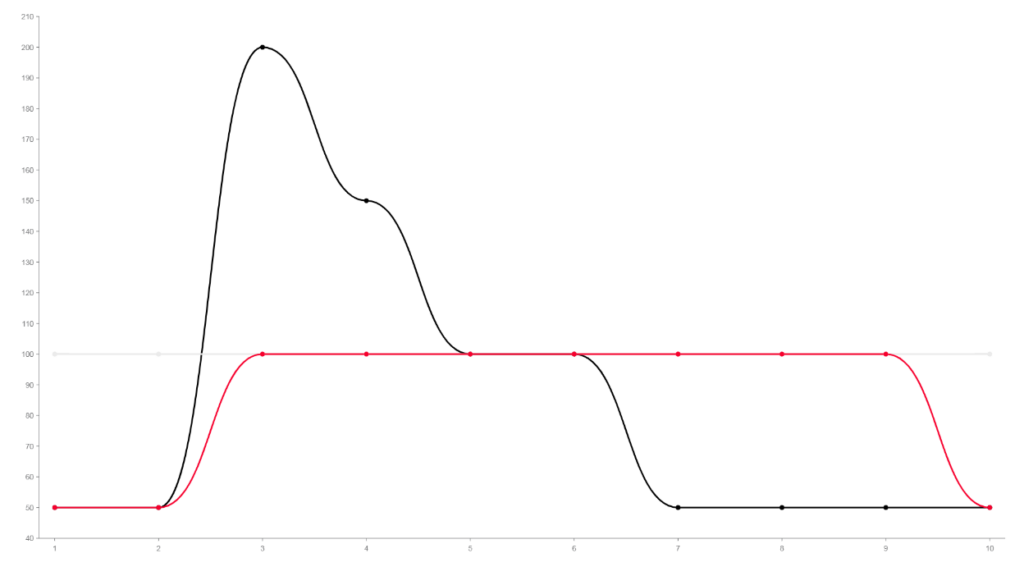
Com mensageria, supondo a mesma carga de trabalho, teríamos esse comportamento acima.
Com o mesmo workload, não precisaríamos escalar além do limite. Se 100 é o limite perfeito, podemos não ultrapassar esse limite, sem perder nem negar nenhuma mensagem.
A linha em vermelho mostra a aplicação continuando próximo à 100, mesmo depois que o workload já voltou a patamares normais.
Esse é o comportamento quando você acumula mensagem em uma fila. Entre o momento 7, a carga de trabalho voltou ao normal, e nossa aplicação continuou consumindo mensagens da fila, já que durante os momentos 2 a 5, houve foi produzido um acúmulo.
Eu demonstrei isso nesse video abaixo.
Em busca da escalabilidade
Eu particularmente não gosto muito de abordar escalabilidade aqui do lado de fora exatamente pelo motivo do exemplo anterior.
A escalabilidade demanda que todo o resto do parque seja compatível com a escala.
Não adianta escalar seus consumidores para 100 consumidores se seu banco não suporta o throughput produzido por esses 100 consumidores.
Claro que RabbitMQ é super indicado para escala, mas só uma fração das aplicações possuem de fato demandas de escala.
Escala é um jogo para quem tem dinheiro e quer ser capaz de aumentar seu throughput.
Entretanto, todos os benefícios que citei antes, são facilmente adicionados a qualquer tamanho de aplicação e qualquer tipo de restrição orçamentária.
Aliás, esse é um dos motivos de não aconselhar Kafka. Falar de Kafka em aplicações pequenas é uma insanidade, mas falar de RabbitMQ para essas mesmas aplicações, não.
Embora RabbitMQ demande cuidados, atenção e conhecimento específico, principalmente do desenvolvedor, ele é versátil e permite os mais variados tipos de deployment.
É tranquilo e indolor, e vai trazer mais economias, em vez de custos.
Clustering
Já que entregamos essas responsabilidades para o RabbitMQ é importante entender qual o tamanho ideal de um cluster e até saber se vamos adotar um cluster ou não.
Há mais ou menos 5 anos eu criei uma forma super fácil de avaliar qual é o desenho ideal para sua implantação de RabbitMQ.
ESPELHE-SE EM SEU BANCO DE DADOS
Se seu banco de dados não está em cluster, não inventa!
Seu RabbitMQ não deve ser implantado como um cluster!
Se seu banco de dados está em cluster, esses posts ajudarão você a entender a quantidade de nós, tamanho e cuidados para subir seu cluster.
Isso mesmo.
Se seu banco de dados possui 1 única instância, seu RabbitMQ deve seguir também um deploy single node, sem cluster.
Mas Gago, isso é errado?
Seu banco de dados com 1 única instância é certo?
Ahh, mas você está justificando um erro com outro!
Não, estou afirmando categoricamente que você está em um projeto com uma infraestrutura amadora, portanto, sua implantação de RabbitMQ deve seguir o amadorismo que já é praticado em relação ao seu banco de dados, porque você provavelmente não tem um time maduro para sequer compreender ou justificar a criação de um cluster.
RabbitMQ não é mais importante que seu banco de dados, e portanto se seu banco não tem um cluster, está claro que sua empresa não é uma empresa em que você deveria se preocupar com isso no RabbitMQ. O preço é trazer complexidade e custo para o RabbitMQ como se colocasse uma cereja em um bolo de bosta.

Já se seu ambiente é um ambiente profissional onde seu banco é parte de um cluster com HA.
É irresponsabilidade não adotar HA no RabbitMQ nesse contexto.
Essa série é para você que está em uma empresa cujo banco possui HA, e então RabbitMQ deve ser implantado seguindo as mesmas regras de disponibilidade.






0 comentários